
Serverless patterns reference architectures
Systems design is one of the toughest parts of the software development lifecycle (SDLC). Software architects frequently rely on reference architectures because such tools help them more easily develop and maintain serverless and other complex systems.
Reference architectures for serverless applications are a high-level overview of how to solve a particular problem. By following them, you’re building on the knowledge of other teams and utilizing industry best practices. Because many of them were created by companies like Google, Microsoft, and Amazon, they also work well at a large scale.
Different reference architectures are available for different types of systems, such as a mobile or IoT backend, real-time file-processing function, or web application. Reviewing your options helps you to choose the best one for your use case. The added efficiency such architectures provide can also lower the total cost of ownership (TCO) for your organization. To further optimize your architectures, you can use Fauna, a distributed document-relational database that's ACID by default.
This article will break down serverless reference architectures and examine some common examples while also demonstrating how Fauna makes it easier to implement them.
Why do you need serverless patterns reference architectures?
Serverless app development can benefit from organized architectures and well-tested development techniques. Following are some of the major reasons why you should consider using serverless patterns reference architectures:
Optimized resource consumption
While serverless comes with its own share of resource-consumption cuts and cost optimization, you can take that even further by designing it correctly. Well-designed serverless apps automatically cut down on wasted execution cycles and provide you with the best performance-to-cost ratio.
If you’re trying to build a simple static web app, going with an n-tier application might not make sense; it might even end up adding overheads to your development process. Similarly, relying on a simple web app architecture for an app that scales to hundreds of thousands of users might not be your best choice. This is why you need to use the right reference architecture so that you can automatically optimize your app by relying on a tested pattern.
Event streaming and processing
