

Building the next generation search engine with Fauna and Cloudflare Workers
Introduction
At MeetKai we’re building a next-gen Voice Assistant, powered by our in house next-gen search engine. A next-gen voice assistant has to be multilingual, capable of carrying out multiple turns of dialogue, and have a deep understanding of what a user is exactly asking for rather than just searching by keywords. A next-gen search engine requires a fundamental shift of mindset; instead of indexing the web as a collection of pages, you need to index both apps and the web as a graph of interconnected items. Doing one of the two entails an extreme amount of engineering and R&D (Research & Development), doing both only compounds the challenges.
It turns out, building the former requires the latter. That’s why we have to be much smarter about how we approach our architecture as a company. If we only did things the _standard _way, then we could never compete with the elephants who’ve been doing it longer. That’s how we see the combination of Fauna and Cloudflare Workers as a secret weapon in staying ahead, and built our v2 search architecture with a serverless first mentality.
Business case
A core feature of one of the user-facing products we’re releasing this summer would not exist without this combination of tools. This product will be required to display a top 10 of suggested searches, for each user to make to our search engine. In the old days, a user would be fine with seeing perhaps 10 generic context-free suggestions like “sports” or “action movies”. Today, users expect personalization in everything they do. The searches we suggest are based on personalization across a few dimensions: region, device, time of day, location, and most importantly… the user’s profile. This allows a transformation from generic suggestions with a low engagement, to highly relevant with a high click-through rate.
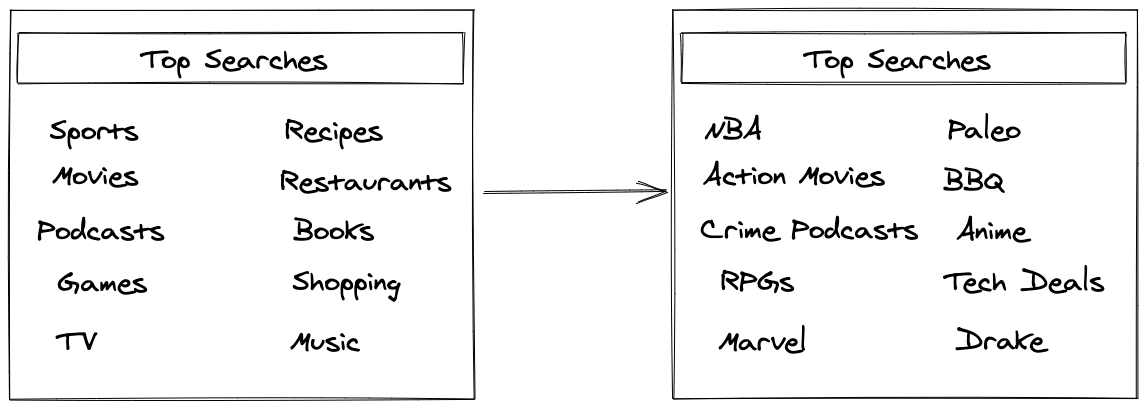
When a user clicks on one of the suggested searches, they’re brought to a results page within one of our native apps, quick apps, or H5 pages depending on the platform. A critical part of this “click-through” is being able to feed back interactions to improve future personalization. There are a number of signals that we track in order to build up a personalization profile for a user, some examples are: what search was clicked, which weren’t clicked, how long it took them to decide which to click, how long did they stay on the results page, and many other forms of implicit and explicit feedback. These interactions are later aggregated and used to train a model to generate the personalization factors for a user.
