
Inside Fauna’s distributed transaction engine
Luis Colon|Aug 21st, 2023
Fauna is a distributed document-relational database designed to support demanding transactional applications with low latency, high availability, and strong consistency across geographically distributed regions. This post delves into the key components of Fauna's Distributed Transaction Engine (DTE), which enables Fauna to achieve these capabilities.
A flexible, layered system
Fauna's architecture is built on logical layers that separate core database services, facilitating efficient request handling and robust fault tolerance. The main layers include routing, query coordination, transaction logging, and data storage. Each node in Fauna's topology is aware of the entire system and can forward requests to other regions if needed, ensuring no single point of failure.
Fauna’s DTE is inspired by the Calvin transaction protocol, which uses deterministic ordering to reduce the need for distributed locking. By pre-ordering transactions in a global, replicated log before execution, Calvin minimizes contention and ensures that all replicas process transactions in the same order. This method allows Fauna to maintain strict serializability across a globally distributed system, providing high performance and reliability without the complexities of real-time clock synchronization.
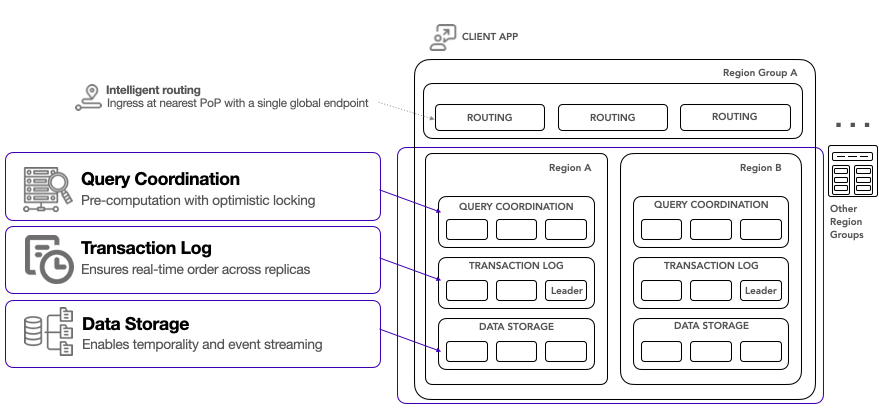
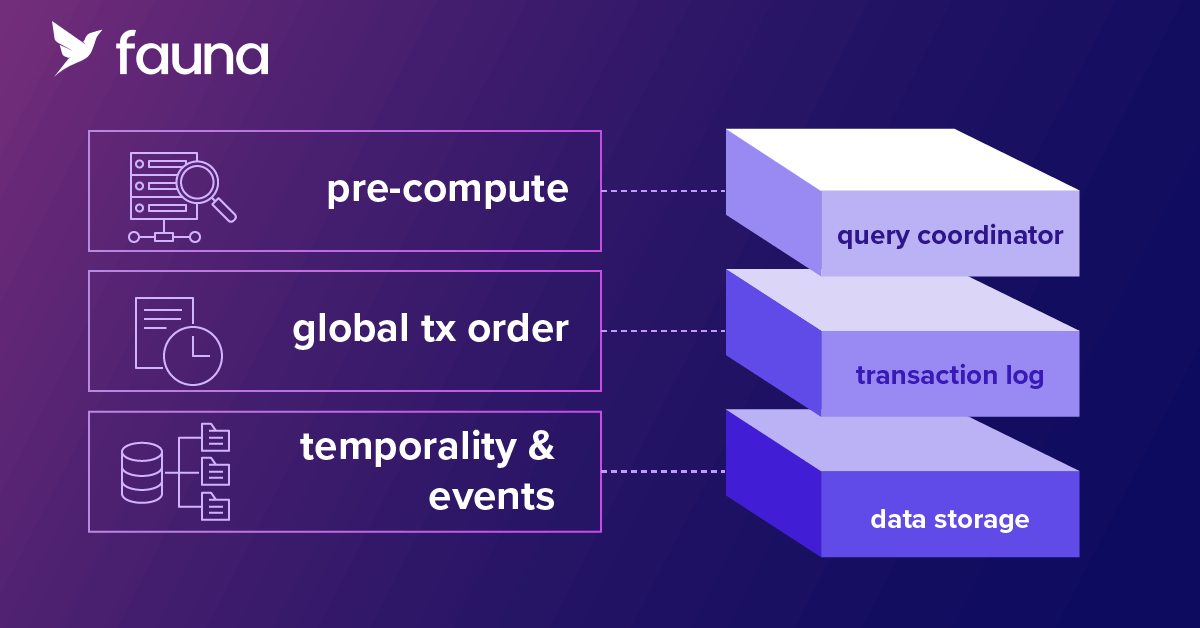
Fig. 1. Fauna’s distributed transaction engine (DTE) Layers.
