
Building scalable dApps with Ethereum, Polygon and Fauna
Introduction to dApps
DApps are decentralized applications that run on peer-to-peer (P2P) networks like blockchains. The decentralized nature means that no one entity (including a person) has control of the network and is perfect for use cases where multiple untrusted or anonymous parties need to transact.
DApps existed before blockchain with P2P apps like BitTorrent, but today there is a whole new ecosystem of dApps that leverage blockchains, which guarantee auditability and immutability of transactions. These applications provide a range of solutions, from anonymously offering financial services to providing creators a way to earn money through NFTs and other technologies.
As blockchain technology evolves, new application patterns have emerged for partitioning dApps data to improve performance while reducing costs. In this post, we illustrate how you can combine Ethereum, Polygon, and Fauna to release dApps that are secure and performant.
Before we move on, let's clear up some definitions:
- On-chain or L1 chain - The primary, public blockchain. When a new transaction occurs on-chain, the transaction is added directly to the blockchain. Example: Ethereum.
- Sidechains and L2 chains - Secondary blockchain or protocol implementations that can interface with each other and with the primary chain. Every so often they submit an aggregation of their recent blocks back to the primary chain. Example: Polygon, Optimistic Rollups, zkRollups.
- Off-chain data - Data that is stored outside the primary and secondary blockchains, but is important to the functionality of the dApp. Examples: Private wallet addresses, user profiles, application data.
Application pattern for scaling dApps
Ethereum provides dApps with the core blockchain infrastructure necessary for recording decentralized transactions. However, with the growth in Ethereum usage, the cost and latency incurred to add a block to Ethereum have increased.
To achieve high throughput and low expenses in their data architecture, dApps minimize the need to read or directly write to Ethereum with sidechains, off-chain databases, and index accelerators. Polygon is emerging as a popular sidechain solution for developers providing a modular, flexible framework that enables dApps to interact with L1 chains like Ethereum, alongside L2 chains like Optimistic Rollups, zkRollups, and more, using a single SDK.
To make reads from the chain more performant in this architecture, dApps leverage off-chain index accelerators like The Graph to query sidechains or Ethereum. The Graph indexes blockchain data so when dApps are referring to on-chain data in their application logic, they can maintain low latency.
The third part of this data architecture is off-chain data, which is critical to the operational aspects of an application and is typically composed of information that is not published to the blockchain for privacy and performance reasons. An example for the privacy category is a user’s wallet address. On the performance side, off-chain data can include read-heavy operational data required by the application.
The following diagram illustrates how sidechains and off-chain databases work together with primary chains to realize this architectural pattern in dApps. Consider an eSports dApp that is hosted on Polygon (for high throughput and low cost) and rewards the winner with a digital token. The user logs into the dApp, which uses its off-chain database to ensure the user exists and finds the user’s wallet address. The dApp can then query the Polygon chain via The Graph (to speed up reads) with the user’s wallet address, and retrieves data like NFTs the user owns, all previous games and rewards won, etc. Finally, if the user wins a game, the dApp persists the user’s reward on the polygon chain. L2 chains like Polygon use a mechanism known as checkpointing to commit a digest of a sequence of blocks on the L1 chain. L1 chains like ethereum offer higher security which is one of the main reasons L2 chains use ethereum for checkpointing.
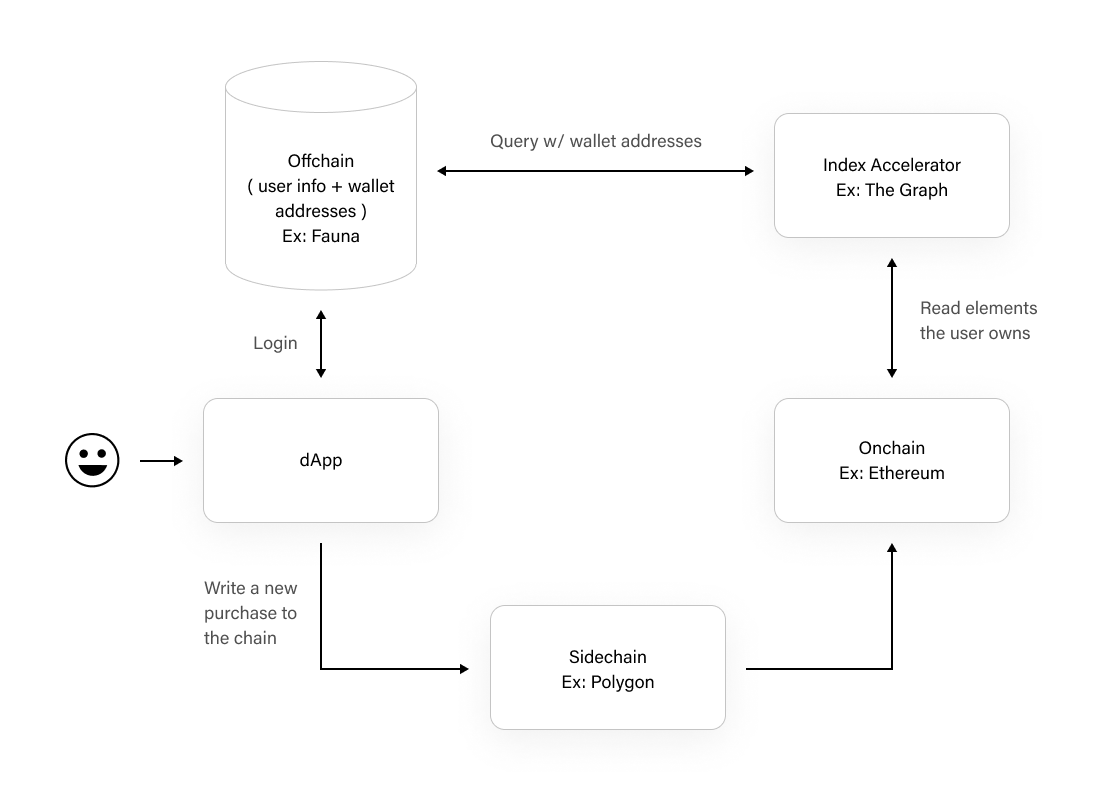
It is worth noting that some off-chain data could be stored on a blockchain directly, but often this class of data is better suited for an OLTP database due to performance, privacy, and cost concerns associated with using blockchains directly for data that does not need to be part of the publicly auditable, verifiable blocks. OLTP Databases can be paired with blockchains to securely store user information and metadata, like wallet addresses, with low latency and low cost. DApps usually also do not use blockchains to store user information because it would then be public. If they stored this information as a part of their block transactions, anyone could look at a block and determine the identity and private details of the dApp user who conducted the transaction.
