

Why Fauna: Use cases unlocked with Fauna
Tyson Trautmann & Wyatt Wenzel|Aug 21st, 2023
In Why Fauna: The limitations of alternative databases and the Fauna advantage, we explored why legacy database approaches are inefficient for delivering modern application experiences, and why Fauna is uniquely positioned to support the next generation of dynamic applications.
In this second installment, we take it out of the abstract and into real-world use cases and customers that are benefiting from Fauna’s revolutionary document-relational database. We made some difficult trade-offs while building Fauna, but the result is a database that is particularly compelling for the following application architectures and use cases:
User-centric apps
User-centric apps are applications that model user information in a user data store alongside primary application data. This can include account information, personal data, user activity, and entitlements. User data stores typically require modeling relationships between users and other entities, such as linking a user to comments they have made or things that they have purchased. User PII must be stored in a way that is compliant with privacy regulations and corporate data governance policies. Changes to user data usually require strong consistency; a user should be able to log in right after creating an account or see a purchase as soon as it is made. Verticals that typically leverage a user-centric app architecture include e-commerce, social media, and gaming.
Fauna delivers on all of the key requirements for user-centric apps. The database supports first-class relationships between documents, and FQL makes it easy to query across entity types using a simple dot-chaining syntax. Fauna’s Region Group (RG) abstraction makes it easy to control where data is replicated; the current public RG footprint provides convenience for US and EU customers and the ability to spin up Virtual Private Fauna (VPF) instances across any combination of regions and cloud providers means that customers have absolute control over where their data resides. Finally, the fact that Fauna offers strict serializability – the highest possible form of consistency guarantee – gives developers confidence that their applications will behave correctly across edge cases.
An example of this architecture is Insights.gg – a user-centric app and recording, collaborating, and reporting platform designed for sharing and reviewing video game highlights and performance. Initially built on a single-region PostgreSQL cluster, Insights.gg suffered from high latency and extensive engineering operations as its user base began to scale to millions of gamers and over 100,000 daily active users across the globe. Insights.gg migrated to Fauna because it offered superior performance (reducing latency by 2x), while simultaneously enabling their development team to focus on delivering differentiated business value on the front end, instead of spending significant engineering cycles on database maintenance activities like provisioning, replication, sharding, and scaling.
