
DynamoDB pain points: How to address them and exploring possible alternatives
DynamoDB is a robust NoSQL database that has become increasingly popular due to its performance, scalability, relative simplicity, and low operational overhead. However, it has its drawbacks. Some of the main disadvantages of DynamoDB include limited querying options, limited storage capacity (400kb per document), no multi-region ACID support (eventual consistency), and difficulties in replicating data in multi-region setups.
In this article, we will explore the main pain points of DynamoDB, how to overcome them, and explore some of the DynamoDB alternatives.
Indeed, there are areas where DynamoDB is the most compelling solution when it comes to speed. DynamoDB is a low-latency, fully managed NoSQL database that is ideal for applications where speed is more important than strong consistency.
DynamoDB automatically scales up and down (when you use provisioned capacity) based on the application traffic pattern. It supports automated sharding, so you do not need to manage shards manually. If your application requires high scalability and speed and doesn't need complex data relationships or transactions, DynamoDB is the way to go. However, Dynamo does have some drawbacks, which I will explore below.
Limited querying capabilities
If you have worked with DynamoDB to some extent, then you know that relational data modeling is tedious with DynamoDB. There are no foreign key joins in DynamoDB like most people are used to in relational databases. You can, however, handle complex data access patterns similar to relational databases. In DynamoDB, you can model relationships such as one-to-many, many-to-many, and one-to-one. You can use a variety of strategies, such as denormalization, duplication, and composition of primary keys. However, these solutions require a fair amount of engineering effort and introduce a number of other limitations to consider.
👉 Follow Alex DeBrie’s article to learn more about data access patterns in DynamoDB.
DynamoDB can only perform query operations on tables with a single primary key. Consider the following table for example. The primary key of this table is the user ID, a unique identifier for each user. The table might have other attributes like name, email, and address, as demonstrated below.
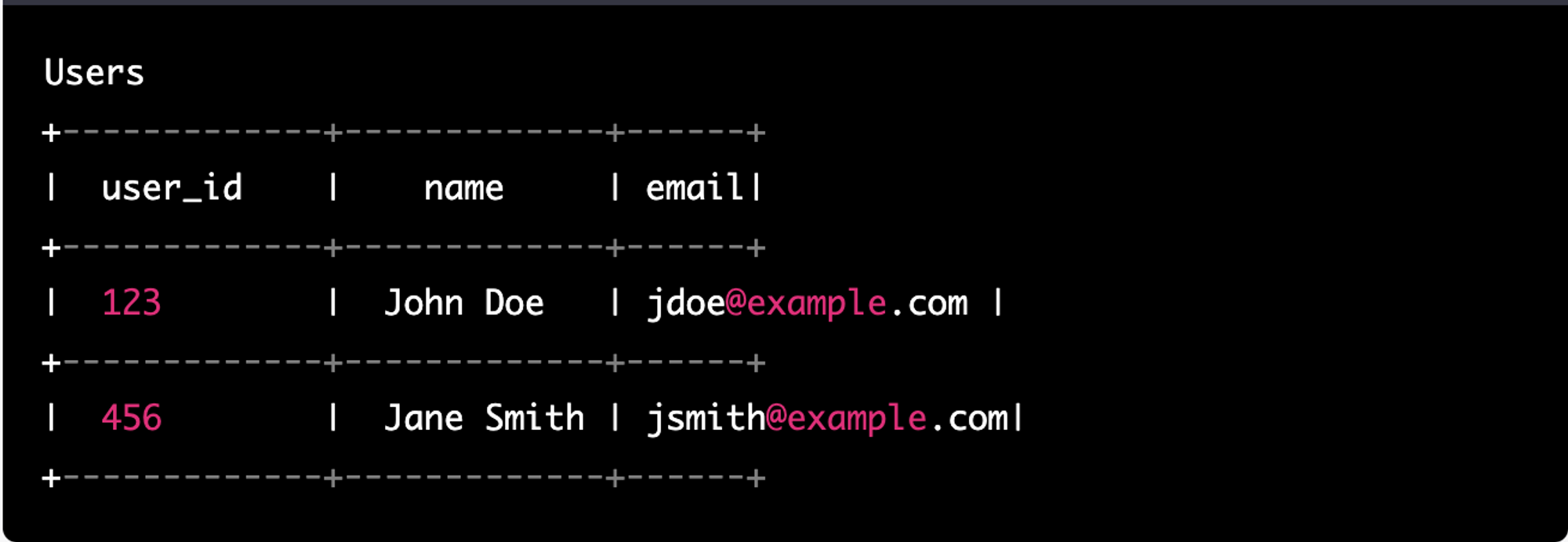
You cannot query the table on other attributes like name and email. You need to set up the global secondary indexes (GSI) with the attributes you want to query and then use the query operation on the GSI. Those of us using DynamoDB for a while are okay with this pattern of storing data. Nevertheless, this is a limitation.
