

What is a Document Database?
Nov 9th, 2020|
Categories:
DocumentDocument databases or document-oriented databases are a particular type of NoSQL database whose very name indicates what they store: documents. Or to be more precise, such databases store hierarchical collections of keys and values as “documents”, each of which has a guaranteed unique identifier (ID) that allows its entire contents to be retrieved quickly. They have become one of the more popular types of non-relational databases in use today for a variety of reasons.
More traditional relational databases conceptualize different data types or “entities” using tables, much like a spreadsheet. One can easily imagine a table/spreadsheet of customers, each row having a unique customer ID, first name, last name, etc. The columns are relevant to every customer, which is why a table of customers is so convenient.
It becomes more complicated, however, as soon as we need to track other information for the customer which can’t fit easily into columns in a single row, such as the orders one might place at an online store. That doesn’t fit into the set of customer columns at all. This is exactly the sort of problem relational databases solve because they make it possible to create a separate table with completely different columns for orders, linking the two via the customer’s unique ID.
In contrast, a document model keeps all the data for a single customer in a single document, without worrying about “columns” at all. One document might have a great deal of information for a given customer, including all his orders over time, yet have comparatively little information in a different document for another customer.
Such a document model is both intuitive for the digital age and more flexible for developers, as any amount of hierarchical data can be stored in a single customer document without worrying about structure ahead of time. Whereas relational databases were invented (in part) to enforce rigid structure, document databases were invented (in part) to solve the problems that stem from it.
But just like their relational cousins, document databases also make it possible to query data easily. For example, finding a customer with a particular last name is simply a matter of asking the document database to provide only the documents whose last name property matches the desired value.
These differences can improve developer productivity significantly by letting the documents’ data grow in whatever ways make sense over time, without requiring a schema up front or worrying about changing it over time. This makes it easier for the system to evolve as a whole and simplifies scalability as well. Distributing copies of the data becomes much simpler, after all, when a given customer’s entire record is in a single document, not broken across and referenced by a potentially huge set of tables. These reasons and others, as we’ll see, are why document databases have become the most popular alternative to relational databases in recent years.
In this article, we’ll compare document databases and relational databases in more detail, explain the advantages of document-oriented databases, provide some examples of good use cases, and then offer some specific suggestions for choosing a document database to meet your needs.
Comparing Document and Relational Databases
Let’s start with a bit more detail on relational databases and how their approach to storing data differs from document databases. As mentioned previously, relational databases store data in different tables defined by developers. In effect, a schema for the data must be known and created in advance. The schema defines all the important entities in the system and the only valid relationships allowed between them right from the outset. This breaks down or “normalizes” data across multiple tables, the linking of which can become extremely complicated for different relationships.
Consider a typical online store. A traditional relational database schema for tracking customers and their orders might look something like the following illustration:
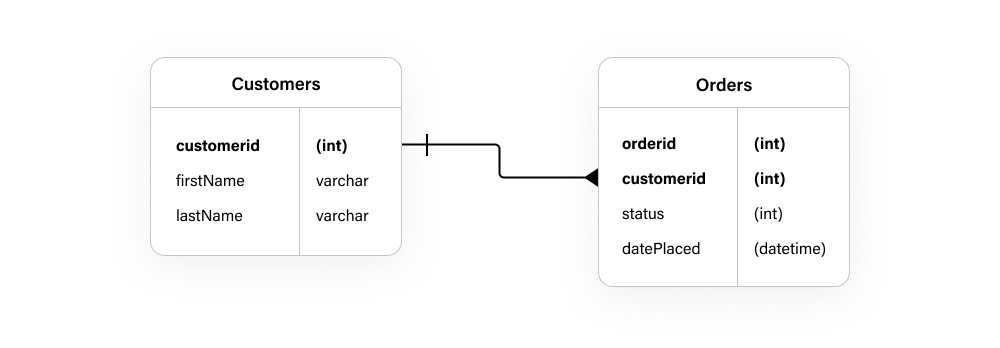
This is a standard type of database diagram, which shows a customers table linked to an orders table in a ”one-to-many relation,” meaning we can track many orders for each individual customer. The details for each different type of entity are stored in various columns. For example, each customer row has a unique identifier (customerId), the customer’s first name (firstName), and last name (lastName). A real-world application would of course have many more columns.
Similarly, each order placed by a customer is stored in an orders table, which not only has a unique identifier for the order (orderId), but is linked or related to the customer by the inclusion of a single customer’s unique ID (customerId). Other columns for our sample order include details of its status (status) and the date it was placed (datePlaced).
In contrast, a document database might store exactly the same data in a completely different, simpler, and more flexible format: each customer being a single document of the sort described earlier. An example of such a document is provided below, encoded in JavaScript object notation (JSON), which is a popular format used by many document databases:
{
"_id": 1,
"firstName": "Major",
"lastName": "Consumer",
"orders": {
"status": 1, "datePlaced": "06/30/2021 09:23"
}
} The top-level “curly braces” signify the beginning (‘{‘) and end (‘}’) of a complete object, which has several top-level properties in key-value pairs or KVPs. For example, the document itself has a unique ID (id), as well as the customer’s first and last names. But notice how the orders are handled: they are contained within the top-level object _as a nested object with its own “curly braces” and KVPs therein.