Insights.gg uses Fauna to store user information, video URLs, team metadata, privilege, and access settings for team management, comments for videos, and vector-based drawings. Fauna’s native relational capabilities allow Insights.gg to keep their application code lightweight and performant, while its document data model allows the team to maintain agility in their data model as the application changes over time. With users across Europe, North America, and Asia, Fauna’s concept of Region Groups with auto-replication and distribution abstracts away the complexity of adhering to disparate data regulations, while accommodating spiky traffic patterns as different regions around the world increase or decrease usage over the course of the day. Finally, Fauna’s API delivery model enables integrations over HTTP with their broader distributed and serverless stack built on Cloudflare Workers and Fly.io.
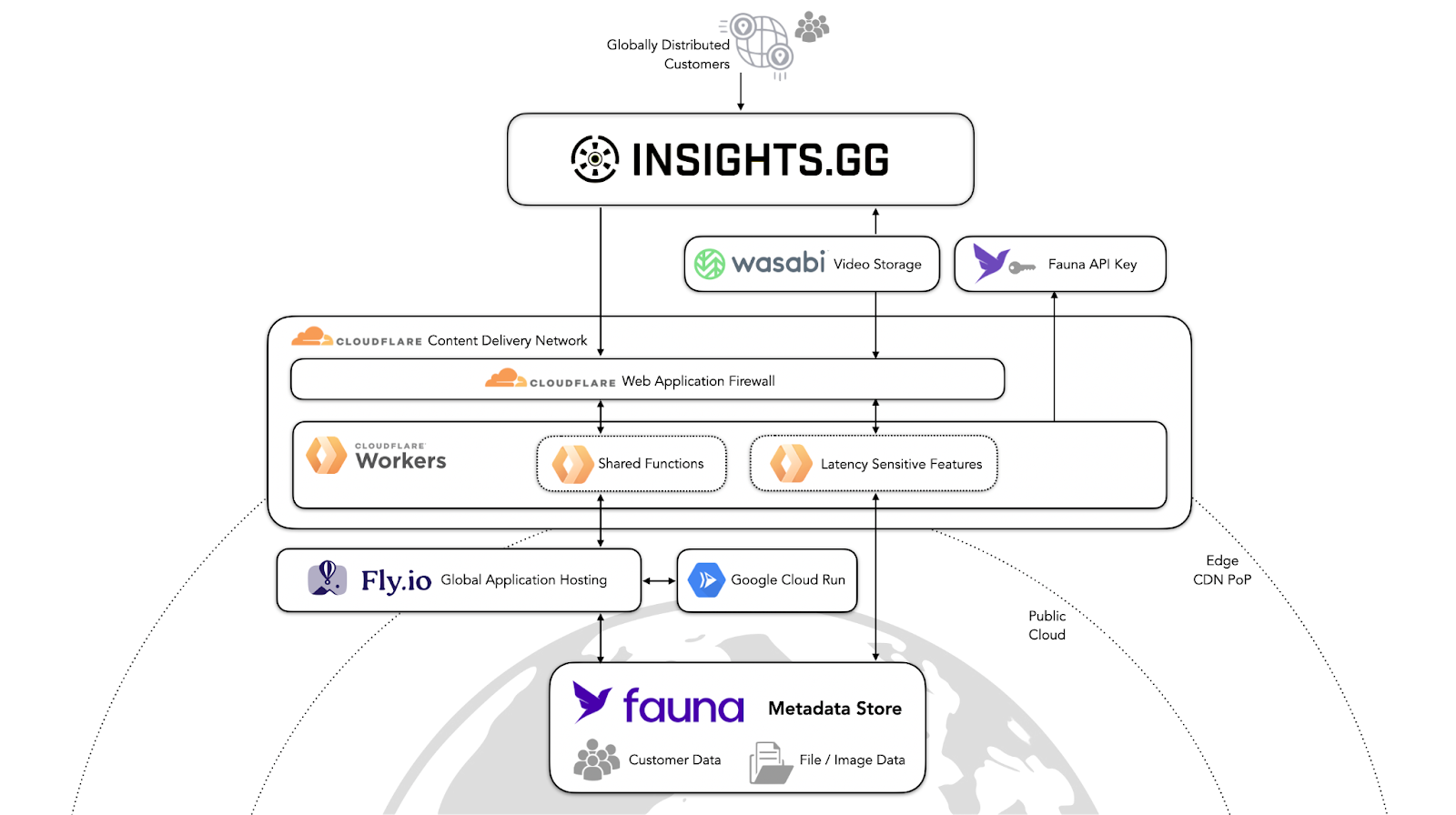
“One pain point we had with PostgreSQL was having to synchronize our schema updates as well as our code deployments. Leveraging Fauna’s document-relational model allows us to forget about schema changes and focus just on deploying the code, which allows us to deploy faster without timing the deployments or schema changes. At the same time, we can still apply relations. The word that comes to mind when I think about Fauna is ‘flexible’.” -Insights.gg CTO Steve Lam
Distributed real-time apps
Distributed real-time apps are applications that run on edge devices and require fast data access for both reads and writes. These applications run on disparate hardware including PCs, mobile devices, and IoT devices of various formats. They rely on data that is replicated to sit closer to the edge so that the application consumer (whether human or machine) can act quickly when data changes. Distributed real-time app architectures are typically leveraged by personalized recommendation systems, real-time analytics systems, financial platforms, and IoT applications.
Fauna is a perfect choice for distributed real-time apps because its underlying DTE replicates data across regions in an RG, with low latency and strong consistency. Without any customer configuration, Fauna ensures that that data is close to the consuming application and allows for fast, single-millisecond reads from the closest region. Additionally, Fauna routes requests through its Intelligent Routing (IR) layer, ensuring that requests ingress near the edge and are optimally routed over a fast and reliable cloud provider backbone.
Climatiq has built a distributed real-time app that offers a carbon calculation engine delivered via an API, which simplifies the process of calculating the environmental footprint of a company’s emission-generating activities. Climatiq converts operational activity into CO2e estimates, which are then embedded into customers’ applications. Climatiq (and the underlying emissions data) is exposed as a REST API that can be easily consumed by enterprise business systems such as ERP applications and data warehouses.
The Climatiq team opted for a composable, best-of-breed serverless and distributed approach that delivers modular pieces of functionality. For edge architectures like Climatiq’s that are optimized for low latency, services like Fauna that are delivered via an HTTP call are attractive because they do not require connection pooling. Fauna’s API delivery model, distributed architecture, and flexible data model (while maintaining the strongest consistency guarantees) make it a powerful complement to its ephemeral compute layer.
