
Reducing complexity by integrating through the database
Increasing application complexity usually reduces developer productivity. At Fauna, we’ve seen a useful technique to reduce complexity come back in style — specifically, integrating services and clients through a shared database, instead of through remote procedure calls, messages, or events.
In a modern architecture, integrating through the database is generally considered bad. We think this is no longer true in general, and especially not true for serverless architectures. But how did we get here?
State of the art
In a typical microservice or serverless architecture, the various business and presentation components message each other synchronously via GraphQL, REST, or XML-RPC calls, or asynchronously via message queues, and maintain a copy of the general application state relevant to them in their own physically co-located database.
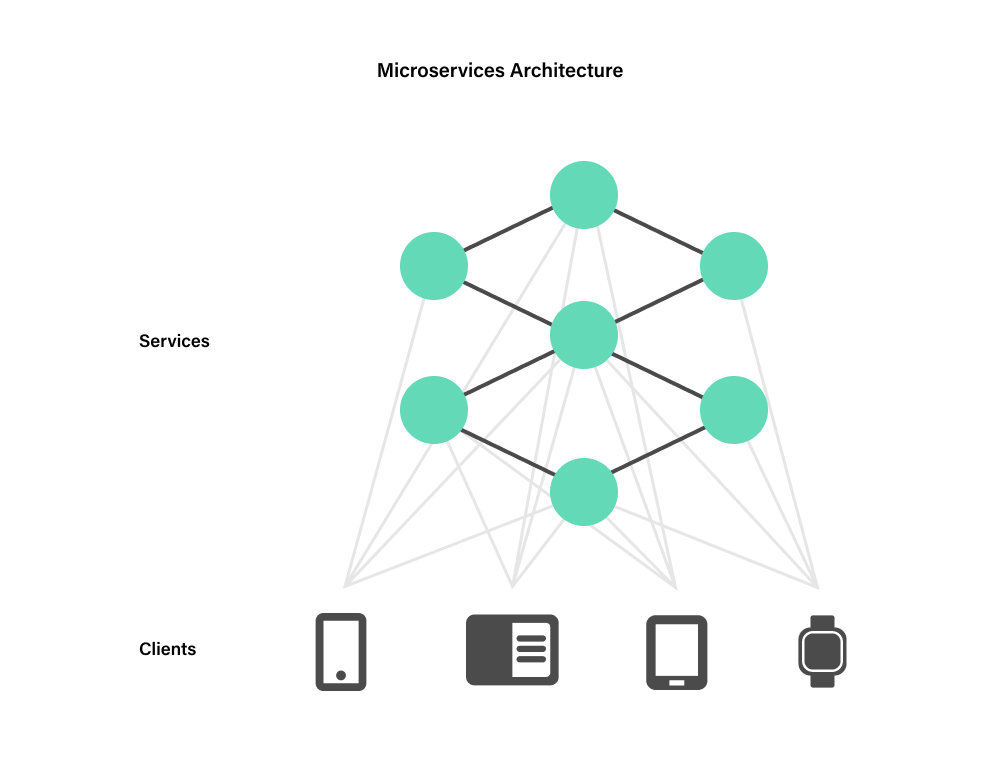
This does have some benefits:
- It’s easier to evolve services independently because their state is encapsulated behind APIs.
- It can enforce security and schema constraints that are not enforceable in the databases.
- The database hardware can be scaled and managed per-service.
However, these service orientation patterns have a lot of downsides, too:
- If an API needs to change, it needs to remain backwards compatible.
- The more services and APIs a client needs to talk to, the slower and less reliable the application becomes.
- Data ends up duplicated in different formats across many services and quickly goes out of sync.
The last issue is particularly troublesome and leads to common user experience problems like failed inventory checks and checkout processes in ecommerce apps, slow or lost messages in customer support tools, out-of-date market information in banking and cryptocurrency applications, etc.
What about GraphQL?
GraphQL is a partial response to these problems. GraphQL has made the presentation of the API responses customizable, and programmable to a degree, as well as composable via middleware like Apollo, Hasura, and others.
Why should a frontend team have to wait for a backend team to make a trivial code change just to get the data they want in a different format? Why should an application have to query a dozen remotely located microservices just to serve one request? Instead, let’s take the microservices with their own databases and have them expose GraphQL APIs that can be remixed and queried in general-purpose ways by decoupled clients.
