
Hello World: Build a Serverless App With the First Serverless Database
Fauna is the first truly serverless database. In this post, I’ll use the Serverless Framework to connect an AWS Lambda application with Fauna Serverless Cloud.
When I say serverless, I’m referring to the function-as-a-service pattern. A serverless system must scale dynamically per request, and not require any capacity planning or provisioning. For instance, you can connect to Fauna in moments, and scale seamlessly from prototype to runaway hit.
A serverless system must scale dynamically per request.
Current popular cloud databases do not support this level of elasticity—you have to pay for capacity you don’t use. Additionally, they often lack support for joins, indexes, authentication, and other capabilities necessary to build a rich application.
What is Fauna?
Fauna Serverless Cloud is a globally distributed database that requires no provisioning. Capacity is metered and available on-demand—you only pay for what you use.
Fauna is a globally distributed database that requires no provisioning—you only pay for what you use.
Fauna is a perfect fit for serverless development. Let’s code.
Getting Started with Serverless Framework
Serverless is leading the serverless framework market right now with a clean system for configuring, writing, and deploying serverless application code to different cloud infrastructure providers. I took an afternoon to port one of their storage examples from DynamoDB to Fauna. It was incredibly easy to accomplish. Looking through this code will show us how simple it is to set up a serverless environment.
The CRUD service I am porting is a simple REST API that allows the creation, updating, and deletion of todo items, as well as listing all todo times. It’s a toy example, so after we look through the code, I’ll describe how you’d go about adding a multi-list multi-user data model where users can invite other members to read and update todo lists. It would be a lot more productive to push that logic to Fauna, but in this example I am limited by the capabilities DynamoDB also provides.
The README contains installation and usage instructions, and you can go here to get instant access to Fauna.
Once you have this set up running, you can play around with Fauna’s more interesting features, like implementing a social graph. Check out this social graph tutorial.
Defining the Functions
The first file to start reading any app using the Serverless Framework is serverless.yml which defines the service and links functions to event handlers.
readAll Example
In ours we can see the function definitions; here’s one of them:
functions:
readAll:
handler: handler.readAll
events:
- http:
path: todos
method: get
cors: trueThis configuration means the
readAll function in handler.js will be called when an HTTP GET is received at the todos path. If you look through the configuration you’ll see all the functions are linked to handler.js, so that’s where I’ll look next.module.exports.readAll = (event, context, callback) => {
todosReadAll(event, (error, result) => {
const response = {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin" : "*"
},
body: JSON.stringify(result),
};
context.succeed(response);
});
};Everything in
handler.js is concerned with managing HTTP, so the actual logic is imported from a module for each function. In this case, todos-read-all.js. We’ll include the entire file here because this is the place Fauna comes into play.'use strict';
const faunadb = require('faunadb');
const q = faunadb.query;
const client = new faunadb.Client({
secret: process.env.FAUNADB_SECRET
});
module.exports = (event, callback) => {
return client.query(q.Paginate(q.Match(q.Ref("indexes/all_todos"))))
.then((response) => {
callback(false, response);
}).catch((error) => {
callback(error)
})
};In this case I’ll run a query for all todos, using a Fauna secret passed via configuration in
serverless.yml. Fauna uses HTTP for queries so you don’t need to worry about sharing connections between modules or invocations.Differences Between Fauna and DynamoDB Interfaces
The main difference between the DynamoDB and the Fauna versions is that this:
return dynamoDb.scan({TableName: 'todos'}, (error, data) => { … })becomes:
return client.query(q.Paginate(q.Match(q.Ref("indexes/all_todos"))))Try It Out
Follow the README instructions to launch and run the service, then create a few todo items.
