

What is change data capture?
Roel Peters|May 31st, 2022
Many organizations rely on technology that processes data in real time. Whatever the context—whether it’s ridesharing, aerospace, or delivery services—they all use streams of data to monitor their processes, equipment, and operations.
That’s in stark contrast to batch jobs, which process data in large chunks, often daily. These jobs are widespread in use cases where tables from a production database need to be duplicated for analytical querying in an enterprise data warehouse (EDW). But many organizations’ operations are still triggered by a batch job—a delay caused by the design of many IT solutions.
One way to get rid of batch jobs is via change data capture, a software process to track changes in a database so an application or user can take action on them later. In this article, you’ll learn about change data capture and how to use it in event streaming.
How change data capture works
Change data capture (CDC) is a data replication technique to identify and track changes in a database that publishes each database event as messages to a real-time stream. Downstream systems can consume this row-level change feed for various purposes such as analytics, synchronization, and data replication.
There are various ways that this stream is processed, but they fit into two broad categories: pull and push.
In pull-based ecosystems, the target constantly polls the source system for changes. The main benefit is that no single message gets lost, even when the target system is temporarily down. The downside? This technique introduces a delay into the system, as messages are only transmitted when the target system asks for them.
Push-based systems, on the other hand, broadcast messages to target systems. This system is truly in real time because the source system doesn’t need to wait for the target system’s request. But this also implies that messages aren’t guaranteed to arrive at their destination if the target system is down.
It’s possible to enjoy the best of both worlds. With a message queue or stream processing platform, messages can be transmitted by sources and consumed by target systems in real time. To guarantee messages aren’t lost, they are stored in a queue. When the target is offline and messages aren’t consumed immediately, they are stored for a specified amount of time or until the target is back online.
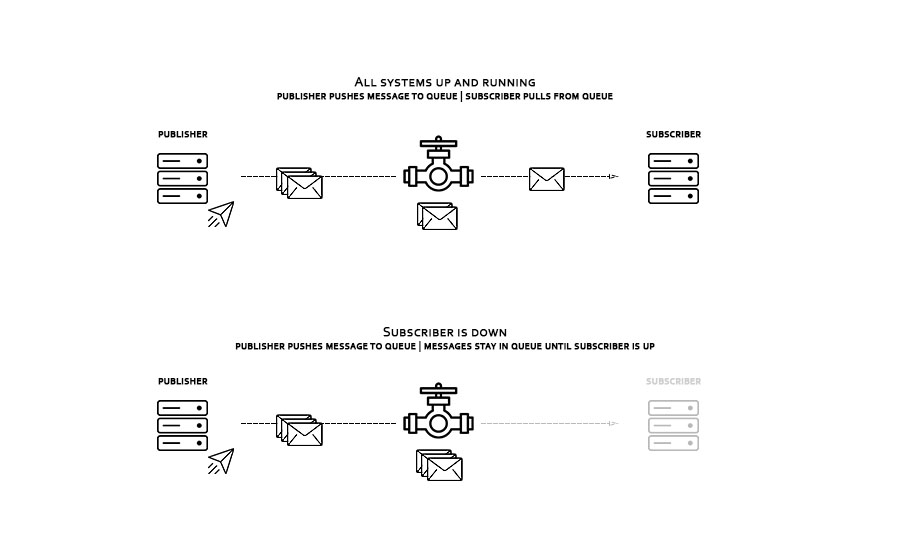
Why should you use change data capture?
Change data capture offers many benefits to both developers and business users.
For developers
- Actionable individual database changes: Many applications disentangle the changes between two database snapshots to determine what action is required. However, CDC doesn’t just capture the data at different points in time; it records the individual changes. Consequently, every change to a database is immediately actionable.
- No need for ETL: To satisfy business users’ need for insights, organizations employ troves of data engineers to extract, transform, and load (ETL) data into data repositories that are optimized for analytical queries. However, if the CDC system is appropriately configured and has an enterprise data warehouse as the target, CDC can drastically reduce the need for complex batch ETL operations.
- No disruption in production systems: Setting up batch jobs to extract data from transactional databases always holds some risk. Executing queries to dump snapshots can overwhelm the production system, impacting its performance. A CDC system will only have a minor impact since its data replication effort is spread over all individual transactions.
For business users
- Faster decision-making: CDC can move data from production systems to analytical systems in near real time. There are many contexts (aviation, delivery services, ridesharing, customer services) in which real-time insights can make a difference. Instead of waiting for each batch job, decision-makers can intervene on the spot.
- Improved coordination between systems: CDC is an excellent way to keep systems in synchronization. There is no need for point-to-point integrations when all systems can subscribe to the same messages through a streaming platform like Apache Kafka, Google Cloud Pub/Sub, or Amazon Kinesis.
Use cases
Change data capture has many real-world applications, ranging from business insights to operational availability, systems integration, and compliance.
Analytics
Data engineers use change data capture for extracting data from transactional databases to analytical data repositories such as data lakes and data warehouses. Instead of setting up batch jobs to extract and load data, CDC systems can integrate with streaming platforms to move the data in real time. Software like Materialize can turn this data into a real-time overview.
Replication
Often, the same data is stored in multiple locations for better availability and accessibility. This improves its access speed around the globe and makes the application more resilient to potential system failures or breaches.