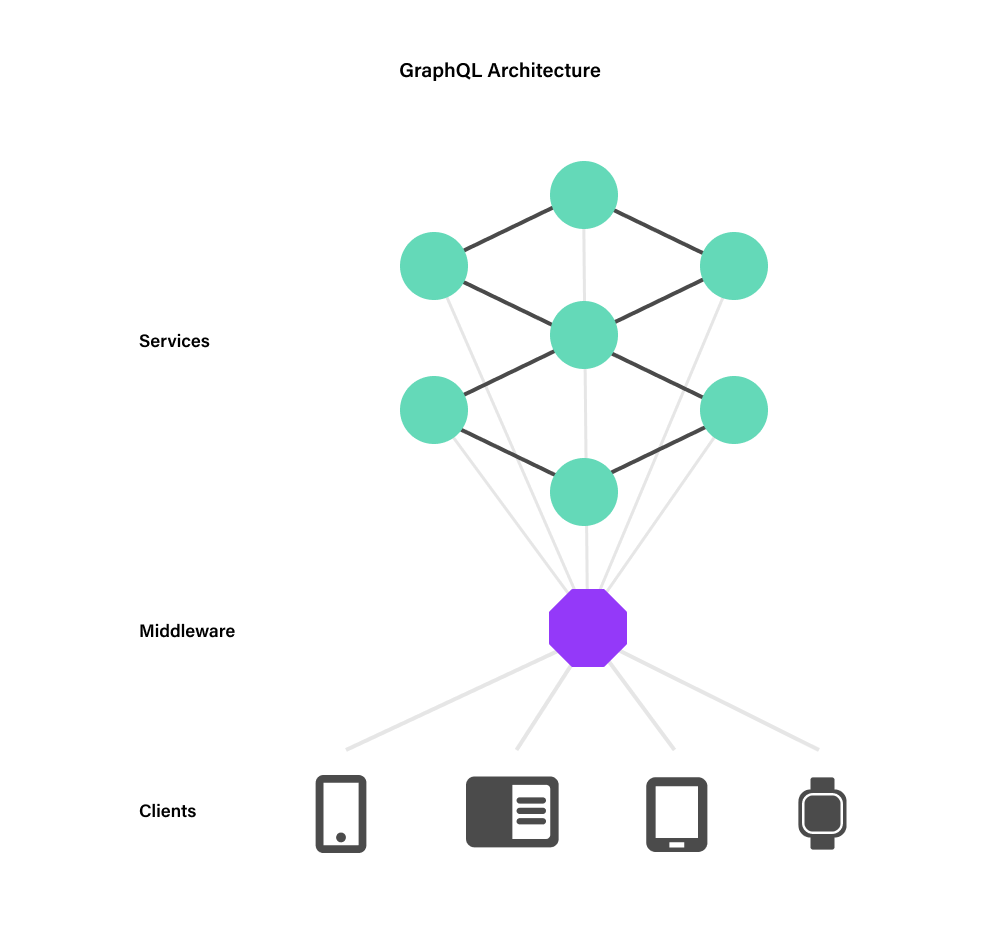
Definitely a reduction in both complexity and maintenance cost.
Minimizing operations, but not complexity
Now imagine that to reduce our operational burden, we replace the databases with serverless database instances that can be queried from anywhere and scale automatically, and move the microservices into stateless serverless functions that can also be queried from anywhere. Now our application can scale indefinitely, remain highly available, and offer lower latency to our users.
Sounds great, right? The physicality of our architecture is completely gone. Our business logic and data is ubiquitous. But what remains is the operational burden of managing the serverless functions, their GraphQL APIs, and the gateways, middlewares, and security-related products required to query them. Additionally, our availability and performance is still constrained by the least good function or service in the synchronous access pattern.
This is a simple communication complexity calculation, best memorialized as part of Brooks’s law. The more potential communication paths there are in a system or an organization, the higher the communication overhead becomes.
The origins of the integration database pattern
A customer pattern we see solves this problem, and it’s the integration database pattern. This pattern went out of style in the 90s along with Oracle servers in the closet and dedicated DBAs, but with technological advances like scalable multi-region transactions and serverless computing resources, its utility has returned.
How did it used to work? Client applications, running on desktop PCs, would access the database over a low-latency local network. The database would have tables with well-defined and enforced schemas and access controls managed by the DBA. Business logic shared across multiple clients, or that had to be extra secure, would be encapsulated in stored procedures which the DBA would manually validate for performance and correctness. Presentation logic that was not shared across clients or did not need to be secure would run on the client devices. Clients and any other services in the system would never talk to each other. They would only talk to the database.
This was actually pretty great. Application components could take advantage of their local computing resources while remaining loosely coupled and capable of independent evolution. Meanwhile, correctness was centrally enforced by the database.
With the advent of the web, the security, performance, and scalability of the RDBMS model broke down and it became an operational bottleneck. To solve these issues, the LAMP architecture arose. Now instead of stored procedures managed by a DBA wielding feudal-levels of control, an application server written by a team of developers intermediated all database access and made stateless business logic horizontally scalable.