Architecture
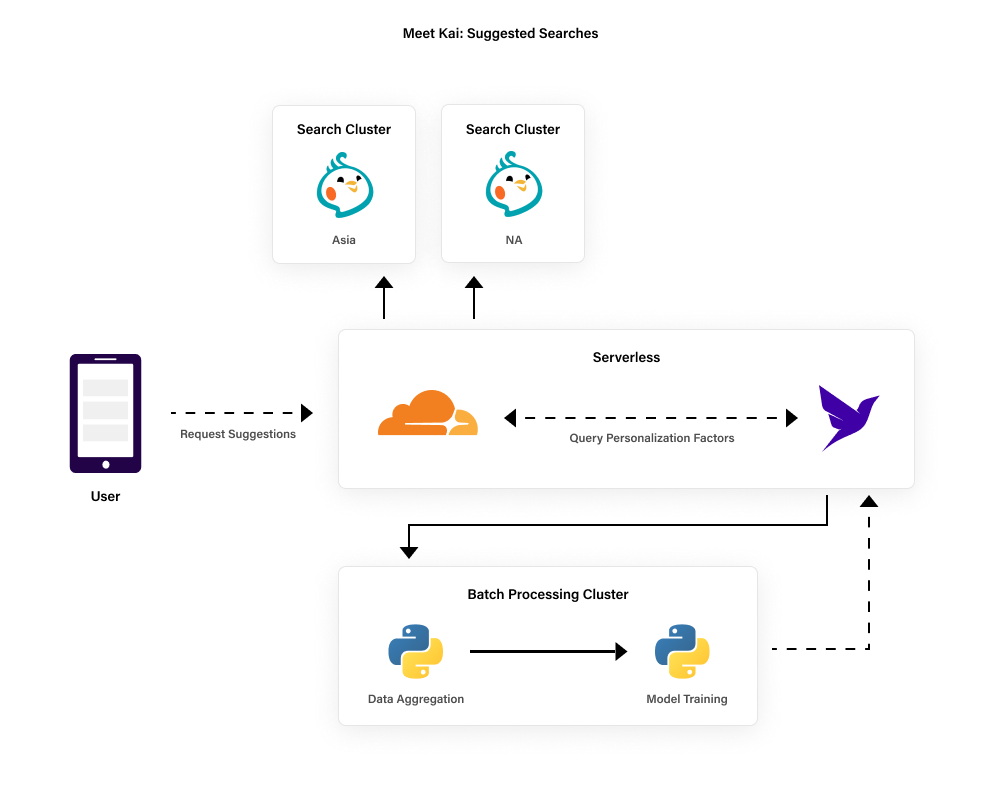
Our architecture for this feature was developed to separate concerns as much as possible, to allow us to scale rapidly, minimize latency, and reduce costs. Our core search clusters operate in data centers in North America and Asia Pacific, with a planned expansion next quarter into an EU data center. Our batch processing cluster is run in multiple clouds with a split between data aggregation nodes and model training nodes (powered by NVIDIA gpus). Both the batch and search clusters are auto scaling k8s clusters that make heavy use of spot instances, allowing us to be agile with demand without overspending on committed instances. Our batch cluster executes at times when GPU costs are lowest in the spot instance market, so it cannot directly host a database -- it could be shut down at any time in the middle of a job if prices move up too much. Likewise, our search cluster is optimized to be extremely resilient for storing search documents. However, it makes a number of assumptions on read/write work loads.
While this cloud native architecture enables us as a startup to punch far above our weight, it does require that we be very clever in how these highly dynamic clusters are connected to our users. We also need to be very cautious about scenarios where we’re writing user data we want to make sure gets committed.
Cloudflare Workers act as the proxy to all downstream requests. Doing so, enables us to perform a much smarter load balancing at the edge, using the worker rather than some other competing solutions. But that is only the beginning of the benefit we get from workers. The real magic happens when you introduce Fauna into the mix; by pushing data to the edge as well, we’re able to inject personalization information before a request ever hits our backend.
