
Beyond SQL: A relational database for modern applications
Matt Freels|Aug 21st, 2023
The relational model and SQL have been foundational database technologies for the last 40+ years. Meanwhile, modern applications look very different from that of 40 years ago when SQL was invented. Software engineering practices, production deployments, and application architectures have all evolved in the decades since; especially in the last 15 or so years with the explosion of cloud computing, the move to the edge, and the rise of services exposed as APIs.
Over this time, the relational model has proven remarkably resilient. It is adaptable enough to represent many application domains, and relational databases have evolved to incorporate attributes of other models1.
For analytical/OLAP use-cases, SQL databases have worked reasonably well (though there are some interesting companies showing how things could be better2). When the data itself is the product and is relatively static, SQL's declarative access is powerful, and time can be taken to groom data such that the uniformity imposed by the relational model is a benefit.
On the other hand, for operational/OLTP use-cases, where the database is but one component of a larger, ever-evolving application and is primarily accessed via code, the traditional SQL database paradigm brings with it a large amount of complexity and baggage:
- Connection centric: SQL's session-based transaction model is maladapted to modern cloud computing abstractions such as serverless, and is difficult to manage at scale.
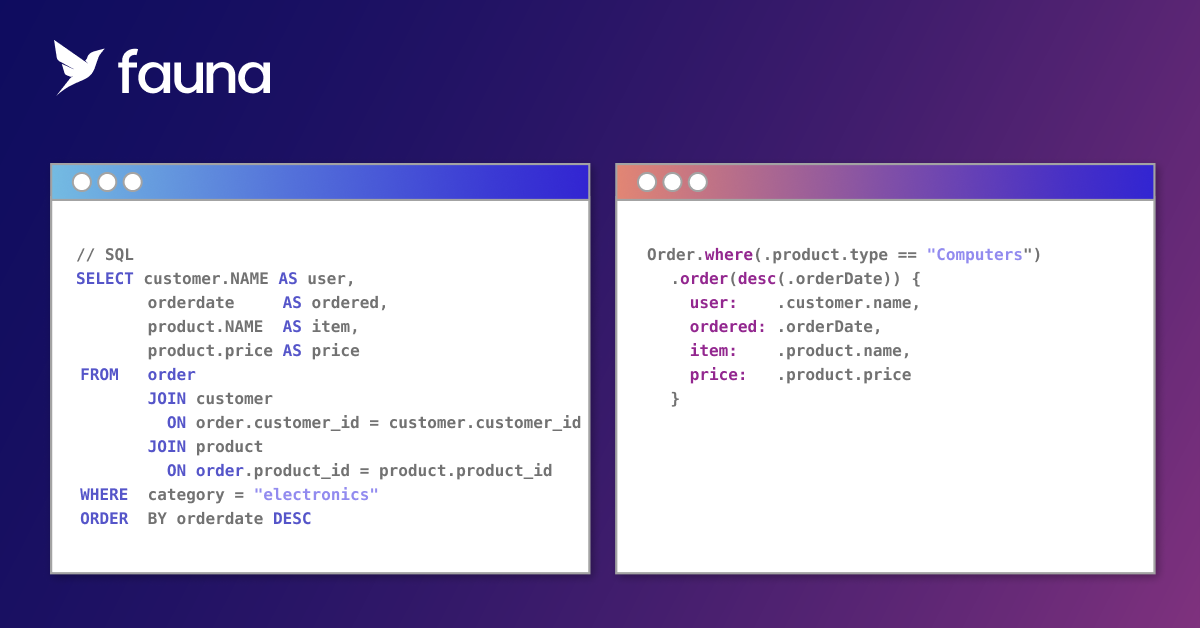
- Inflexibility of result structure: SQL is particularly inflexible in terms of control over response: A query result is always a set of tuples. A query is incapable of returning a rich structure that is aligned with how the application needs to consume the result. ORMs solve this partially at best at the cost of hiding the capabilities of the underlying database. They also obscure the structure of generated queries, making it difficult to understand the resulting performance implications.