The serverless model relies on invocations and execution cycles. When you choose to build your app using one of the popular serverless reference patterns, you get this feature built into your design. Each of your system’s components communicates with the others using events and messages. This enables them to work asynchronously and increases their resilience. If an invocation fails due to some bad values, the component doesn’t crash; it just records a failure and waits for the next event.
Event-based execution also offers powerful queuing capabilities. If any of your components receives an unusually high number of requests, it can queue them up and work according to its own capacity. No requests are lost, and your system won’t blow up. Patterns like the scalable webhook are excellent examples of how the right design can help you solve major problems with ease.
Trigger-based processing
Apps built using serverless patterns can take advantage of trigger-based processing techniques. Instead of a live application running on a server waiting for user requests to come in, your app becomes a hypothetical function that’s triggered when a request comes in. This request could be for anything from image compression to serving a full-fledged web app.
Serverless patterns reference architectures with Fauna
Now that you’ve seen how serverless patterns reference architectures can benefit you, here are five important architectures you should know. Additionally, you’ll see how these architectures are reinforced by using Fauna instead of traditional databases.
Building a basic web application
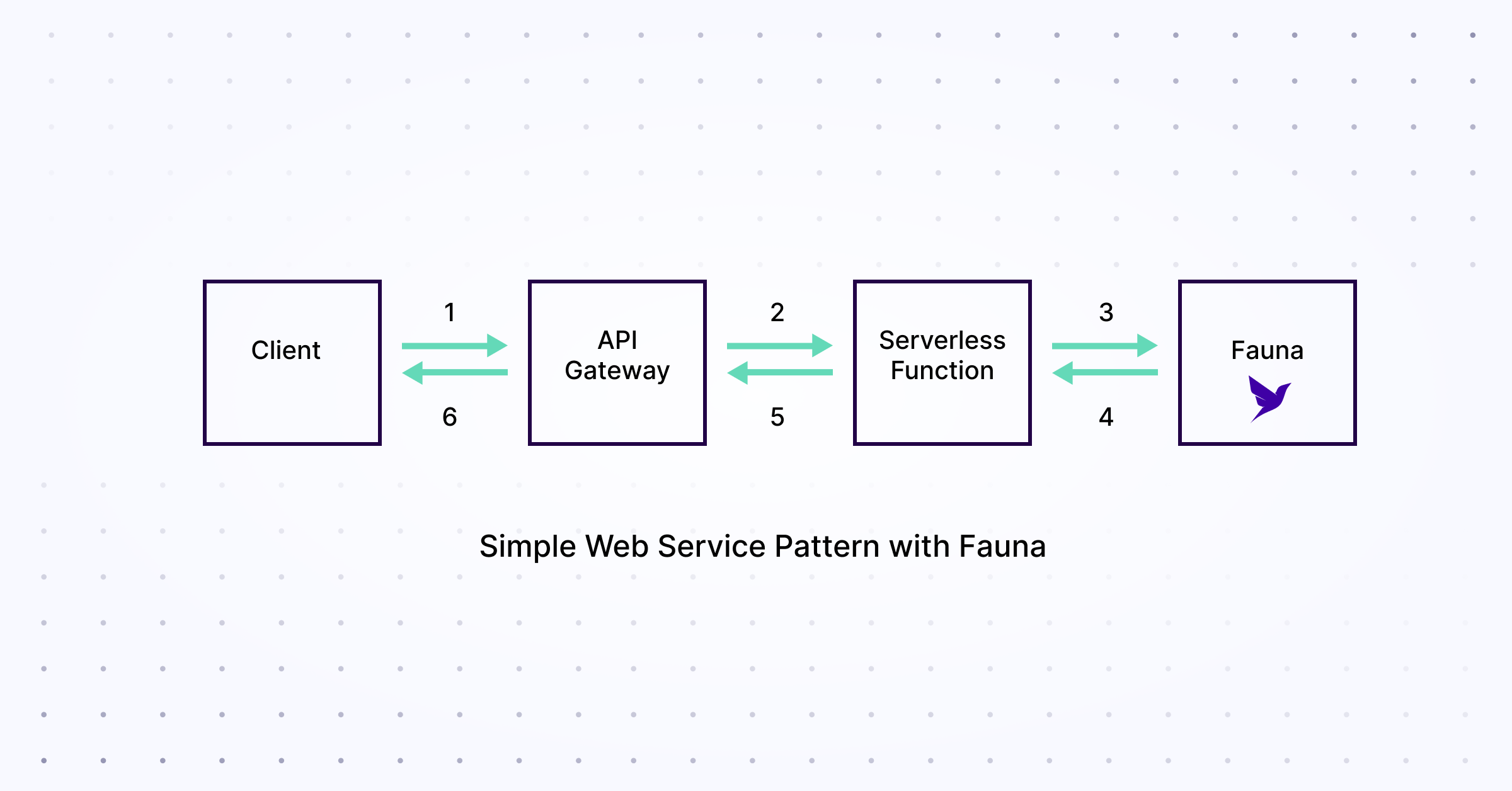
Building a basic web application that serves content to users as well as enables them to persist data into databases is simple with serverless. This is known as the simple web service pattern. Here’s how the architecture of your app would look:
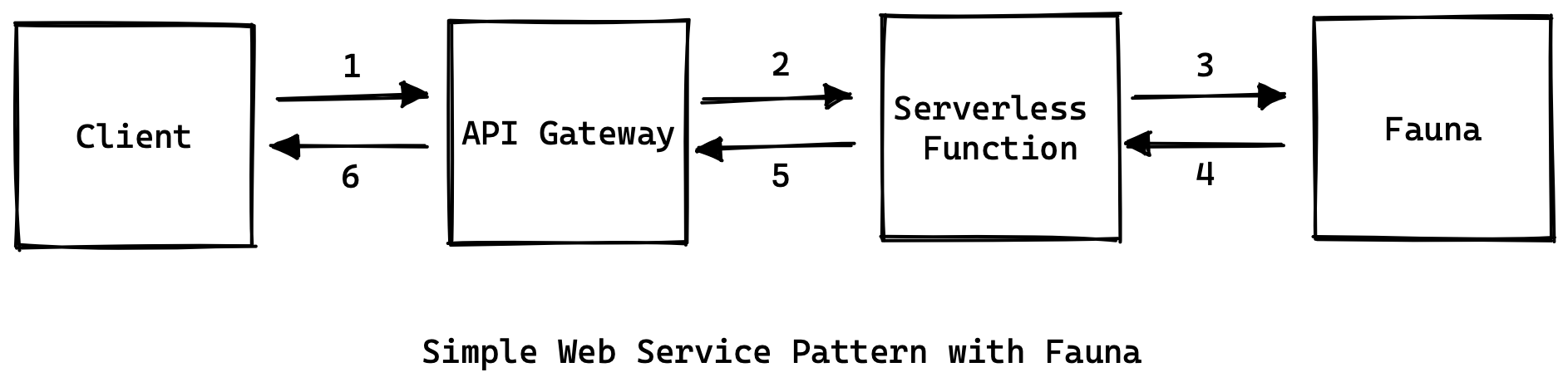
The flow here is also simple:
- Client sends a request to the app, which could be viewing the home page of the app or making a change in the user profile details.
- The request is received by the API gateway and forwarded to the serverless function.
- The serverless function interacts with the data store if necessary.
- The data store returns any required data.
- The function sends the response to the API gateway.
- The API gateway responds to the client with the request.