Key Database Requirements for Off-chain Data in dApps
Building modern dApps teams requires the primary chain, off-chain index accelerator, sidechain, and off-chain data to be interoperable and integrated. In this architectural pattern, it becomes important for the off-chain database to provide fine-grained data security, an ecosystem-friendly query interface, and multivariable (aka composite) indexing to enable faster, more efficient queries.
Fine-grained Data Security
DApps must achieve high security and reliability across their data storage systems and avoid exposing private data in all chains and databases. Attribute-based access control (ABAC) in databases can enable dApp teams to have confidence that they can store sensitive user information like wallet addresses securely alongside the rest of their application data.
Multi-variable Indexing
To remain efficient, dApps must be able to query the system for exactly the data that they need, and do so with the least possible latency. Off-chain data structures are complex, especially because of the need to ensure anonymity and auditability. Composite or compound indexing can span and transform multiple values in the underlying data and mitigate the impact of datacomplexity on query performance, especially on latency..
Fauna for Off-chain Data
Fauna is a document-relational database delivered as an API. It empowers developers with the essential capabilities required to build reliable and scalable off-chain storage for dApps and offers a host of capabilities that make your database experience more productive, powerful, and scalable, allowing you to ship apps faster.
Attribute-based Access Control (ABAC)
Fauna enables dApps to match organizational hierarchy by assigning roles to users so only certain team members can access and change data. This reduces the chances of security breachs. Privileges can be dynamically determined based on user attributes, the documents to be accessed or modified, or context during a transaction (for example, time of day).
Advanced Indexing
Fauna provides powerful indexing capabilities that improve the performance of searching, sorting, and combining results from multiple tables/collections. This ensures that users of dApps aren’t hit with high latency from their off-chain databases when querying between on-chain and off-chain data. This is particularly important when building latency-sensitive experiences like an NFT marketplace or an eSports hub.
Distributed database that guarantees consistency
Databases in Fauna are inherently distributed and automatically scale either within a specific region (like the EU) or globally. Additionally, Fauna is strictly serializable, guaranteeing transactional correctness and read-your-own-writes behavior from any location. Fauna uses a built-in distributed, temporal consensus algorithm, ensuring that your off-chain data is always consistent.
Track and trace capability
One of blockchains main features is the ability to audit transactions using a public ledger using explorers. Fauna’s temporality, similar to the track and trace capabilities of Blockchains, enables point-in-time querying so you can look back and see exactly how data has changed. This enables dApps to have auditability not only on their on-chain blocks, but also their off-chain data.
Build your off-chain databases in Fauna
Fauna complements the capabilities of your on-chain and sidechain data by delivering a secure, performant, and interoperable off-chain database. Fauna eliminates scaling, provisioning, sharding and other operationally intensive tasks so your teams can focus on the dApp.
Innovators like Acoer use Fauna alongside blockchains, Polygon, and TheGraph to innovate relentlessly and quickly push new ideas to production. DIGITALAX’s dApp leverages Fauna as its off-chain database with the architecture we described: Ethereum for on-chain, Polygon for its sidechain and The Graph as an index accelerator.
“Once we realized there were off-chain data components to our architecture, Fauna just made the most sense. It really allowed us to have flexibility and scalability for supporting us as a startup today and enables us to continue to grow.” - Emma-Jane MacKinnon-Lee, CEO, DIGITALAX
Fauna is easy to use and quick to get started. Sign up for our forever free pricing plan to explore all the capabilities and start building! If you want to discuss your use case with us or need more assistance, please reach out to us using this contact form. We’re excited to see what problems you solve for your customers and partner with you in your journey!
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.