Getting Started w/ Fauna: An Introduction to Background Resources
Here at Fauna we’re putting a lot of effort into simplifying the process to get up and running with Fauna. Having recently on-boarded to Fauna myself, I want to share some notes and resources which I found useful. This is the first in a series of posts to help you get started with Fauna -- even if you don’t have that much expertise in databases to begin with.
The goal for this post is two-fold. First, to level-set across a range of audiences and technical backgrounds. Second, to bring you to a place of understanding for why one would even consider a new database solution given there are so many in existence. This post serves as the foundational building block for subsequent topics we’ll cover in this series. Plus, after reading this you’ll also be able to approach our Technical White Paper’s content and with a deeper level of understanding of its significance.
A little about myself: I’m a software engineer and I don’t consider myself a “database person”. I studied Computer Science, I develop applications and I know plenty about using databases. However, I have not:
- Been a DB admin
- Had hands-on experience keeping a production database operational
- Learned the intricacies of data sharding nor what’s involved in the process or maintenance
- Compared performance profiles between low-level database operations
In other words, beyond writing queries in my application logic to read/write data and occasionally running reports, I’ve never had much regard for what happens on the other side. I.e. when I save and retrieve data, I expect it to behave just as if I were running a local database -- any manipulation to the data occurs in transactions and there are no surprises. Admittedly, I take a lot for granted with this mindset even though I know solving the problem of real-world, globally distributed environments is hard. However, I didn’t respect the challenge, sheer hassle and roadblocks that these solutions are up against enough until a deeper exposure to Fauna.
Let’s dive into some recommended resources for getting started with Fauna. To start us off, I found it helps to take a step back in order to explore how we got to where we are in the first place.
SQL vs. NoSQL*
It turns out we can grossly over-generalise all databases into two categories: the traditional “SQL” database and “everything else”*. The former is what I, and potentially you, learned back in our Computer Science classes at university, with popular examples being Oracle DB, MySQL and Postgres. Schemas, Tables, Rows, Primary/Foreign Keys, etc. are the name of the game and the result is a compact and correct relational model to store and access your data.
These were systems built in an age before the Internet; at a time when storage costs were at a premium and distributed systems were a novelty. With the rise of the Internet/mobile phones/social networks/take your pick, traditional databases couldn’t effectively keep up with the amount of data and availability requirements in demand.
Hello NoSQL, aka “everything else”. Actually, rather than a database type, I see NoSQL as more of a movement -- a response to a need from the Internet and mobile Internet revolution. But by choosing to scale at any cost, this movement sacrificed the most attractive properties of traditional SQL databases: type safety, relational integrity, and transactional correctness.
If you’re thinking to yourself that “surely correctness at scale is a solved problem”, be quick to reconsider. While there have been valiant efforts to mitigate the shortcomings of distributed and horizontally scalable databases -- elaborate caching solutions, stringing various types of DB solutions together each with different purposes, abstracting the burden of resolving collisions into application logic and API services, to name a few -- the reality is that most “solutions” are often a combination of non-holistic solutions which add complexity, cost and commit you to a particular system. Only now is there a new breed -- a third category -- of databases emerging and that’s what sets Fauna apart.
When you learn how Fauna combines the safety and integrity of transactions with the scalability of NoSQL, the takeaway is that:
Fauna offers the best from SQL and NoSQL.
It provides transactional NoSQL on a global scale. Fauna is a great fit for use cases that NoSQL couldn’t address due to fundamental architectural limitations since it lacks transactional integrity, such as banking, point rewards systems and other mission-critical applications. Conversely it provides all the scalability, flexibility, security and performance needed in the 21st century.
*Technically, “SQL” is the language one uses to interact with a relational database while NoSQL typically refers to anything that doesn’t have a relational model. So more accurately, the comparison should be “Relational vs. Non-Relational” but alas the industry’s convention is: SQL and NoSQL.
Eventual vs. Strong Consistency
In a distributed database, these are two principle models of data consistency across the distributed system. Data consistency in this context refers to the following: if one were to read a value, will that value be the same regardless of which node it originates from?
Strong Consistency is the more intuitive scenario if we think of a non-distributed system. If there is only one database, or one master node responsible for receiving all inbound requests and replicating it across several copies, you’ll get the same value regardless of which replica you read from. If you’re familiar with RAID on hard drives, this would be similar to a RAID 1 (Disk Mirroring) model.