- Complicated, irregular syntax: As a language, SQL's syntax is complex, unpredictable, and allows only limited forms of composition. Newcomers find that it is unlike any other language they are already working with. As a result, while most developers wind up with a passing familiarity, few end up comprehensively learning SQL beyond simple SELECTs and JOINs.
- Opaque, unpredictable performance: SQL query performance is opaque and dependent on an optimizer to make the right decision. The developer has imprecise control and a given query pattern's plan of execution is subject to change at unpredictable times.
- Rigid tabular data model: Despite the theoretical adaptability of the relational model to many domains, the flat, uniform structure the traditional SQL database imposes on records is especially rigid, forcing a significant amount of upfront design. Introducing new query patterns and schema evolution is fraught with a significant amount of operational risk. Combined, these hinder iterative application development and risk locking in bad data model design decisions.
To be fair, none of these shortcomings were relevant at the time when the first SQL databases were introduced in the 1970s by IBM and then Oracle. But over time as innovation has occurred within the rest of the application architecture and development practices, developers have had to compensate for these attributes through a series of increasingly complex workarounds.
Yet, operational applications have been built on classic SQL database backends for a long time, and there is no doubt that there is a lot of inertia in the industry to continue to do so. This helps explain why the fundamental problems with the resulting architecture are so insidious. Individually, each of these shortcomings is a headache even if smart engineering can work around the pain.
The problem is that, taken together, they add up to a huge complexity tax on application development, from the initial design, through production deployment, and as the application evolves to meet changing user needs. As application developers, we are like frogs in the proverbial pot, and the water is boiling:
- Unable to leverage the power of the database: Developers cannot take advantage of the full power of the underlying database for fear that the complex, opaque nature of SQL query behavior will overwhelm their ability to understand how queries perform, and quickly address problems when they do come up.
- Increasingly complex application architectures: Conversely, application architectures compensate by becoming more complex. Database concerns such as caching and transaction logic are pushed to the application layer in an ad hoc manner, resulting in consistency challenges and more sophisticated application logic.
- Significant operational bleed: Entire teams must be dedicated to the care and feeding of the database itself as introducing new query patterns or migrating schema—which should be simple—become fraught, complex operational tasks requiring a significant amount of operator expertise to accomplish.
Others have attempted to solve this but attributed many of the problems caused by SQL databases and its associated table-based approach to the relational model itself, leading them to throw both out. Ultimately this was a mistake: The relational model remains a powerful foundation, even if the overall approach for applying it in the context of modern operational applications deserves to be refined.
However, while SQL-based systems can and will continue to adapt, the problems which stem from SQL specifically are fundamental to its design. Fixing them without continuing to pile on complexity cannot be done incrementally. Rather, it requires going back to first principles in order to rethink both what the right database interface and underlying data model should be for today’s modern applications.
FQL: a document-relational database language
SQL is primarily focused on the task of querying relational data, but the overall relationship between an application and the operational database behind it comprises much more. Furthermore the data model of an application can quickly evolve, especially during early application development. Therefore, solving the issues arising from using a SQL database in an operational context involves identifying the correct interaction model between the application and the database, and by taking into account developers' workflows and the lifecycle of the application.
Taking this holistic view, we designed Fauna's query language (FQL) and data model around three goals:
- Everything is a transaction: Database communication should be built around one-shot requests, not sessions, with requests and transactions being one-to-one. Fauna's language should be a full-fledged database language capable of expressing both declarative queries and procedural flow, such that individual requests can encode required transactional logic and tailor results to precisely what the application needs.
- A database language like a programming language: Fauna's language should provide a developer experience similar to that of a general programming language, including syntax, development workflow, debugging facilities, and tooling support. Performance should be predictable and easy to understand, and possible to infer and control based on query structure.
- A model for schema which adapts over time: Fauna's data model and schema management system should support flexible application development. Constraints should be gradually adoptable and capable of evolving over time with the application. It should always be safe to introduce change without affecting existing workloads in an online system. It should be possible to manage schema alongside application source, with the database itself functioning as just another deployment target.