Using such a flexible structure, information may be nested as deeply as required, which does away with the need for a rigid schema. The customer’s document may simply be modified over time as needed, becoming as simple or as complex as developers require.
The practical implications are enormous from a development and operations perspective, in large part because of the way relational databases handle change. Adding new tables or columns of information to a relational database requires changes to its schema, which typically means executing a series of scripted commands against the relational database.
It’s not uncommon for development teams to need multiple such scripts for the changes in any given release of their software, all of which must be run in the proper order and succeed before the next script can be run. And of course, such scripts must themselves be versioned, tested thoroughly, and go through all the other stages of the development pipeline.
In contrast, developers working with document databases can simply add additional objects/KVPs into the documents to represent new fields. Document database systems are designed to accommodate largely arbitrary information in the hierarchical format already described, so changing that information is trivial by comparison.
Advantages of Using Document Databases
An obvious advantage of the document database model is how intuitive it can be compared to a relational model. Whereas entire college courses are taught on the rules used to break down or “normalize” data into a proper collection of tables and relations, the notion of storing hierarchical objects and their properties is far simpler.
Developers these days are used to working with the notion of objects that have properties, which may contain or reference other objects in hierarchical fashion, so making the leap to documents that store hierarchical collections isn’t a stretch. In this sense, it might be said that developers using document databases can focus on the actual data entities, rather than worry how to force them into a rigid, tabular structure.
Another clear benefit is that developers don’t need to generate a schema in advance or worry about the details of maintaining it over time. This simplifies not only up-front development but also ongoing maintenance, data backup, data migration, etc. They largely make painful schema updates, and the down time to apply and/or debug them when they fail, a thing of the past.
It’s worth noting that the need for a schema up front before you store any data entails the rather unpleasant requirement that developers need to know all of the data that will ever be stored in advance, at least if they want to avoid schema changes. But as many software developers (and unhappy managers) can tell you, the designs at the beginning of a project rarely match the implementation produced by its end. And each of those changes along the way will typically require schema update scripts and all the headaches they bring.
In short, it can be quite a burden just keeping the database schema up to date for customers in the field. Document databases largely do away with that, allowing the information stored to vary from document to document and change as needed.
Another advantage is that document databases were built from the ground up with scaling and distribution in mind. Traditional relational databases were originally intended to run on particular servers behind a given organization’s firewall, not to spread information around the world through a public cloud. Relational databases have changed and evolved over time, of course, but their fundamental design complicates scaling and distributing/replicating data due to the way they split information across many tables.
In contrast, each document in a document database is effectively an island unto itself, a single unit independent of every other document. Distributing them across multiple servers is as simple as storing different documents in different places, without any need to break up their data. This makes it far simpler to scale systems up or down to meet changing demand while distributing information to servers around the world.
Document databases also offer powerful querying and other operations. Developers can make sure properties used often in queries are indexed for high performance, perform complicated ad hoc matching queries via simple query-by-example syntax, leverage a variety of operators to find properties with values that fall in a range (or fulfill other requirements/functions), aggregate data in real time, etc.
Developers working with relational databases often must spend significant time precisely structuring their queries, as working with multiple levels of normalized data at once grows complicated rather quickly. In contrast, document database queries don’t need to worry about how to join tables together and can instead focus on which properties are important and what their values should be.
Examples of Document Databases
Now we turn to some good use cases for document databases, first among which is what we’ve been using all along: e-commerce. Managing catalogs containing many different types of products, each of which may have completely different relevant information, is an obvious candidate for document databases.
In fact, it was largely the rise of huge shopping websites that drove the industry. The need to return a web page to a customer as fast as possible was also one of the key reasons. Because their data structure is simpler, document databases typically out-perform relational databases in terms of sheer speed. When you’re aggregating dozens or even hundreds of database calls to show a customer a page filled with many products, response time is crucial.
Blogs, micro-blogs, video serving platforms, and content management systems more generally are another strong use case. Not only does the type of information stored lend itself well to document databases and their flexibility in structure, the need to update such data while avoiding down time during updates or scaling is also a significant factor.
Content can be broken down across multiple servers (or merged back together) more easily when each item/piece is effectively its own document. Again, the flexibility of document databases, and the fact they were designed from the ground up for distribution and scalability, can be very helpful.
And of course search engines, or really any information-retrieval system, can benefit for the same reasons. Document databases can store and manage largely arbitrary amounts of data, metadata, etc., and serve it up easily via the aforementioned powerful querying features.
Spin Up a Document Database for Free
In this article, we’ve discussed how document databases can provide significant advantages for a variety of applications. As software architecture increasingly favors microservices, REST APIs, and the like, developers will be increasingly dependent upon document databases that offer the flexibility and performance required for today’s applications.
Fauna is a modern, document-centric Data API that supports document, key-value, and even graph-style queries via its proprietary language called FQL (Fauna Query Language) as well as GraphQL. And unlike many other document databases, Fauna provides relational capabilities as well, such as serializable transactions with ACID properties (Atomicity, Consistency, Isolation, and Durability), relations, advanced indexing, and the ability to execute business logic close to your data.
In short, Fauna offers the best of document databases without giving up the more traditional relational features for those who need them. Finally, Fauna is free to sign up, easy to get started, and offers clear and simple pricing—pay only for what you actually use. If you think Fauna could manage document-database information for your application, why not give it a try today?
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.