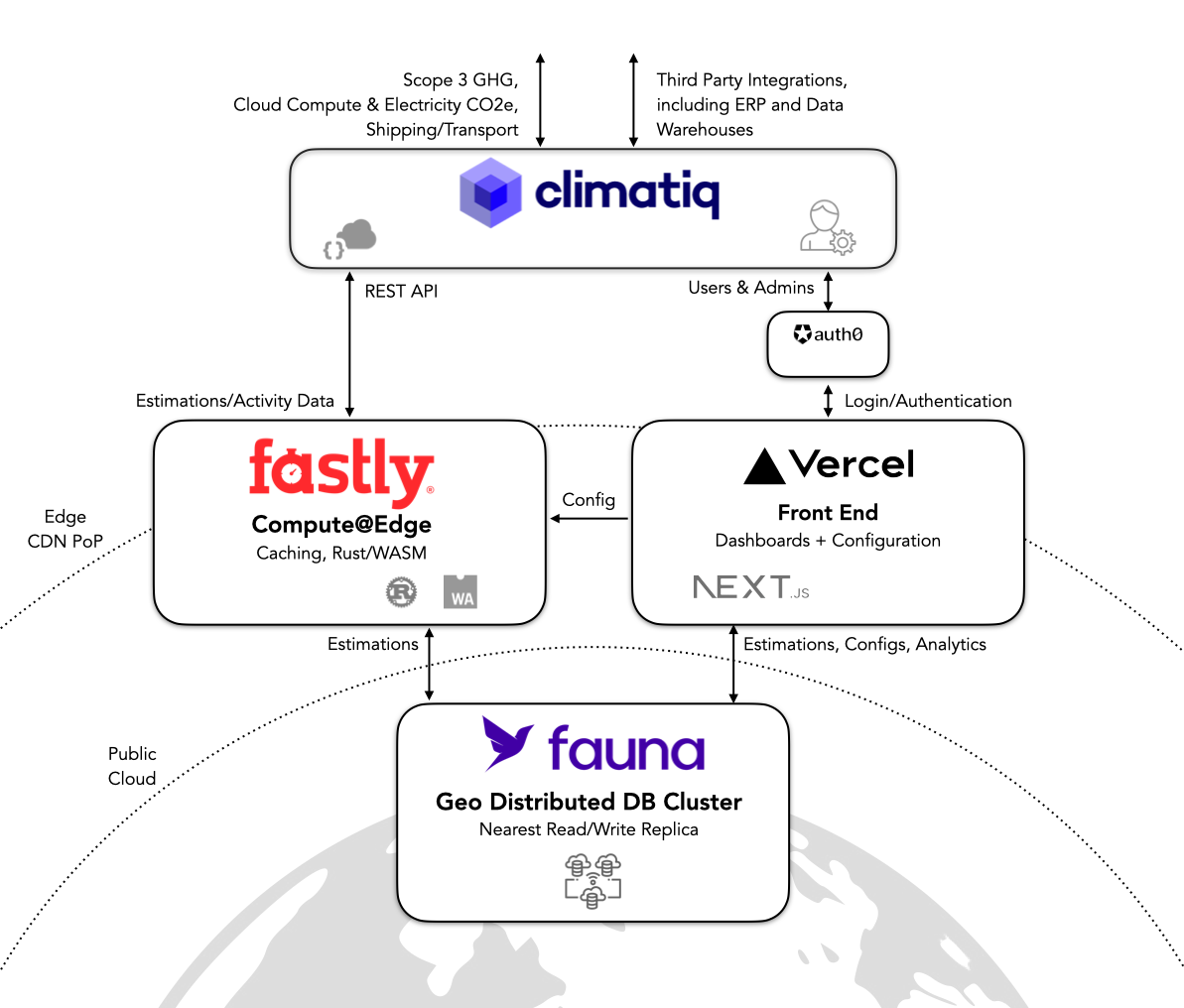
“Adopting Fauna and Fastly Compute@Edge early on has been instrumental in our ability to test and release features quickly. It allows us to maintain our data logic in a single place, and provides enough flexibility to adapt to different requirements across our application.” With this distributed architecture delivered at the edge, Climatiq is able to “achieve ultra-low latencies, consistently under 100ms, and sometimes even as low as 30ms.” -Climatiq CTO Isis T. Baulig
Stateful serverless apps
Stateful serverless apps are applications that require tracking state while executing state changes on ephemeral compute. Also called client-serverless apps, these applications often involve complex state changes where ACID guarantees are required to avoid getting into an invalid state and breaking the consuming application. Use cases where stateful serverless apps are common include workflow orchestration systems, advanced order processing systems, and business process integration systems.