Fauna's key innovation in this space then is not that FQL is just a better language for operational use-cases, or that Fauna's refined, document-relational data model is more flexible than pure relational tuples. Rather it is in how Fauna's design rethinks how the components of the database system work together, providing a better, holistically simpler way for developers to integrate their application with a backend database which takes advantage of advances in system architecture and development practices.
While SQL databases have been with us for a long time, ultimately Fauna shows that there is a better way, which preserves the best aspects of the relational model while making it faster and more efficient to build applications with less pain than before. As we will see, it is not possible to get there without making significant changes, but that there are clear advantages to doing so.
In the rest of this post, we will walk through the problems highlighted above and discuss the workarounds that exist for traditional SQL databases and how Fauna solves them.
- Stateful connections vs transactional requests
- A database language like a programming language
- Document-relational: model for schema which adapts over time
Stateful connections vs transactional requests
SQL databases use sessions to group multiple individual SQL statements into transactions. The client starts with BEGIN, issues some number of statements, followed by COMMIT or ABORT. The main benefit of session transactions is that application code can affect transaction outcome. The drawbacks are many, stemming the fact that sessions make the entire client-server interaction stateful.
Database Connections: an expensive, scarce resource
To start, connection lifecycle management suddenly becomes a performance and availability issue and a source of much complexity. Clients cannot trivially multiplex transactions across a smaller number of connections since one connection may be in the middle of a transaction. To make matters worse, most traditional SQL databases use a thread-per-connection or process-per-connection model, making connections a scarce resource. The seasoned backend developer will have certainly encountered connection scaling problems resulting in latency--or worse--general unavailability.
Connection-based communication also complicates database integration with cloud-based compute. It was already difficult with manually scaled clusters, and that difficulty has only ramped up as compute has gotten more elastic, starting with auto-scaling VMs, through first generation serverless, and ultimately edge platforms, to the point of becoming practically impossible to solve in the context of traditional databases.
There are workarounds, of course: Caching can offload certain requests from the database entirely at the cost of lower consistency. Connection pooling can allow for some resource sharing for read only workloads and simple one-shot transactions. However none of these workarounds can compensate for the fact that in part due to the complexity added by sessions, database connections are an expensive, scarce resource, and can even be exhausted by trivial write workloads at a high enough scale3.
It is not just connections that are scarce: Records themselves can become a source of contention, which session transactions, due to their open-ended nature, make worse. Consider SELECT FOR UPDATE: Without careful use, it is a source of deadlocks, and even in the best case it can cause increased latency or intermittent unavailability if a client locks some number of records and then goes away (maybe the app suffered a GC pause, or maybe the VM crashed unexpectedly).
Compounding the above issues, the back-and-forth of session transactions creates a complex coupling between application and database, making it more difficult to understand the true cost of a transaction. Is a given statement independent or does it exist within a transaction block? When will this write actually occur? If this statement fails, what else will? Throughout our careers, many of us at Fauna have experienced numerous bugs and production outages resulting from the mismanagement of session transactions4.
Compensating for all of the above is a difficult challenge, requiring many years of hard-won experience on the part of the developer--involving pain not only for themselves but also customers--in order to understand how to use SQL transactional features safely. Even with careful development practices, in the context of a large and ever-evolving application, the complexity of SQL transactions inevitably leads to subtle bugs, difficult to understand interactions, and scalability issues for which the only workaround is constant vigilance, subject-matter expertise, or plain avoidance of some of SQL's most useful features, at least on paper.
Fauna: all transactions, no connections required
Fauna's solution for this is simple: Fauna's communication protocol is based on straightforward HTTP request-response. Every request to the system is exactly one strictly serialized transaction which includes the entirety of the transaction's logic. There is no need for stateful connection management, and as transactions are entirely self-contained requests, the resulting client-server relationship is much easier to understand and scale.