This is easy to implement. As with any serverless app, the serverless function replaces a live 24-7 web app server waiting to receive requests. An important thing to realize here is that to talk to a traditional database over TCP/IP, you would have needed a 24-7 web server. Lambda functions wouldn’t support it, because they spin down as soon as they reach the idle state.
Using Fauna instead of traditional databases provides you with a quick and ready-to-go database setup. If you choose to host your app on a platform like Vercel or Netlify, Fauna offers powerful integration abilities with them and can provide you with an enriched experience.
Migrating legacy applications
A common issue with application maintenance is migrating legacy apps to newer technologies. The hard part is deciding how the migration will be carried out. In many cases, it’s not possible to decommission the old app until the new app is ready. A popular serverless pattern known as the Strangler can help you in such cases.
The idea behind this pattern is to allow the developers to migrate parts of the legacy app to the new serverless tech stack. Meanwhile, the old application runs in parallel with the new growing app. Here’s how that looks during the migration process:
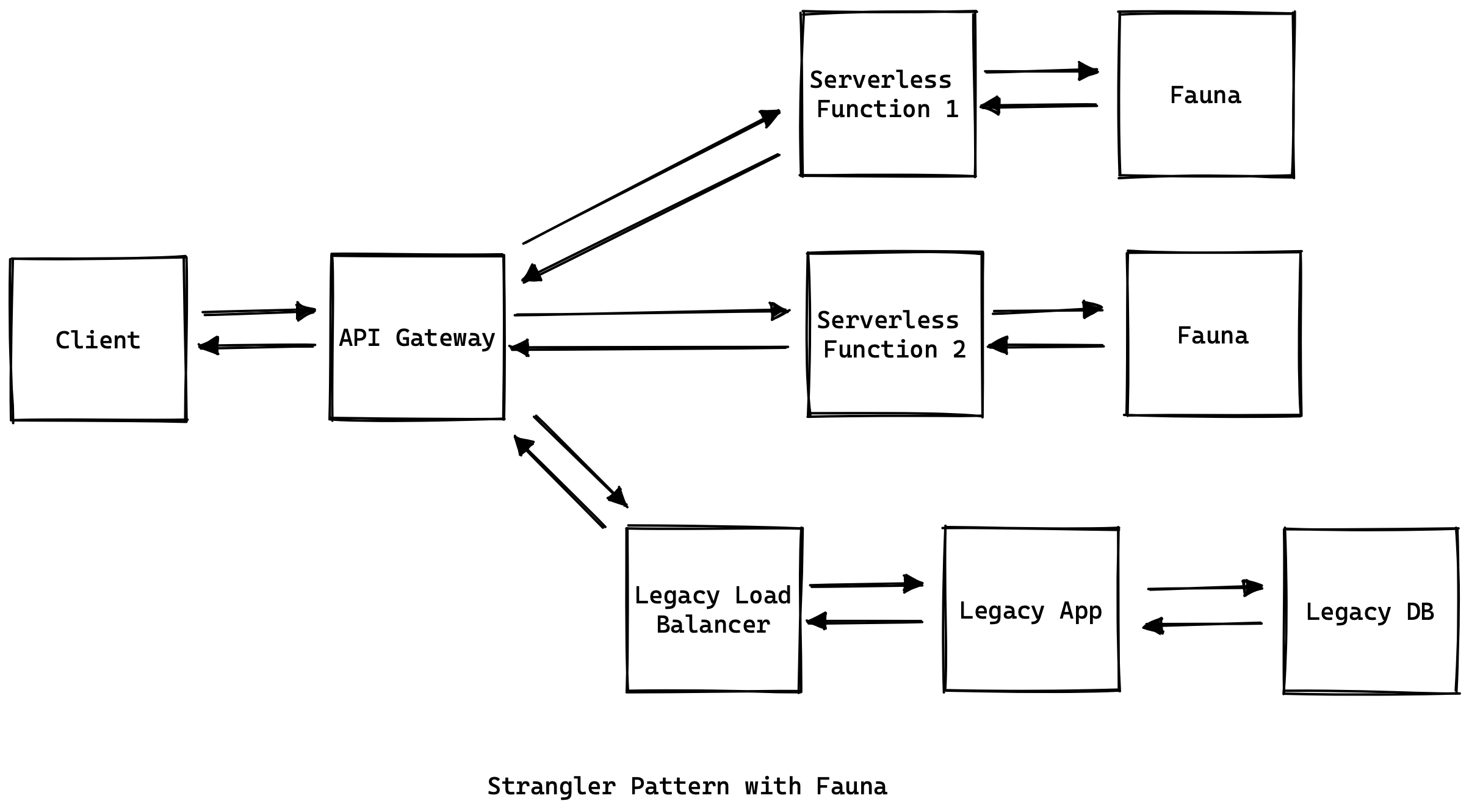
You can break down your legacy app into multiple functions while migrating it to the new tech stack, as shown by the two functions above. When your API gateway receives a new request, it knows whether to route that request to one of your new functions or to your legacy app.