Fauna works well when underpinning stateful serverless apps for a few reasons. The FQL wire protocol is built on top of vanilla HTTP, which makes it easy to execute transactions from serverless compute platforms without worrying about maintaining connections or sequencing multiple requests and responses to execute a single transaction. Fauna’s transaction model ensures that application state changes execute fully or not at all, eliminating the possibility of data corruption or getting into a bad state.
Hannon Hill is the maker of Cascade CMS, a stateful serverless app and the most popular CMS for universities and colleges. Clive is a real-time web personalization bolted onto Cascade and third-party CMS solutions that delivers a better visitor experience by offering more targeted content based on form submissions, location, and digital activity such as page views and search terms.
Before implementing Clive, the Hannon Hill team prototyped a content personalization system with Grails and MySQL, but encountered many performance issues related to fetching, filtering, queue processing, and paginating data from millions or billions of rows in the database. The Hannon Hill team tapped Fauna for Clive because of its modern architecture delivered as an API, powerful query language and flexible data model, and distribution-by-default.
Fauna’s relational capabilities in the context of its document data model also proved to be a strong differentiator, particularly when model and schema changes were necessary. Schema updates over millions of rows can be time-consuming and costly, but Fauna’s support for semi-structured documents allowed Hannon Hill to avoid such updates altogether.
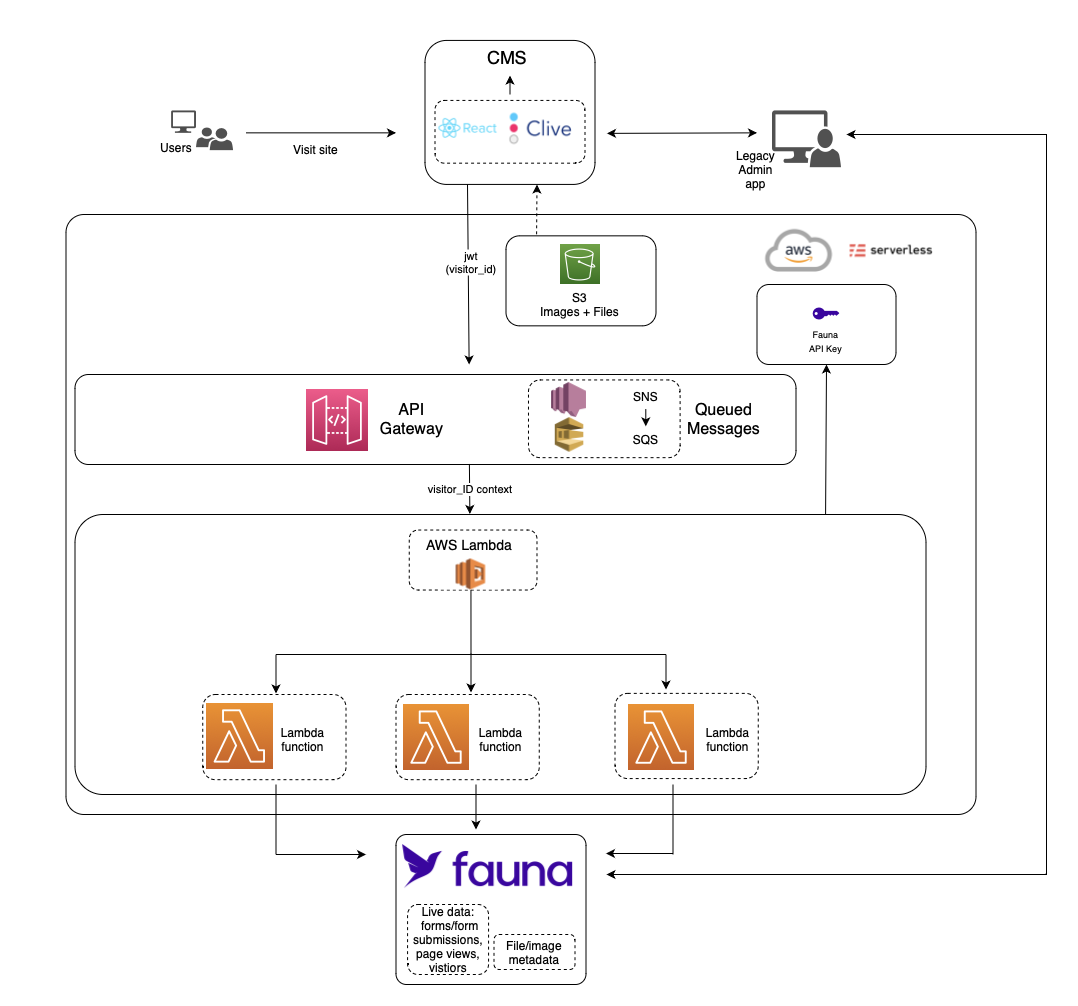
“Instead of taking care of load balancing and manually scaling servers and a database with a classic three-tiered architecture, we decided to go the serverless route, and a stack with AWS and Fauna turned out to be the best option. Some of our client accounts have accumulated many millions of visitors, visits, and page views. Fauna allows administrators to browse that data quickly using cursor-based pagination, no matter what page the user is currently viewing and no matter how big the dataset is. This is a clear improvement over our legacy tooling where loading large data tables with hundreds of pages was resulting in sluggish performance.” -Hannon Hill** Senior Software Engineer Artur Tomusiak
Secure multi-tenant apps
Secure multi-tenant apps are applications where multiple tenants or users share underlying hardware or software resources, but must ensure that sensitive data is well-isolated from other tenants and secure from malicious actors. This architecture is commonly used in B2B SaaS (Business to Business Software as a Service) offerings, where a single instance of the software runs on the cloud and serves multiple tenants. Examples of application types where secure multi-tenant app architectures are used are plentiful, including cloud-based CRM systems, productivity tools, and developer tools.