// The classic account transfer transaction, which is dispatched to Fauna
// as one request. The equivalent SQL transaction must be at least three
// separate queries.
await client.query(fql`
let account1 = Account.byId(${id1})!
let account2 = Account.byId(${id2})!
let amount = ${amt}
if (account1 == account2) {
abort("transferor and transferee cannot be the same account")
}
if (account1.balance - amount < 0) {
abort("insufficient funds")
}
account1.update({ balance: account1.balance - amount })
account2.update({ balance: account2.balance + amount })
`);The impoverished nature of SQL as a database language
As stated above, SQL is a query language. The key characteristic of SQL is that everything is a table. Every SQL query starts with one or more source tables, manipulating and transforming them into a single table of results. From the standpoint of language design it is extremely elegant. And over the course of years, the table--or relation as referred to in Codd's original design of the relational model--has proven to be a highly robust abstraction upon which to build a query language.
However, this design has its Achilles' heel: SQL does not have the expressive power5 to support all that an operational database needs to as an application backend:
- It cannot encode conditional control flow, nor is it generically composable6.
- The table, being a collection of uniform rows, is limited as a response format in its ability to accurately represent data in a relationship preserving way.
Another way of stating this is that applications must be able to combine individual statements with control flow in order to build transactions, and they must also be able to combine individual queries into a larger result shape conforming to the application's needs.
It so happens that session transactions are SQL's answer to these limitations, but despite the added complexity of session transactions as discussed above, the resulting combination is still inadequate.
SQL's imposed limitations on application architecture
Ultimately, the problem with SQL's solution comes down to the latency and resource overhead of individual queries. Developers are forced to respond in two ways: By reducing the distance between app compute and the database to eliminate as much latency as possible; and by contorting application code to work within the limitations of SQL's tabular response format with the goal of reducing the number queries overall.
The pressure to reduce latency between the application and database, along with the need for careful connection management as discussed above, places severe constraints on application architecture. General scalability becomes more difficult and it can be impractical to adopt modern architectural patterns which leverage serverless and edge-based compute technologies.
The impedance mismatch between applications and SQL results
Even with efficient communication overhead, the need to reduce the number of round-trips between the application and database is unavoidable, especially in the context of application read requests. This is where the limitations of SQL's response format come in.
Consider a relatively simple case, where the application needs to retrieve a set of records of some type, each of which has an associated set of records of a different type, say a list of blog articles with the top comments of each, or a list of recent orders along with the items within each order.
It's relatively easy to write the SQL query to join the two separate tables together and the information we need, but right away we run into the classic object-relational impedance mismatch problem. The natural representation of the result data within the application--and for humans as well in a UI--is an object graph or tree. However SQL represents it as one large result table, requiring the application to re-map back to the original entity graph every time. This is complex as well as wasteful in terms of compute and communication overhead since the SQL result contains duplicate, denormalized data.
Of course, ORMs have been offered as a solution for this specific case for a long time, but ORMs bring their own set of problems: ORMs can generate convoluted, inefficient SQL. They hide where database requests actually occur, leading to issues like the N+1 queries problem7 or "feral concurrency"8. If nothing else, introducing an ORM adds another layer of complexity to the application stack, making behavior, bugs, and performance more difficult to understand.
Other query languages have solved this composition problem--notably GraphQL--and FQL works similarly. In GraphQL, queries are written as a pattern against a typed graph. FQL takes advantage of its natural composability to emulate the same behavior. In both cases, our hypothetical GraphQL API and Fauna return a result which already conforms to the native data shape of the application.
FQL takes read composability further, allowing for patterns that are impossible to express in a single SQL query. It is trivial to combine multiple otherwise unrelated queries into the same database request, preserving the shape of each.
This straightforward set of features unlock powerful architectural patterns within the application. Since FQL queries are generically composable, FQL query snippets themselves can be treated as modular, independent components which combine together in dynamic ways. This pattern is natively supported by Fauna client libraries and the database itself, and provides the same developer ergonomics that come from an ORM, if not more, with far fewer layers and vastly simpler database abstraction from the point of view of the application developer.
// An example of a tree-based "join". Start by constructing the basic
// shape of the query.
let user = User.where(.username == "alice")!
let posts = Post.where(.author == user)
.order(desc(.createdAt))
.map(post => {
post: post,
comments: Comment.where(.post == post).order(desc(.createdAt))
})
// Return a composite structure containing the user's basic profile,
// along with a timeline of their posts and comments. Client-side,
// "posts" will be a result set which supports cursor-based pagination.