Moreover, you have to consider the cost of using GSIs. GSIs consume additional read and write capacity units (RCUs and WCUs). Learn more about GSI costs here.
Let's say you have a DynamoDB table called “Products” with a primary key of product_id and a few other attributes like "name" and "price". The table is provisioned with 1,000 RCUs and 1,000 WCUs. If you want to create a GSI for querying on the "name" attribute, it will require additional RCUs and WCUs to perform queries on the "name" attribute. So now you need to provision 1,000 RCUs and 1,000 WCUs for the primary key and an additional 1,000 RCUs and 1,000 WCUs for the GSI, doubling your DynamoDB usage cost. As your application grows, GSI optimization is an additional overhead you must be mindful of. In a relational database, you don't have to worry about these.
Comparing a SQL database to a NoSQL database is like comparing apples to oranges. NoSQL databases such as DynamoDB are excellent for horizontal scalability, high availability, and flexibility for handling unstructured and semi-structured data. However, features such as foreign key constraints and ACID (Atomicity, Consistency, Isolation, Durability) transactions, which we take for granted in a relational database, are not present by default in DynamoDB. Manually configuring these capabilities takes a lot of engineering effort and specialized knowledge. In brief, you have to deal with increasing application complexity because of GSI.
If you are exploring Amazon DynamoDB alternatives that are NoSQL and have better-querying capabilities, there are a few to choose from, but the one I will be covering here is Fauna. Fauna combines the querying capabilities of relational databases (SQL databases) with the flexibility of NoSQL databases.
A database management solution like Fauna bridges the gap between a traditional relational database and a flexible NoSQL database by allowing data to store in JSON-like documents while also giving the ability to create SQL-like data relationships among collections.
👉 Learn more about Fauna’s document-relational model.
Like DynamoDB, Fauna is also a fully managed NoSQL database with low latency. It also auto-scales, ensures high availability, and adapts to your application traffic. DynamoDB has been around for 10+ years now, whereas Fauna is relatively new.
Challenges of multi-region data replication
While DynamoDB global tables provide a way to replicate data across multiple regions, it can be a complex and costly process that requires additional setup, management, and code — and it may only support some features or data replication across all indexes.
You have to create the same table in multiple regions with the same schema, indexes, and throughput settings. Additionally, data replication between different regions needs to be configured and managed. There is no zero-configuration solution to replicate data across multiple regions with DynamoDB.
Furthermore, certain features are not available in global tables. DynamoDB Time to Live (TTL), which is the ability to expire items after a specified period of time, is not available with global tables.
Another unsupported feature is DynamoDB Streams. Additionally, local secondary indexes (LSIs) and global secondary indexes (GSIs) are not replicated across all replicas in global tables. You must manually create those LSIs and GSIs in different regions; otherwise, you cannot query data efficiently.
DynamoDB global tables do not provide fault-tolerant support by default
In the case of an outage or a failure in one region, DynamoDB does not automatically switch to another region to ensure data availability.
If distributed data across many regions is one of the core requirements of your application, you are better off using one of the alternatives of DynamoDB, such as Amazon Aurora, Fauna, or Apache Cassandra.
DynamoDB uses an "eventual consistency" model for global data, meaning that updates may take some time to propagate to all replicas fully.
Applications that require immediate consistency across all regions may need to use a different database solution or implement additional logic to handle eventual consistency in DynamoDB. Since data may not be immediately available in all regions, read and write operations may be slower in certain regions. This can affect the performance and user experience of the application.