Routing layer
Requests that are sent to Fauna are initially handled by the routing layer, which directs them to the appropriate node in the nearest region and region group. This process begins with a highly available DNS service that uses latency-based forwarding to route requests to nodes in the nearest zone or region.
Requests are first handled by an ingress controller that applies a series of plugins to manage traffic. These plugins can throttle requests based on IP address, rate limits, or capacity, ensuring that the system can handle bursts of traffic and maintain stability. The next step involves a service mesh component that maps and caches incoming database keys to the corresponding region where the database resides. If the key has not been seen before, the service sends a multicast message to coordinators in each region to find the correct location. This allows developers to use a single endpoint for all requests, simplifying the application architecture by abstracting the underlying complexity of locating the ideal replica to query.
Query coordination layer
Routed requests are handled by the query coordinator layer which consists of stateless, horizontally scalable nodes that perform pre-computation of transaction inputs and effects before execution. This process removes the need for pre-transaction locks by determining transaction outcomes in advance. Coordinators select a snapshot time for each request, inspect the associated transaction, and optimistically execute it without committing writes.
If no writes are included, the coordinator returns the query results to the client. If writes are involved, the transaction is passed to the logging layer for further processing. This approach ensures that read transactions are served with minimal latency while maintaining the ability to handle complex transactional workloads efficiently.
Transaction logging layer
The only point of cross-region communication in a region group is the transaction logging layer, which functions as a global write-ahead log. The log is divided into segments to enhance scalability and redundancy. Using an optimized version of the Raft consensus algorithm, this layer ensures each transaction is consistently replicated across multiple replicas.
Leaders coordinate with other segment leaders to agree on the set of transactions in each batch. Once the batch has been replicated across the Raft ring, transactions are considered optimistically committed. This means their write effects are pending but guaranteed to be applied consistently. When all segments commit their batches for a given epoch, the transactions are ready to be processed by the storage layer.
Unlike other distributed databases, Fauna does not require real-time global clock synchronization to guarantee correctness. Only the log nodes generate epochs, and their clocks are synchronized using NTP. This ensures epochs are generated approximately at the same time, allowing each transaction to be timestamped accurately, reflecting its real commit time and its logical, strictly serializable order relative to other transactions.
Data storage layer
The data storage layer consists of nodes assigned specific key ranges, ensuring the complete keyspace is represented and redundantly stored across multiple nodes in each region. Storage nodes maintain persistent connections to log nodes and listen for newly committed transactions in their key ranges.
When a storage node receives a new transaction, it validates that the values read during execution haven't changed between the snapshot time and the final commit time. If there are no conflicts, the storage node updates the values it covers and informs the query coordinator of the transaction’s success. If conflicts arise, the storage node drops the writes and notifies the coordinator of the failure. This deterministic set of checks ensures all nodes either apply or fail the transaction consistently.
In Fauna, documents are never overwritten. Instead, new versions are created as either create, update, or delete events. This versioning enables temporal queries, allowing transactions to be executed consistently at any point in the past. Temporal queries are beneficial for auditing, rollback, cache coherency, and synchronization with other systems. Additionally, event streaming allows external systems to receive notifications when documents or collections change, facilitating near real-time data updates.
Additional optimizations
Fauna’s DTE offers several advantages over traditional single-node and newer distributed databases. It delivers high performance and strong consistency without requiring specialized hardware or complex database operations. Fauna's architecture ensures low-latency performance and simplifies transaction management by avoiding costly operations like two-phase commits that can lead to highly variable performance under specific traffic patterns. The layered design also allows for seamless autoscaling and a clean separation of concerns, making it robust and efficient for modern applications.
Fauna's distributed nature ensures that no single point of failure can bring down the system. It can tolerate temporary or permanent node unavailability, increased node latency, or network partitions isolating zones or regions. This resilience, combined with its robust fault tolerance and efficient request handling, makes Fauna ideal for modern, distributed applications.
Conclusion
Fauna's Distributed Transaction Engine stands out for its ability to handle complex, distributed transactional workloads while maintaining strong consistency and low latency. Its innovative architecture and robust fault tolerance make it a compelling choice for modern, distributed applications. Explore Fauna to experience these benefits firsthand.
Further reading
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.