// Within each post object, the "comments" object will be a result set
// as well, which can be independently paginated. FQL's projection syntax
// allows precise control of the final included data.
{
user: user {
name,
avatarUrl,
bio
},
posts: posts {
createdAt,
text,
comments {
createdAt,
text,
author {
name,
avatarUrl
}
}
}
}A database language like a programming language
Fauna's combination of a database language with a straightforward request-response transaction model is already cognitively simpler, more expressive, and more efficient than what the standard SQL interface can provide. These advantages of Fauna and the corresponding limitations of the relational database's transaction model are intrinsically tied to language characteristics, and it is impossible to address them without significantly altering the language involved.
However, even in the context of its main purpose as a relational query language, SQL leaves a lot to be desired. Much has been written about SQL along these lines by others9,10,11. Rehashing these arguments is out of scope for this post, but it is worth at least outlining the scope of the major issues.
Syntax
In contrast to the simple elegance of the relational model, SQL is a complex monster of a language. The core SQL spec has ballooned in size, from just under 700 pages in SQL 92, to over 1700 pages in SQL 202312. Implementing the full SQL spec is such a herculean task that it is unsurprising no relational database system has ever managed it. It is not merely a matter of having a lot of complexity at the edges: Consider the SELECT statement, PostgreSQL's definition13 of just the syntax is 40 lines long, with at least that many separate clauses, each with their own distinct way of writing them.
The major reason for this bloat is a fundamental flaw in SQL's original design. SQL was initially called SEQUEL, standing for Structured English QUEry Language, and the intent of its english-like syntax was to make the language more approachable to analysts and non-programmers. Unfortunately, like other languages such as COBOL or AppleScript, SQL failed pretty spectacularly in this regard. It turns out that English, with its inconsistent, idiosyncratic syntax makes for a terrible programming language.
In the long run, this has led to all sorts of negative knock-on effects including poor extensibility (another source of bloat, since non-trivial functionality inevitably ends up being extra syntax), and a lack of basic traits considered to be table stakes for programming languages in general such as orthogonality of features, or the ability to organize and modularize code through encapsulation and compositionality.
It is easy to imagine an alternative foundation for querying capabilities aside from English, one which is based on a uniform syntax similar to existing programming languages. This is what FQL provides. It has a small, core syntax, pulling from JavaScript, TypeScript, and GraphQL14. The rest of the system naturally builds upon this foundation. This design accomplishes two goals: It makes the key traits of modularity and composability fundamental to the language, and enforces a level of uniformity across FQL.
This makes it much easier to learn FQL in the first place, as well as learn (or recall) how to use new features. Developers in most programming languages are used to this: You do not have to relearn the syntax of, say Python in order to understand how to make an HTTP request or transform a data structure. At most you may have to look up the calling convention for a function or method, and quite often, autocomplete tooling accomplishes that for you. The same is true for FQL.
Debugging
SQL's syntax makes non-trivial queries harder to write than necessary, and this is compounded by the fact that SQL databases do not generally provide great feedback in the form of errors, or insight into query behavior. While it is true EXPLAIN exists, it is only really useful for understanding performance (which we will talk about later), not why a query returns the data it does.
The state of the art for debugging complex SQL queries is more or less breaking queries down into smaller subqueries and running them individually to see what went wrong. While there is certainly nothing wrong with this approach, the syntax issues of SQL outlined above cause problems with this strategy, as it can be difficult to understand how exactly a given query can be broken down into components. Nor is there any facility in SQL to emit intermediate query execution state to facilitate simple yet powerful "printf() debugging"15.
// In FQL, use logging to trace behavior within a query.
Post.where(.category == null).forEach(post => {
log("Post #{post.id} did not have a category.")
dbg(post)
post.update(.category == "Uncategorized")
})Performance
Performance in any language lies along a continuum of tradeoffs: On one end, low level languages may offer significant control over execution but they also require the developer to handle much more bookkeeping and minutiae. On the other, high level languages have a lot of expressive power, but rely on aggressive optimization in order to achieve practical performance, which only affords indirect control to the developer. The difference between optimized and unoptimized can be large, and it is often difficult or impossible to predict from a snippet of code whether or not its performance is adequate.