Fauna is well suited to power secure multi-tenant apps because of its database-as-a-container data model. Each database in Fauna serves as an access boundary (similar to a Docker container) which makes it easy to limit access by key, without relying on complicated and error-prone table or row-level access configuration. The Fauna Schema Language (FSL) allows application developers and administrators to provision and manage thousands of per-tenant databases, and schema enforcement mechanisms ensure that the data in each database conforms to the desired shape.
Cloaked is a consumer-facing secure multi-tenant app that allows users to create unique identifiers (emails and phone numbers) for websites when creating online accounts. When Cloaked decided to migrate from a legacy database, Cloaked assessed both MongoDB and DynamoDB, but realized they needed a database governed by its own privacy rules. The team was attracted to Fauna’s ease of use in spinning up databases on the fly while keeping user data separate. Fauna is used as the core user database hosting all sensitive information — leveraging Fauna’s database sandboxing to keep tenant information isolated and secure.
“When we looked at all these different solutions, we realized that Fauna was the one that stood out for using API calls and instant access databases — spinning up horizontally and resource-managed vertically on their own, whereas so many database solutions out there required us to do a lot of work to get speed, scale, and security. We get all the power and flexibility of a NoSQL database, but can leverage relational database aspects of both tools at the same time. **We didn't realize that we can utilize NoSQL-like thinking with SQL-like support in one system.” -Cloaked **CEO Arjun Bhatnagar**
Fabriq is a B2B secure multi-tenant app constructed as a SaaS platform that is purpose-built to improve operations for shop floor teams. Fabriq’s industrial business clientele are located around the world and have strict security and privacy requirements.
Fauna automatically distributes data to global locations, delivering predictable low latency read and write access wherever a client may be accessing the application, as well as protection against data loss from infrastructure failures. Through Fauna’s Region Groups, Fabriq customers are able to meet data residency requirements, even though the application is global by default. Region Groups give control over where your data resides; each database, its storage, and its compute services exist in a separate geographic region, making it possible to comply with data locality legislation, such as GDPR in Europe, while benefiting from the distributed service features built into Fauna.
Finally, Fabriq was able to achieve all of this while taking advantage of Fauna’s API delivery model — sharding/provisioning/replication are delivered automatically.