There are several data replication strategies:
- Put a replica closer to the user that processes both write and read operations
- Direct all read operations to a replica, with the original database processing more resource-intensive write operations
CDC is a time-tested method for keeping database replicas in sync. A vendor like Fauna can replicate a database and distribute them to copies automatically.
Compliance and auditing
What happens when a customer updates their residence? Is the old address stored in a
previous_address field? Does each address get a start and end date? Maybe there’s an extra table with address history? These are all valid methods for tracking changes in a database, but many organizations don’t have a strategy to capture UPDATE statements in their applications, and the information is lost.Industries like banking and insurance need an audit trail of customer profiles to be compliant with regulations. CDC software can automate this process.
Cache invalidation
When applications read data from a database, the result is often stored in a cache, especially when it’s an expensive query—meaning it uses a lot of resources. However, when the data changes, cache entries need to be removed or replaced. When multiple applications can modify data records but don’t communicate with each other, it’s hard for one application to verify that this has been done. With CDC, applications can subscribe to change events to know when their cache needs to be invalidated.
Microservices integration
You often need to orchestrate microservices when a change event happens in a database. For example, say you work for a retail company offering various benefits when families merge their loyalty cards into a family card. Your microservices need to update the standard discount, send welcome emails, and schedule card delivery. Instead of using point-to-point integration, CDC can broadcast a single message to trigger the individual microservices.
How to implement CDC
Change data capture comes in many forms. What’s distinctive is how each type of CDC tracks changes. They fall into several broad categories.
Snapshot tracking
The simplest way of tracking changes is by taking snapshots at a fixed interval and sending them to a receiving data store, where changes can be disentangled. This system is pull-based: changes are only detected downstream when a new snapshot is detected.
Pros:
- Easy to set up
- Doesn’t require extra tooling
Cons:
- Doesn’t capture intermediate changes between snapshots (many wouldn’t even categorize this as CDC)
- Not convenient to work with in the receiving data store
- Backfilling (when the receiving data store is temporarily down) isn’t possible if individual snapshots aren't stored separately
Timestamp or key-based tracking
Timestamp tracking is a straightforward way of tracking changes in a database. Every field has an extra timestamp or key field that notes when it was last updated. You can set up
SELECT queries that recurrently request all rows that have changed since the last time they ran. This is a pull-based system: changes are only detected when the target system polls for them.Pros:
- Easy to set up
- Doesn’t require extra tooling
Cons:
- Extra columns double storage requirements
- Requires extra overhead from database
- Doesn’t capture intermediate changes between
SELECTqueries - Requires extra logic to capture
DELETEstatements
Table differencing
This method of CDC looks a lot like the timestamp method. Instead of timestamp columns, it uses database utilities such as
tablediff to identify changes between two versions of a table. Source systems still have to poll for changes, so this is also pull-based.Pros:
- Comes out of the box with many database vendors
Cons:
- Negatively impacts the performance of the database
- Doesn’t capture intermediate changes
Triggers
Another simple way to track change is by defining database triggers that build a change history in “shadow tables” via stored procedures. These triggers fire before or after
INSERT, UPDATE, and DELETE commands. One could argue that this is a push-based system.Pros:
- Creates an immutable detailed log of all operations
- Fairly easy to set up for individual tables
Cons:
- Negatively impacts the performance of the database
- Creates extra overhead for tracking changes if the database has no built-in trigger configurations
Log-based data replication
Many database solutions automatically track changes via chronologically stored log files. These logs come in two kinds of formats: statement-based replication and row-based replication.
In statement-based replication (SBR), statement-based binary logs describe SQL statements. You can capture all changes by simply executing the SQL statements on the target data store.
SBR requires less storage and bandwidth because updates that affect multiple rows are stored as a single statement. However, this strategy can’t recreate nondeterministic SQL statements, such as a
DELETE or UPDATE statement that contains a LIMIT without an ORDER BY clause.In row-based replication (RBR), row-based logs contain events that explain how individual table rows are changed. All events are copied to the target data store.
Contrary to statement-based methods, RBR ensures that even nondeterministic changes are recorded. RBR requires a lot of storage space, though; it effectively writes every row change to the binary log because changes involving multiple rows contain multiple log messages.
Since statements or rows are immediately pushed to the target-system, log-based replication is push-based.
Pros (for both formats):
- Only captures changes
- Doesn’t require much overhead
- Offered out of the box by most vendors
Cons:
- Requires a lot of storage capacity
Event streaming
CDC also exists for non-tabular database systems. Fauna, a document store, has built-in event streaming capabilities. Event streaming can be compared to log-based systems. But instead of storing the logs, messages are pushed to downstream systems that subscribed to it. Document streaming is analogous to statement-based replication, while set streaming is analogous to row-based replication.
Pros:
- Captures individual changes
- In line with modern architecture paradigms
Conclusion
Change data capture can be a great way to capture real-time changes to a database. For tabular data, one of the most efficient CDC methods is log-based, resulting in a low-overhead stream with a multitude of use cases. Modern DBaaS systems even provide event streams that can drive actions in your application.
One tool to help you achieve this is Fauna, a serverless, flexible transactional database and data API. Fauna simplifies event-driven use cases with push-based document subscriptions that trigger changes to your data. You can sign up for free to see how Fauna simplifies your real-time data tracking.
Roel Peters is a data generalist with a special interest in making business cases using structured data and simulation techniques.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.