The data stores can be managed independently of the migration process. Once you’re done migrating your app, you can migrate your existing database using the in-depth process laid out by Fauna, which not only migrates your data but also enriches it on the way.
Once your data is migrated to Fauna, it will be highly available to each of your functions, and it will reduce the infrastructural load from your traditional database management system (DBMS).
Handling unpredictable workloads
For many apps, user traffic varies greatly. When you’re building with traditional technologies, accounting for major spikes in traffic and workload can be difficult. However, serverless was built with scalability in mind. The scalable webhook pattern serves this use case perfectly. It’s meant mostly for high-traffic webhooks, and it relies on queueing and throttling to reduce the load on the main handlers, meaning the serverless function.
Here’s what it looks like:

Here’s how the flow goes:
- The client sends a request to the API gateway.
- The API gateway sends the request to the first serverless function.
- The serverless function adds the request to the queue and sends an acknowledgment back to the API gateway.
- The API gateway sends the confirmation back to the client.
- The second serverless function is subscribed to the queue and picks up on any incoming requests.
- The function accesses the data store if necessary, performs the required operation, and marks the request as completed.
You can have another queue component that tracks requests marked as failed by the second serverless function. Since the second serverless function is decoupled from the primary stream of incoming requests, it can moderate the rate at which it picks up tasks, also known as throttling. You can also have more than one serverless function picking up requests from the queue if there is more than one independent operation associated with them.
Fauna can help this use case by providing a single source of truth for all of your worker functions and tying them together to achieve higher working bandwidth for your service. Moreover, Fauna would work better than other serverless databases like DynamoDB for a number of reasons, such as ACID compliance and consistency.
Tracking failed API requests
Another common use case for a web service is to serve user requests while tracking those that an external API failed to handle. This data can be used to judge whether the next calls should be sent to the external API or whether the client should just get an automated failure response. This helps reduce unnecessary calls to the external API, which would still result in a failed response but would add to your costs.
Here’s what this architecture looks like:
Here’s how it works:
- The client sends the request to the API gateway, which forwards it to the right serverless function.
- Before calling the external API, the function checks the data store to see if the API has been reporting failures lately. A variable (presumably Boolean) is flipped to false in the data store if the number of failure responses from the external API has crossed a certain threshold.
- The false state means that the serverless function isn’t allowed to call the external API anymore. It returns with a failure response to the API gateway and subsequently to the client.
- Periodically, a request is forwarded to the external API just to check if it’s available again. If yes, the Boolean variable is set to true, and all further incoming requests are allowed to go to the external API.
Fauna improves this flow by providing you with a fast and easy-to-set-up data API that you can use to implement this architecture. If your clients are distributed, using Fauna gives you an edge over an eventually consistent database since Fauna is distributed and consistent by default. If this weren’t the case, a client in another region might think that the API is active when it is already marked unresponsive from a previous status-check made from a different region.
Storing data before processing
In some cases, you might want to store user data in your database or data store before you process it. Instead of waiting for your serverless functions to finish running operations on your data, you can dump it in your DB first and then let them run. This can sometimes be necessary to reduce latency in your endpoints.
Here’s what this architecture looks like:

Here’s how it works:
- The client sends a request to the API gateway, which forwards it to the first serverless function.
- The function persists the data in the data store and returns a confirmation to the client.
- The second serverless function picks up requests and their data from the data store, processes them, and then stores them back in.
Some might consider using a different data store for storing incoming requests and processed results, but that would just bring you closer to the scalable webhook pattern, in which the data store for storing incoming requests is a dedicated queue.
Fauna provides a highly available, fast, managed data-storage alternative that makes it easy for you to use it as the queue store as well as the results store.
Conclusion
Serverless patterns reference architectures can give you guidelines to follow in creating your own serverless projects, saving you both time and money as well as the headache of trying to address problems that others in the industry have already solved. You can build on the expertise of others to achieve more success with your code.
As you’ve seen throughout this article, Fauna can be an invaluable tool in this process. The serverless transactional database and data API help you create new applications or migrate and improve on existing projects while enabling easy scalability and auth integrations. Fauna offers event streaming, data imports, and distributed compute and storage, as well as other features to help with serverless reference architectures.
To see more of what Fauna can do for you, sign up for a demo.
Kealan Parr is a senior software engineer and technical writer who works with clients on technical reviewing and software development. He is a member of the Unicode Consortium.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.