
Building a Serverless JAMStack app with Fauna: Part 2
In my experience with enterprise application development, the pattern I’ll illustrate in this series fits a wide range of collaborative apps. Most apps have some form of login, and once users are identified, they’re able to participate in a particular set of shared workspaces, depending on who they are. For example, players and coaches can collaborate with each other on game plans in one workspace, while coaches make roster decisions in a separate workspace only they can access. This same pattern repeats itself across application domains, from photo sharing to options trading.
The previous post was about where we are today in the development process of an example application template. With one click, the grunt work of your new application is done, and your valuable domain-specific code ready to write.
The end result is an application template embodying best practices, like React hooks and Netlify Identity for user management, that offers user-level, role-based data access control with minimal development effort.
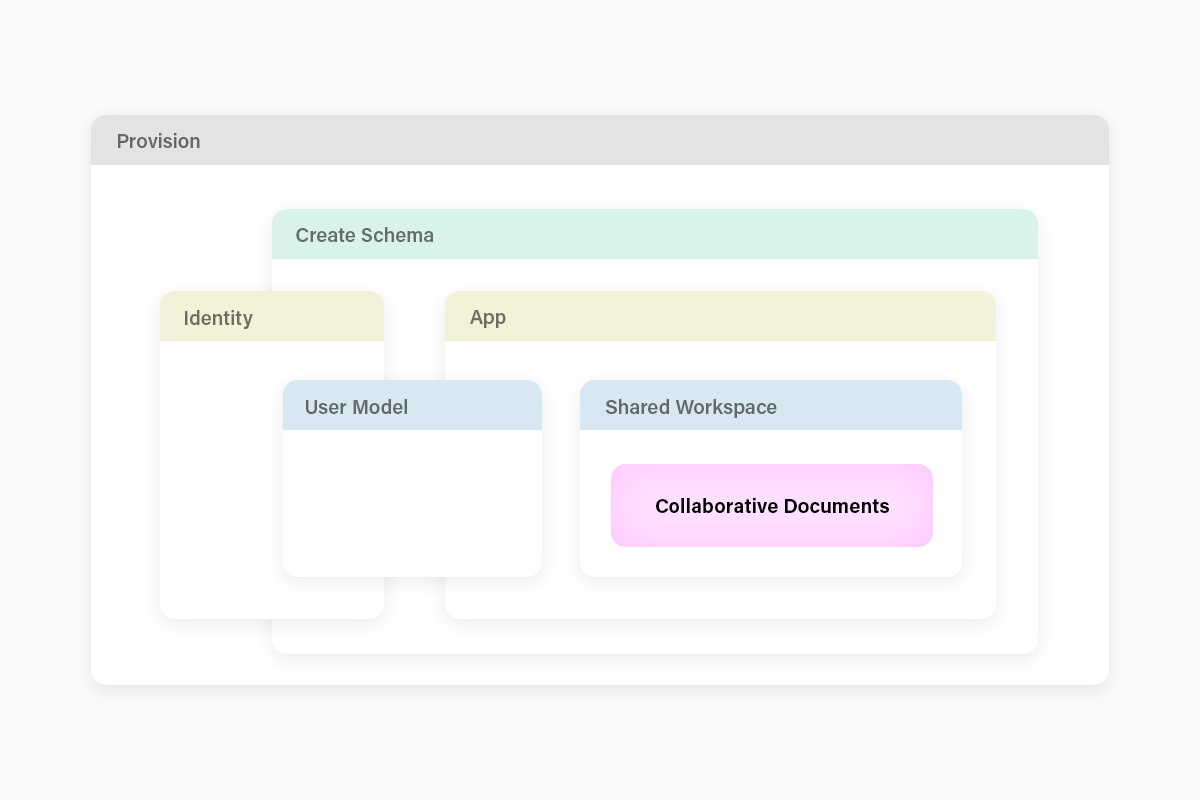
The highlighted purple area in the diagram below corresponds to the main collaborative business objects of the application. This is where the code lives that can set your application apart from the competition. Whether it’s a simple discussion board or a complex point-of-sale system for a large chain retailer, most of the vertical specific logic will live in the heart of the application, the collaborative documents. And the more cleanly we encapsulate that area, the more flexibility we’ll have in adapting the application to different operational requirements. For instance swapping out the identity component, or the cloud provider, shouldn’t need to impact the business logic.

Outside of the collaborative documents, most of the complexity doesn’t differentiate the application, so application developers try to minimize it. It’s boilerplate, and the real value is in the collaborative documents, whether they represent travel plans or market positions. Developers understand the value of a starter kit. As a database company, Fauna is in a unique position to offer starter kits that include the fundamental building blocks for an application data model.
I’ve been building applications along these lines since pre 1.0 Ruby on Rails. Here I’ll show you how I'm implementing this model for a Fauna Netlify JAMStack app.