Apache and CGI-BIN got us really far, but eventually we as an industry had to move to the service-oriented and microservice world of today. Even the largest database hardware couldn’t scale vertically forever, and application complexity outstripped our ability to deploy and operate it successfully as a single-process monolith.
New technology solves old problems
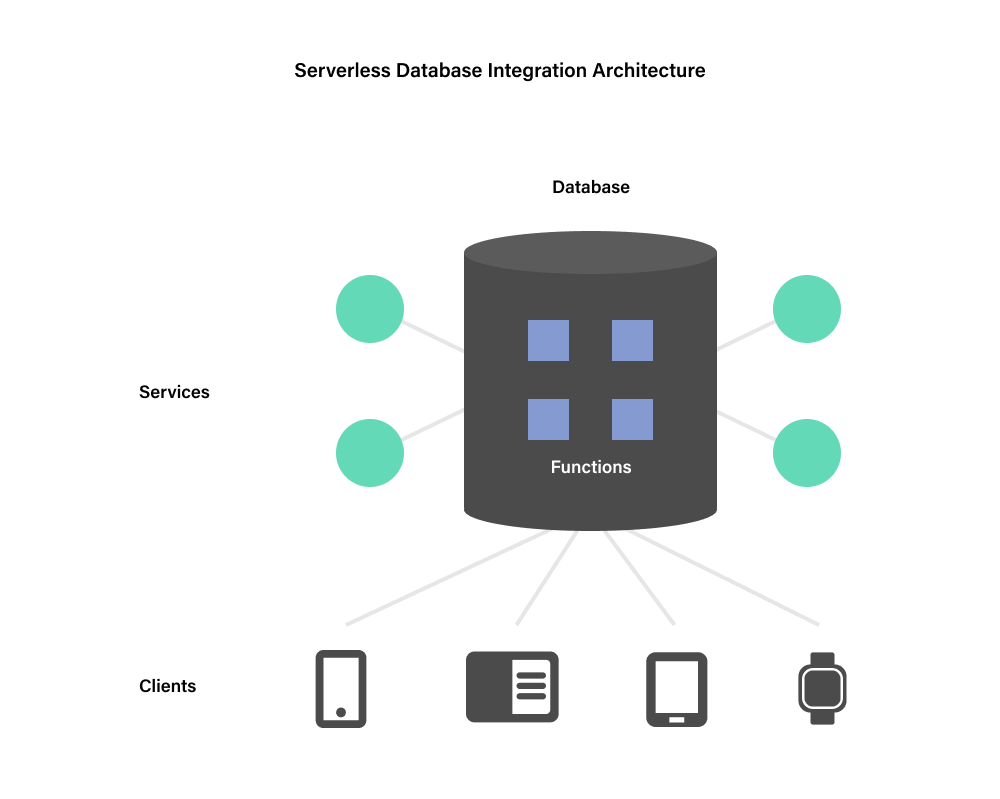
Technology has changed, and these problems are now solved. Databases like Fauna can do everything that both the legacy database-oriented architecture and the modern serverless and service-oriented architectures can do:
- Data can be programmatically accessed via GraphQL.
- Data can be accessed at low latency from every client.
- Access control, schema constraints, and backwards compatibility can be managed centrally.
- Shared business logic can be encapsulated as serverless database stored procedures, and tested and versioned as part of the normal software development life cycle.
- Application services can be triggered by user interaction or by changes to the data itself and never need to interact with each other.
And best of all, because of its distributed architecture, a system built to integrate around Fauna can run everything in a fully transactional, strongly consistent context, eliminating the user experience problems discussed above. For example, an ecommerce app can offer a very low latency digital storefront experience, while still ensuring that any item shown as in stock really is available and can be purchased.
Patterns for serverless applications
The common pattern we see across Fauna customers who are adopting a serverless architecture includes a combination of:
- A mobile app
- A single-page dynamic web app
- Some backend services implemented as serverless functions
- A shared Fauna database, as well as several service-specific ones
- Business logic implemented in Fauna functions with FQL, with some functions published as GraphQL resolvers as well
The apps and backend services don’t talk to each other. Instead, they only talk to Fauna and to any additional API services they may consume, like Stripe. We have seen this pattern work very well across our customers.
In conclusion
Serverless operational models, web-native security practices, and modern query languages and APIs have removed the architectural limitations that pushed developers away from the integration database pattern in the past.
At Fauna, we have seen many customers increase productivity, availability, consistency, performance, and ultimately deliver a better user experience, by integrating their services and clients through the database. I encourage you to rethink your architectural assumptions and take advantage of these new capabilities in your own applications, too!
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.