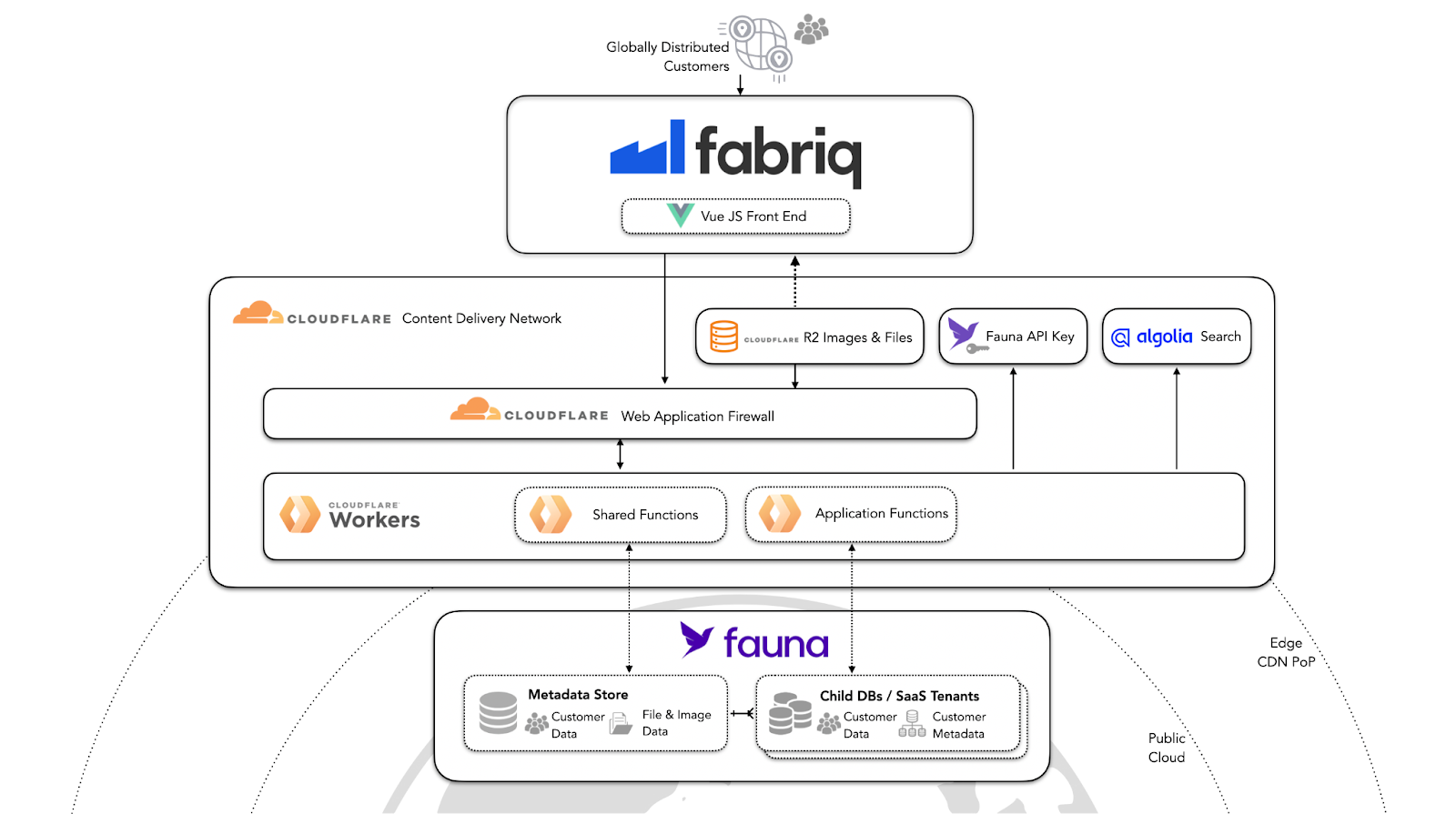
“Fauna has a powerful model of lightweight hierarchical databases. It is very easy to create one database per customer, while still managing all databases as a whole — allowing us to meet a core security and privacy requirement. No operations and infinite scalability are also tremendous perks” - Fabriq Head of Technology Yacine Hmito
Conclusion
Fauna has introduced a revolutionary design purpose-built to address historical database shortcomings and accelerate application development as a result. It is ideal for a number of modern application architectures including user-centric apps that require consistency and data privacy, distributed real-time apps that need swift data access at the edge, stateful serverless apps that demand faultless state changes, and secure multi-tenant apps that call for robust data isolation. By seamlessly merging the agility of JSON documents with the robustness of relational database querying — all backed by an innovative distributed transaction engine — Fauna transcends traditional limitations. It not only ensures consistently high performance but also provides developers with an unparalleled experience, all the while eliminating the tedious operational challenges of database management.
Real-world testimonials from enterprises such as Insights.gg, Climatiq, Hannon Hill, Cloaked, and Fabriq underscore the transformative impact Fauna has on varied sectors, from gaming and the environment to education and online privacy. In an age where the database landscape is rife with complexities and challenges, Fauna allows development teams to forget about those challenges and just build.
*Ready to get started building with Fauna? Check out the Fauna Quick Start or get in touch with one of our experts if you have any questions.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.