SQL squarely lands on the high level end of the spectrum. For analytics use-cases, this is usually the right choice: Better to emphasize clear query code based on the data's natural attributes and relationships between entities. However, for operational applications where latency is of paramount concern, SQL's design leaves developers in an awkward position. It would be better to be predictable such that the developer can easily understand how their query will execute, as well as provide language affordances allowing for control of execution behavior based on the developer's knowledge of their application domain.
The cost-based query optimizer (or planner) at the heart of the classic SQL database makes this problem worse. In contrast to say a compiler which makes a set of optimization decisions ahead of time, the query optimizer continually adjusts its plan over time. This sounds on the surface like a great idea: As the dataset changes, the system will adapt. But the optimizer can make the wrong choice, and since it is constantly readjusting, it can make the wrong choice at very unpredictable times16.
It is not as if the typical SQL database is magically performant all the time, either. The developer or DBA still has to spend the time to understand exactly how the database will most likely execute the query (using tools like EXPLAIN), adding indexes or adjusting the query accordingly. It is an indirect process at best.
In FQL's design, we chose a point on the performance spectrum more aligned with the operational use-case. Even more important than being fast is being predictably fast. The developer is still required to understand what their access patterns are, but indexes are opted into explicitly, rather than hoping the query planner decides to use one. High level, declarative access is possible, but so is control.
FQL's index API is a good example of this. It is easy to start with declarative queries in order to quickly arrive at a desired behavior. Once performance becomes a concern, Fauna, like SQL database, requires adding an index in order to optimize data access. However in FQL, you must then call the index directly. The advantage is in terms of clarity. It becomes straightforward to understand by reading query code what is optimized and what is not.
In the end, this allows development teams to design access patterns, measure performance, and then encode them in source, so that they do not change out from underneath.
// Add supporting indexes to the User, Post, and Comment collections
// with the right predetermined order and data coverage.
collection User {
index byUsername {
terms [.username]
}
}
collection Post {
index userTimeline {
terms [.author]
values [.createdAt, .text]
}
}
collection Comment {
index postTimeline {
terms [.post]
values [.createdAt, .author, .text]
}
}// Update our original profile query.
let user = User.byUsername("alice")!
let posts = Post.userTimeline(user).map(post => {
post: post,
comments: Comment.postTimeline(post)
})
{
user: user {
name,
avatarUrl,
bio
},
posts: posts {
createdAt,
text,
...Document-relational: A model for schema which adapts over time
Modern applications are dynamic and ever-changing: Contemporary software development is widely based on iterative agile practices. However SQL predates the proliferation of iterative software development practices by at least two decades. At the time it was introduced, software development was dominated by waterfall processes.
The classic SQL database is a relic of this time. Its reliance on exclusively structured data means that the schema for an application requires significant upfront design. When change is required, as it inevitably will be, the operational work required can be nontrivial: As an application's dataset grows larger and depending on the system, many schema modifications become impossible without downtime or involve complex operational gymnastics.
Combined, these traits make working with database schema a daunting task up front and full of frustrating compromises down the road. Changes to the database become a drag on development.
Engineering organizations have responded to this by placing the responsibility of database management in the hands of specialized database administrators who are tasked with enacting difficult production changes. However the legacy of this working model has grown to be in direct conflict with iterative software development and the advent of flexible cloud environments.
Agile development was only the start: Devops has become mainstream, and engineering teams have become responsible for management of their own operational environments. The rest of the application stack has modernized accordingly: Continuous integration and infrastructure-as-code deployment pipelines driven by version control systems have become a standard part of the software development toolkit, yet database management has largely been left out.
Fauna addresses these problems through a combination of a flexible, semi-structured underlying data model, and a system for schema enforcement that can be incrementally adopted and is built around the idea that schema will change over time (and moreover that this change will occur in the context of an online application).
Fauna's document-relational data model refers to the fact that entities in Fauna are stored as tree-structured documents. In contrast to pure relational tuples, documents support richer entity-level structure that maps much more intuitively to how data is organized within typical applications. While it is usually possible to define a relationally pure tuple-based schema which maps to what the application requires, documents generally make it much easier to do so. (And unlike pure document databases, Fauna's nature as a relational system with strongly consistent ACID transactions means that traditional relational schema design is still readily available.)