Fauna is one of the strong competitors to Amazon DynamoDB for its multi-region data replication. Fauna provides multi-region data with strong consistency. It automatically routes your requests to the nearest replica, ensuring that your application experiences low latency. Fauna automatically replicates your data across all regions, ensuring that your data is always up-to-date and available — even in case of a regional outage or failure. Unlike DynamoDB, Fauna requires zero configuration for global replication. Strong data persistence in all regions is always guaranteed. If you compare Fauna to DynamoDB, you realize that Fauna offers all the features of DynamoDB without the drawbacks.
Apache Cassandra is also another alternative to Amazon DynamoDB. It is a free, distributed wide-column, NoSQL, open source database that can handle a large amount of data across multiple regions. However, you must manage your infrastructure and clusters if you decide to use Apache Cassandra. Managing your clusters can be challenging, even though Cassandra has robust documentation and an active community behind it.
Another database you may be interested in as an alternative is MongoDB Atlas, the managed service for MongoDB.
👉 Learn how Fauna stacks up against MongoDB.
Storage limitations
Another pain point with DynamoDB is the item size limit. An individual item has a maximum of 400kb in size. The item size limit impacts the way data is modeled. The application may need to denormalize the data or split it across multiple items to work within the item size limit. The storage limitation is not a big deal for most applications out there, but if you plan to grow and scale your application to millions of users, you should start thinking about the additional complexity you need to handle.
DynamoDB competitors such as MongoDB, Fauna, or Cassandra don't have this issue.
Building scalable applications on DynamoDB
DynamoDB is well known for its low latency and scalability. However, as you build and scale your application with DynamoDB, you must be aware of some common pitfalls. As discussed in the previous section, an individual item in DynamoDB can be at most 400kb. While building with DynamoDB, it is crucial to understand the data model that best fits your application's use case and design the table schema accordingly. Failing to do this at the start will cost you as you scale your application.
Although possible, evolving your data with DynamoDB as your application grows is challenging. You need to choose the correct partition key. Selecting the right partition key ensures that the data is evenly distributed and read and write requests are distributed evenly across all partitions.
Limited ability to perform advanced analytics
DynamoDB is optimized for storing and retrieving large amounts of data quickly, but it is ill-suited for performing advanced analytics on that data. It doesn't support advanced features such as aggregate functions or window functions.
SUM, COUNT, AVG, and MAX are commonly used in SQL to perform calculations on groups of data. DynamoDB alternatives MongoDB and Fauna have equivalent features to perform these analytics tasks. In MongoDB, you get aggregate functions such as $group, $match, $project, etc. Fauna also provides aggregate functions through Fauna Query Language (FQL) for advanced analytics.
Window functions are another advanced SQL feature that DynamoDB does not support. These functions allow users to perform calculations over a set of rows related to the current row in a query. Fauna also does not have built-in window functions, but it is possible to perform calculations similar to window functions using the Map-Reduce function and a combination of other functions. MongoDB does not have built-in window functions either. However, it does have the $bucket operator, which can be used to perform similar calculations.
If you insist on using DynamoDB and need robust analytics, then your best bet is to use third-party analytics tools such as Apache Hive or Apache Pig to perform complex queries and advanced analytics on the data stored in DynamoDB. You have to consider the additional cost of these extra resources, however.
Conclusion
To conclude, DynamoDB is well-suited for use cases that require high scalability, high performance, and low latency. It seamlessly integrates with other AWS services and supports document and key-value data models. However, it also comes with its limitations. Limited query capabilities, little support for the transaction, eventual consistency, and limited support for analytics are some of the main pain points with DynamoDB. With enough engineering resources and time, you can overcome these pain points.
Everything in software engineering is about tradeoffs. Every database management solution has its pros and cons. It is up to you and the developers to choose your company's best solutions. This article gives you a clear picture of the various limitations of DynamoDB and some of the alternatives to DynamoDB so you can make the best-informed decision while choosing a database for your next project.
💡 Though DynamoDB has much to offer, Fauna is a much newer offering that comes with a host of powerful and unique features that enhance the serverless experience for organizations of all sizes. Read more at “Modernization of the database: DynamoDB to Fauna.”
If you're experiencing any of the DynamoDB pain points mentioned above and are looking for a more robust and efficient solution, consider reaching out to either me or the team of experts at Fauna.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.