To understand Eventual Consistency, I like this plain English scenario:
- I check the weather forecast to learn that it’ll rain tomorrow
- I inform you that it will rain tomorrow
- Your neighbor tells his wife that it’ll be sunny
- You tell your neighbor that it is actually going to rain tomorrow
Eventually everyone knows the truth (that it's going to rain tomorrow), but for a period, the wife comes away thinking it is going to be sunny even though she asked after one or more of the servers (you and me) had a more up-to-date value.
Until now, a system had to choose between these two different models, sacrificing many other attractive or critical properties of the database (or increase operational complexity) in an effort to maintain them. Choose scale, and productivity suffers. Choose productivity, and scale and correctness suffer.
Fauna offers a fully consistent solution without any sacrifices.
ACID & CAP, Calvin & RAFT
Acronyms! It’s not fair to glance over the significance of each acronym, but in a way I’ll be doing just that at this point. That’s intentional since each merits a longer discussion and therefore it’s easy to quickly find ourselves plunging into a rabbit hole which I’ll spare you from in this post. I invite you to read further into each of these concepts through links provided below.
ACID & CAP
When a database is said to be ACID, it speaks to a property of its transactions which guarantees that data integrity is preserved. Officially, it stands for:
- Atomicity: Indivisibility; either a transaction applies in full or not at all.
- Correctness: Transactions only apply if they are allowed to.
- Isolation: Any effects of a transaction is visible in full, never partially.
- Durability: A committed transaction is permanent.
Compliance with these four properties is easy to take for granted. Afterall, all four properties apply in most of our day-to-day experiences. To make an analogy when saving a text file on your local machine:
- A: You don’t expect to only see a couple paragraphs the next time you open the file.
- C: You get an error message if you’re not permitted to save the file.
- I: You expect to find the contents of the file if you subsequently search for any terms contained within.
- D: Next time you restart your computer, the file should still be there.
However, in scaled, distributed systems satisfying all four of these properties poses a very real and challenging problem.
CAP on the other hand, is a property of the database itself rather than of the transactions within. It’s actually a theorem which states that databases have three properties of which only at most two can be achieved at a time:
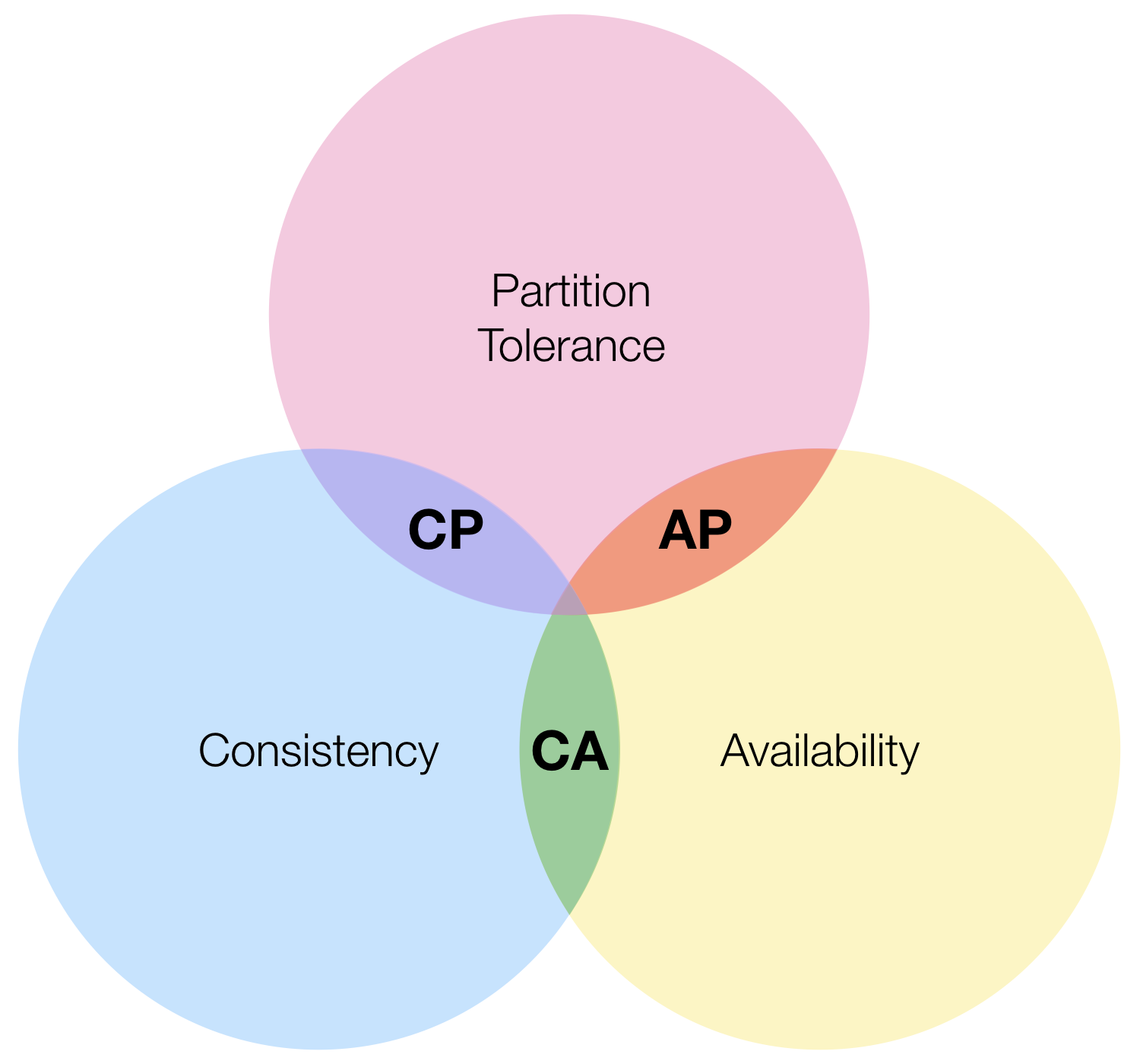
- C: consistency; a single value for shared data
- A: 100% availability; for both reads and updates
- P: tolerance to network partitions
The premise is that network partitions (failures on the network) is unavoidable in distributed systems in the real world so when they occur, a system must choose between Consistency or Availability.
Fauna chooses the former, so strictly speaking it falls into the CP group. However, network partitions -- the only real scenario in which CAP applies -- are much more rare compared to other causes of system outages. Therefore, Fauna attains the same level of availability that is practically achievable by other database systems with AP guarantees.