Injecting personalization
In order to break the sequence diagram down, the most important concept to understand is the personalization factors. Personalization factors are computed ahead of time in batch and designed to be used by downstream services that need to personalize a query to a specific user. While the implementation details of what these factors look like is out of scope for this post, a very simplified example would be a document like this:
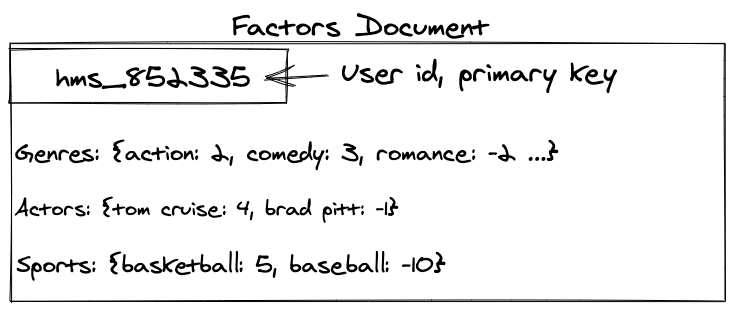
While this may be somewhat oversimplified relative to the actual implementation, this type of document would still allow downstream results to be reranked for a particular user, perhaps by boosting a score based on if the result item has any of the positive interaction scores, and reducing the score if it has a negative interaction score.
With this in mind, the first phase of our architecture is where we implement the concept of “injecting” personalization into a request before it hits our backend.
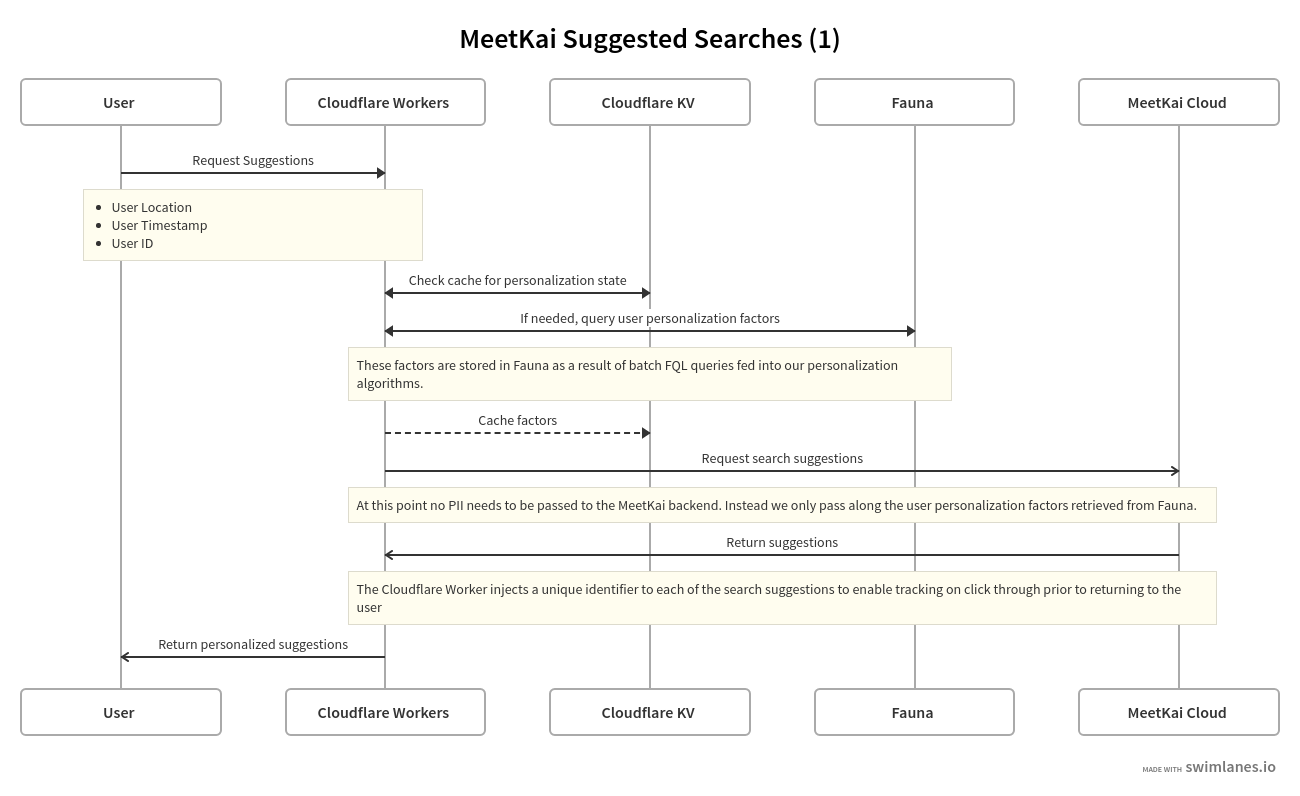
When a user makes a request for 10 suggested searches a POST is sent to our Cloudflare worker, as a part of the request we include the user’s location, timestamp, and most importantly their user ID. At this point the user ID is used by the Cloudflare worker to query the latest Personalization Factors document. We first check Cloudflare KV to see if we have one recently, for example if they just asked for 10 other suggestions. If there is no recently cached document available at the edge, we query our Fauna collection using the user ID as our index key to find the most recently computed factor’s document and then store it in