First of all, you should know there’s a ton of boilerplate that Netlify handles for you. Below is a diagram that visualizes more stuff we don’t have to worry about when writing the app. Also included in the platform (but not the diagram) are operational concerns like cloud hosting, CDN, DNS, security certificates, etc. A developer building application features that work with collaborative documents, has leverage over so much infrastructure, so anytime we remove friction the effects are cumulative, and the productivity boosts are tangible. In this case by including identity as part of a starter kit, developers can start out with an authentication and identity system that is easy to use as-is or customize. Improvements made in the starter kit implementation are shared across all the apps the use it.
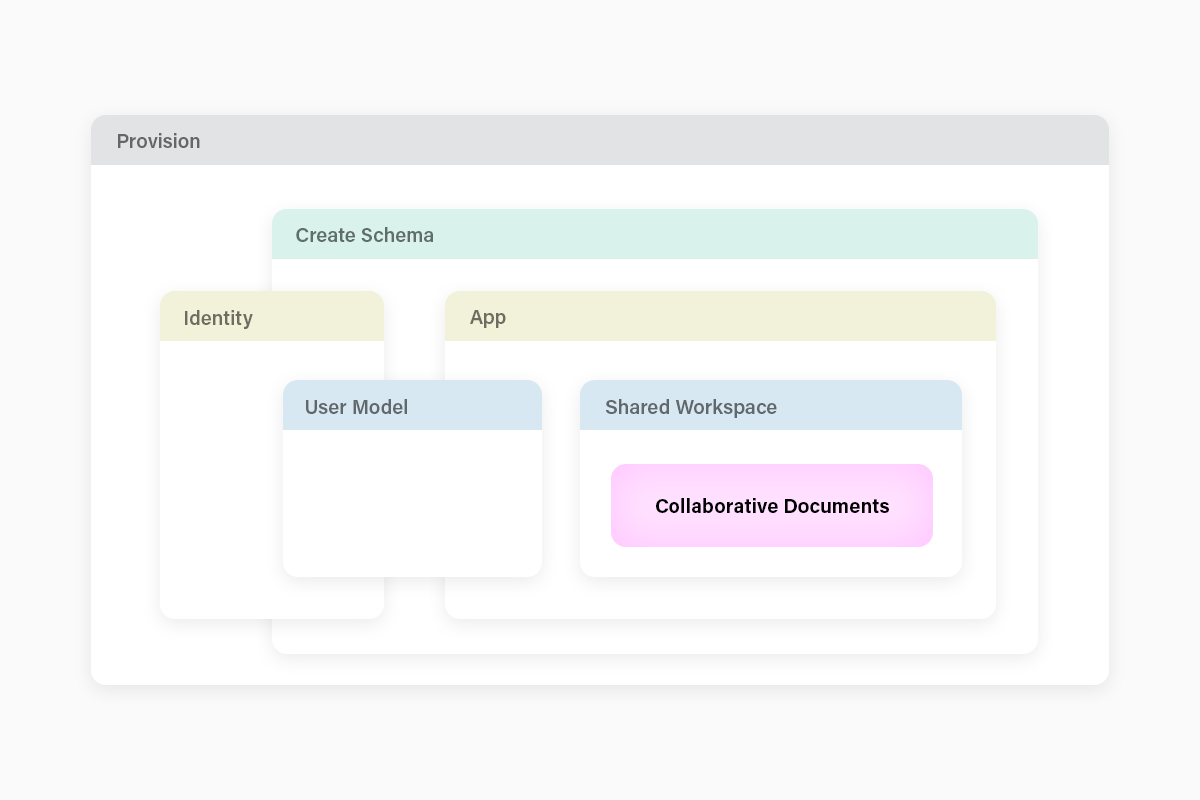
Given the interplay between deployment-specific application configuration, identity, and initializing the database schema, one of the challenges that emerges is how to encapsulate application lifecycle changes so that the collaborative document schema can depend on the user model, without introducing complexity and brittleness. In short, how can we package the whole thing up so your app just pulls in a couple of modules to do the boilerplate, while maintaining complete flexibility for your business logic?
One solution is to maintain the user and identity components in a separate module, perhaps as part of a faunadb-user package and a faunadb-netlify package, that can be reused. On the identity front, we are most of the way there, with the only task being the splitting of the schema management into identity and application components. They’ll share a namespace, so a system of setup hooks may be on the horizon. This allows the boilerplate components of the app to be managed independently of the application-specific code.
The end result is an application template embodying best practices, like React hooks and Netlify Identity for user management, that offers user-level, role-based data access control with minimal development effort. The secure data API means both web and mobile clients can connect to Fauna. Working in a code environment like this, adding valuable new features becomes the focus of the developers’ attention.
This article is an introduction to a long-term project. My current next step is to add tests to the database schema setup code, and then to add access control tests. This will make future work on the application safer and easier. For an update on the code-level current status of the project, check out the previous post in this series.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.