Now you’re ready to explore your data and experiment with queries in the Fauna dashboard. Open the dashboard via this sign up form. It will look something like this:
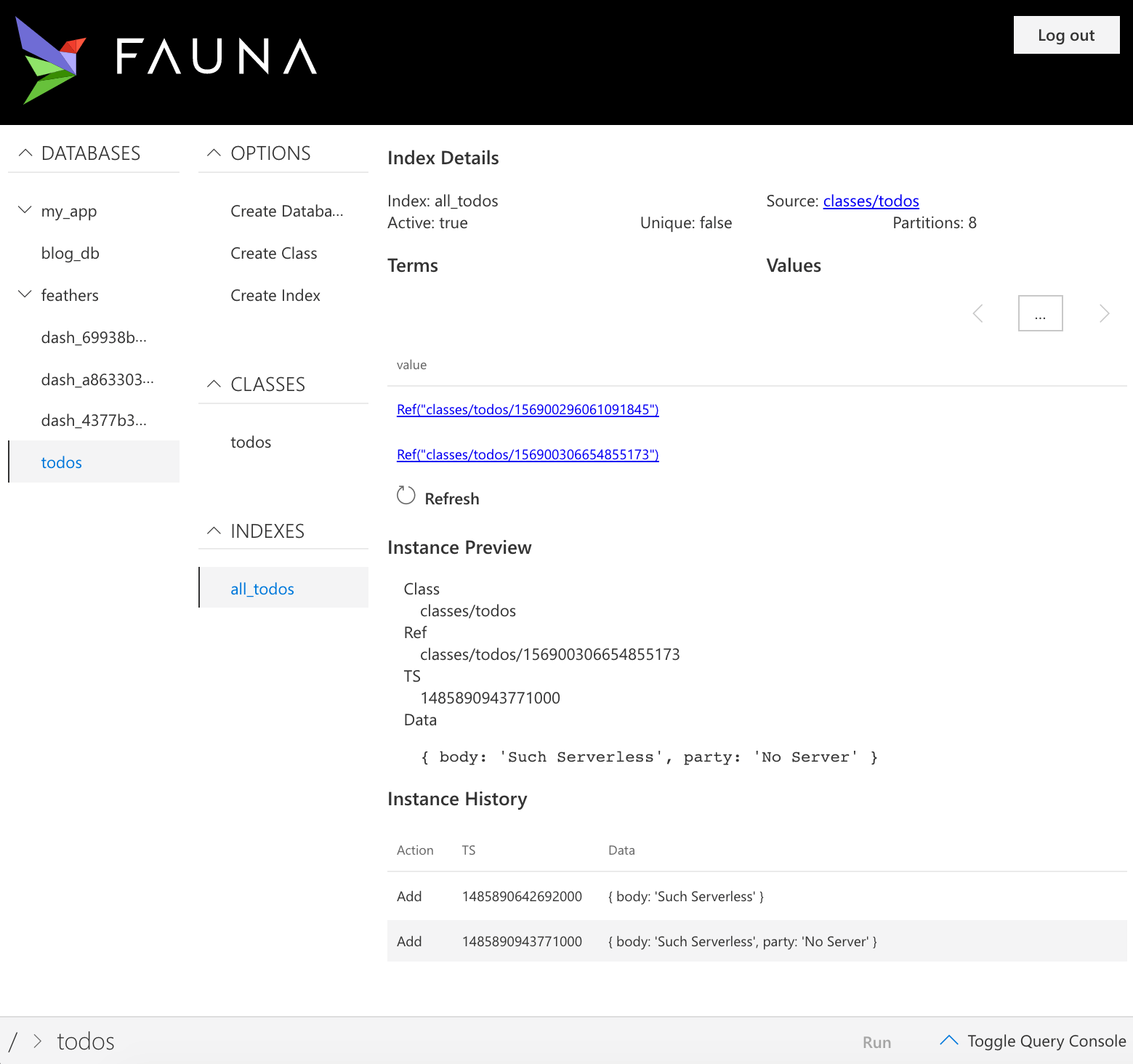
If you look closely at the screenshot you get a hint at Fauna’s temporal capabilities which can power everything from social activity feeds, to auditing, to mobile sync.
Moving Beyond a Demo
In a production-worthy version of this application, the request would contain a list ID, and our query would validate that the list is visible to the user, before returning just the matching items. This security model is similar to collaboration apps you may be familiar with, and it’s supported natively by Fauna.
The source DynamoDB example lists all todos using a
scan operation. To move to a secure list sharing model in DynamoDB, you would have to add an index and then run multiple queries from your serverless handler to validate that the list is visible to the requesting user.Conclusion
As I build more examples using a serverless architecture, I’ll choose the Serverless.com framework again. You can look forward to an example of serverless code dynamically provisioning resource using FauanDB’s multi-tenant QoS features, and how to integrate Fauna with other serverless components.
Over time, which do you think provides better agility: a database that requires rethinking your data layout when requirements change, and implementing big pieces of policy in application code—or a database with flexible queries and security awareness? I hope you agree that the answer is Fauna.
If you enjoyed our blog, and want to work on systems and challenges related to globally distributed systems, and serverless databases, Fauna is hiring!
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.