Cloudflare KV. At this stage, the worker has all of the information it needs to make a request to our backend without passing along the uniquely identifying user ID! Furthermore, with this architecture we have completely separated concerns between the edge worker and our backend by allowing our backend to only need to utilize the pre-computed factors rather than having to query a datastore and cache directly.
Tracking, analytics, and batch processing
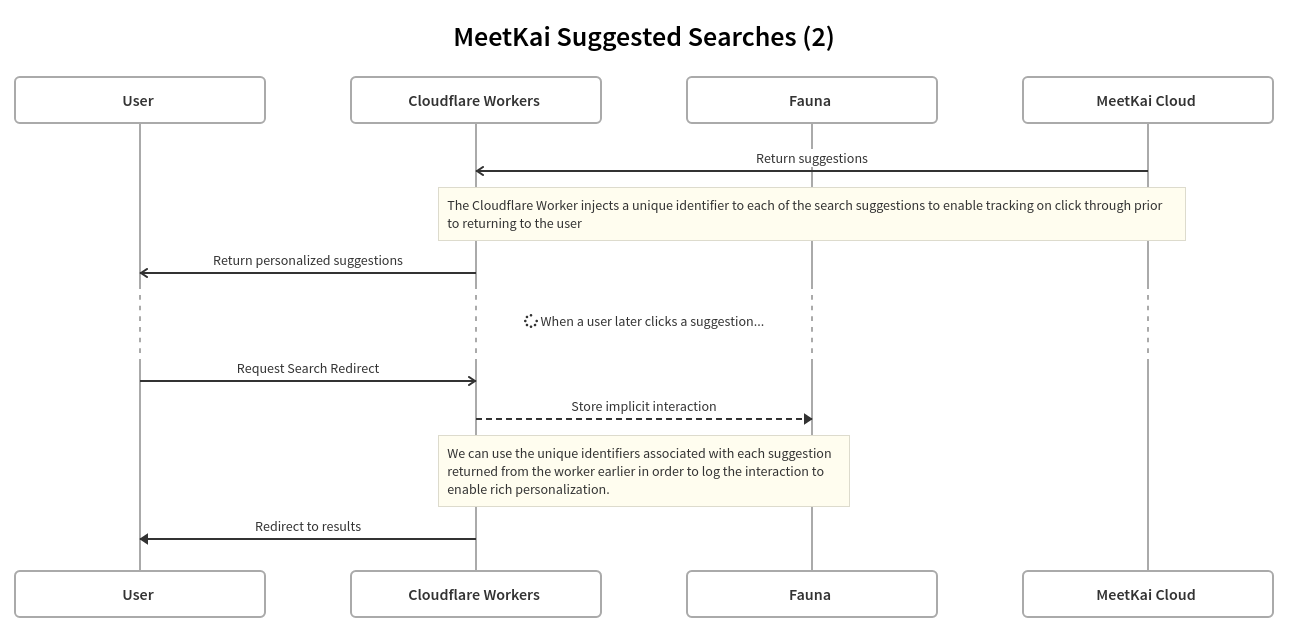
After the suggestions are returned from our MeetKai cloud to the Cloudflare Worker, we create a document in Fauna that corresponds to the session, this document is composed of a unique identifier, the user ID, and the result ID of each of the suggested searches. The links themselves to each of the suggestions have the session ID appended to them as a query string parameter. When a user clicks on any of the suggestions they are routed first through the Cloudflare Worker. The Worker queries the search session document from fauna using the session parameter, and then updates fauna with a positive interaction that looks a little like this:
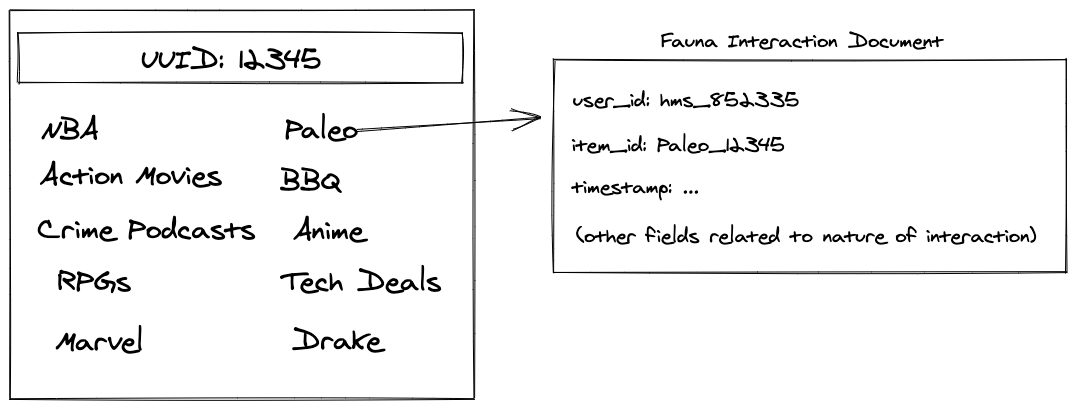
Fauna storing of user interactions is the key to actually build the personalization vectors. In a batch processing cluster, we periodically query Fauna with a number of rollup queries to create a training dataset for a personalization model. This personalization model is trained and then used to generate a new personalization document for each active user. We then batch load these into Fauna to enable the Cloudflare worker to quickly retrieve the most recent document directly at the edge.
Conclusion
We aim to build out more services that exploit this same architecture, where Fauna is used to bridge the gap between serverless workers and compute heavy batch processing applications. By using Fauna as a core datastore to connect different cloud native services we are able to get around one of the biggest challenges on auto scaling workloads, persistence. Furthermore, Cloudflare Workers are a more stable, lightweight, and frankly capable, edge code solution compared to oversized API Gateways. By being able to use completely off the shelf solutions like Cloudflare and Fauna rather than either bespoke or opaquely priced solutions, we are able to get to market faster and with predictable costs and performance.
This is just one of the ways in which we plan to stay ahead, and the type of commitment it takes to develop technologies and features that we’re truly proud of. Not to just stand out in the market, but to redefine it. Some other ways? We currently offer multi-turn technology that allows Kai to remember contexts and be able to follow up user questions. Kai can also answer negation questions and offer personalized results across multiple domains, in more than 13 languages. This multi-turn technology is only possible through the implementation of architectural choices to maximize developer productivity and have R&D focus on the core competences of our business. Companies that outsource key components of their architecture have to be cautious that it doesn’t become a liability, with our architecture it is really a risk free investment, not technical debt that needs to be solved later.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.