For further detail, I suggest reading more about these concepts in the following article: ACID Transactions in a Globally Distributed Database.
Calvin & RAFT
Calvin and RAFT refer to implementation details of the architecture and protocols which make most of what’s been discussed above possible. In short, Calvin is a transaction scheduling and data replication layer which Fauna takes inspiration from in order to provide fully ACID transactions in a distributed database system.
Fauna makes use of a distributed log for deterministically resolving the order of transactions and RAFT is the algorithm used for reaching a consensus amongst the distributed nodes involved. To further understand what RAFT is and how it works, I recommend this short write-up on RAFTand a visual understanding of how the RAFT protocol works.
No Infrastructure Lock-In
During the early stages of a business or onset of a project, engineering teams are often faced with the decision of what infrastructure to begin building on. Whether this is the database itself or simply the infrastructure to host the application, it can be a tricky choice. After all, no one can predict the future needs of a product. It’s unavoidable that conditions, requirements, capabilities, etc. change over the evolution of your product or business and soon other, more attractive solutions present themselves as much better choices.
However, in practice the overhead and costs to change systems and migrate data are too high to justify so stakeholders often learn to accept the imperfect condition and move on. This is ok -- even wise, I’d argue -- to some degree but the point is that the situation commits a product to a nonoptimal foundation. In the best case, it’s just an annoyance. Often times it adds unnecessary complexities and operational overhead. On the worst case, it can lead to the demise of a product or business altogether.
When we talk about Fauna having a no-infra lock-in architecture, we mean that Fauna can operate across different hardware and software-hosting solutions. And this doesn’t only apply to a scenario such as Fauna’s Cloud offering vs. an on-premise/Enterprise offering. You can deploy your Fauna to your own distributed machines or operate it on a number of other PaaS cloud services†… or even a combination of any simultaneously if needed.
Fauna allows business requirements to dictate infrastructure needs instead of infrastructure constraining innovation.
† All major Cloud vendors support Fauna natively (e.g. Amazon Web Services, Google Cloud Platform, Microsoft Azure) in addition to Fauna’s own Cloud solution.
Conclusion
This all sounds pretty exciting, right? Maybe even a little too good to be true? At first I shared these sentiments as well. But here’s the thing. As I keep learning more, it’s becoming clear that I’m only getting started! I invite you to follow along as I continue to share my learnings in this Getting Started w/ Fauna series. Next up, we’ll shift gears with a hands-on approach in my Fauna Quickstart Guide to get you set up and interacting with your own database in a matter of minutes.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.