Evolution of the SQL ecosystem itself acknowledges the value of document-structured data with the addition of JSON to the SQL 2016 standard (and PostgreSQL before that). JSON support in SQL is a far cry from true support for documents as an integral part of the design of the system, as is the case with Fauna. JSON support in SQL is peripheral to its implementation of the relational model and limited in terms of both constraints on JSON structure and datatype support.
Layered on top of Fauna's representation of entities as semi-structured documents is a schema system that can be applied gradually and evolve in the context of an online application. The primary method for defining schema in FQL is through declarative constructs which capture the desired, current state17. Schema definition syntax is intentionally modeled after data structure and class definitions in general purpose programming languages. The process for introducing schema modifications in production environments is similar to deploying code changes to the application layer. Additionally, schema changes which require changes to physical data (such as adding an index) run asynchronously.
Fauna's document-relational data model and schema management build upon FQL's development-oriented design and its robust distributed architecture18 in order to allow an application to remain agile throughout its lifecycle. While working with persisted data is innately more complicated than purely stateless code, Fauna's overall design makes it as streamlined as possible, bringing it in line with how the rest of the application is managed.
Conclusion
Operational applications have been built on classic SQL database backends for a long time. The relational model has endured for good reason given that it provides a solid, mathematical foundation for database systems. However, over this time we have taken for granted the limitations of SQL and the resulting complexity which has grown around the SQL-based operational application stack.
Fauna and FQL combine the benefits of a developer-focused database language with the relational model and flexible semi-structured document data. The result is a simpler, more powerful foundation on which to build applications. To make this possible, SQL is the one thing that we had to leave behind. But once you start working with FQL, you won't miss it.
You can find out more about Fauna and FQL here.
References
- Stonebraker 2005 - What Goes Around Comes Around
- Relational AI's Rel language
- Connection pooling itself comes with the risk of crossed wires and mixing up statements from unrelated transactions. Developers can misuse clients, or process-based connection poolers (such as pgbouncer for Postgres) can misinterpret SQL statements.
- A memorable production incident was when a service's production PostgreSQL database started experiencing connection starvation due to periodic storms of transactions consisting only of a BEGIN followed by a COMMIT statement. These storms were highly correlated with intermittent increased latency enqueuing to RabbitMQ as part of the application code. How, you may ask, could these possibly be related? It turned out that the application framework was wrapping every request in BEGIN and COMMIT in order to make every request atomic by default, leading to RabbitMQ becoming part of the database transaction lifecycle!
- Expressive power
- While it is true that the vast majority of SQL databases support procedural logic, it is limited to stored procedures and UDFs which must be defined ahead of time and bypass SQL's inherent limitations on response shape, which we will discuss below.
- N+1 problem
- Feral concurrency
- Against SQL
- Why SQL syntax sucks, and why it matters
- A Critique of the SQL Database Language also see this great interview with Chris Date from 2014
- In comparison, the ECMAScript 2021 spec is 879 pages and the C++ 2020 spec is 1853 pages.
- PostgreSQL SELECT documentation
- As of writing, Fauna's entire FQL/FSL parser module is around 2000 lines of code, compared to PostgreSQL's Bison grammar, which is almost 19000 lines long.
- “The most effective debugging tool is still careful thought, coupled with judiciously placed print statements.” -- Brian Kernighan, “Unix for Beginners” (1979)
- The situations which lead to this sort of heuristics failure tend to be ones where the cost model the optimizer uses cannot adequately capture the application domain, leading it to make the wrong choice. A good example might be a JOIN in a multitenant app predicated on a tenant key. The developer knows the importance of tenants, so starting with an index partitioned by tenant key is always the right choice. However the database itself cannot know that for a fact and can wind up choosing the wrong index or table to start the JOIN off with.
- Ironically, where SQL queries are declarative, SQL's data definition language is fundamentally imperative.
- These systems are detailed in Fauna's architectural whitepaper
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.