
Meet data residency requirements with Fauna Region Groups
Data protection and privacy are critical in the current regulatory climate—the responsibility for keeping data compliant has fallen on the shoulders of application developers and architects. Developers must maintain high velocity, performance, and reliability of their applications while complying with regulations like GDPR in the EU and FIPS in the US. Developers must meet these data residency requirements while not introducing latency into their applications.
Fauna Region Groups
Fauna is excited to announce Region Groups to help application developers maintain the performance and reliability of databases in their applications while ensuring that data residency regulations are met. Fauna customers will now have access to distinct Region Groups where users can keep their data resident to a specific, major region of the globe. Leveraging Region Groups will enable users to:
Adhere to compliance policies
As nations and continents implement their own distinct data residency regulations, developers need to adhere to these considerations when creating their data architecture. Region Groups lets developers focus on building their applications and let Fauna take care of any data residency requirements.
Reduce latency with data closer to users
One important metric that developers consider when selecting a database is the latency it introduces into their applications and in turn how it impacts their customers. Region Groups keeps data resident within a customer-chosen geographical boundary and ensures that data is served to customers from the closest cloud region. When you create a database encompassed within a specific Region Group in Fauna, the database is immediately replicated across multiple regions within the chosen Region Group. This replication ensures that your customers’ database requests are being served from the closest cloud region while meeting data residency requirements.
Maintain data residency with high availability
Because Region Groups automatically replicate data in multiple cloud regions within the geographical boundaries, your data is also highly available. Region Groups are architected for high availability, assuring that the service remains available if any single node should fail. Fauna also takes care of ongoing maintenance and operational best practices to ensure the best possible service guarantees.
No operations necessary
Application developers can do all the above while never standing up a server, sharding databases, or trying to find the best cloud regions to maintain low latency and reliability -- all of this is done by Fauna when you create a database with our Data API.
“App developers want to focus on building the app, not worrying about regional and international regulations and restrictions, or building high availability and redundancy services across modern distributed infrastructures,” said James Governor, co-founder of Red_monk
Availability and pricing
Region Groups make data residency easy
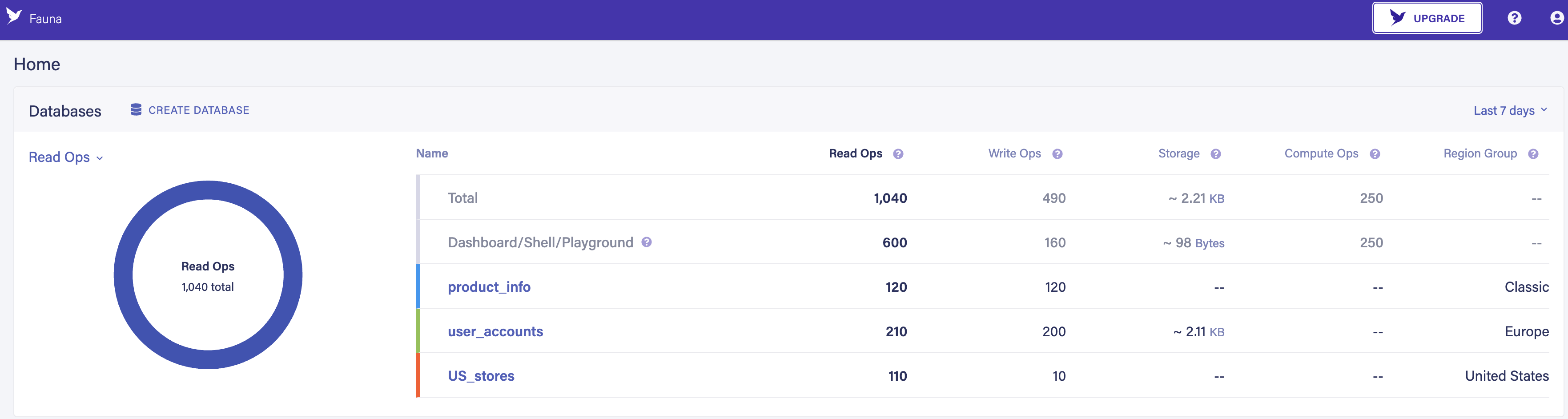
Fauna combines the benefits of distributed data with serverless scale and operations, giving you hands-free data residency within your applications. If you’re an existing user, Region Groups will be available in your dashboard today. Create a new Database, and select the region that you want your data to stay resident in and start leveraging it within your applications. The dashboard allows you to review all existing databases and the region groups they belong in. For step-by-step instructions, please refer to our documentation here.
Region Groups are available for everyone to use, including new customers. We are releasing support for Region Groups in the US and EU with more regions coming soon (fill out this form if you want a Region Group we don’t support yet). If you’re not already a Fauna user, you can get started instantly without a credit card. Register for our free plan and check out Fauna Region Groups to meet all your data residency requirements! To learn more about how Region Groups are priced, please refer to our pricing page.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.