
What is a Document Relational Database?
Updated June, 2024
Developer tools and infrastructure are evolving at break-neck speed, with new higher-level offerings cropping up regularly that raise the abstraction level, remove undifferentiated heavy-lifting, and make developers more productive. Engineering teams that take advantage of these tools and platforms, those embracing modern technology and development paradigms instead of clinging to tools and interfaces built decades ago, have a massive advantage. This is especially true with something as core to the application stack as the operational database, where the state of the art has moved well beyond mere orchestration and shims built around legacy offerings.
Building modern applications faster, with less code, and scaling to support complex workloads with minimal operational overhead requires a modern transactional database with a no-compromise architecture. Applications need data replicated at the edge, delivered with the highest level of consistency guarantees, with the power to run complex business logic in the context of your data and return answers in the shape that the application requires.
Fauna is a distributed document-relational database built for modern applications. It combines the flexibility, scalability, and performance of document databases with the consistency and power of traditional relational databases. Further, it is delivered as an API, removing the operational burden from developers and allowing them to focus on their applications.
In this article, we’ll dive deeper into the history of relational and document databases, the attributes that developers associate with them, and why we think the document-relational model at the heart of Fauna is the best fit for today’s developers and applications.
The history of relational databases
Relational databases were born in 1970 when Edgar F. Codd published his whitepaper A Relational Model of Data for Large Shared Data Banks. In the paper, Codd introduces normal form, which flattens objects into a two-dimensional column-homogeneous array that we now typically refer to as a table. He also describes the ability to form relationships between different tables through the use of primary and foreign keys. Ingres and System R were prototype relational databases built in the mid-1970s, and commercial relational database management system (RDBMS) implementations such as Oracle, DB2, and Informix arrived in the late-1970s and early-1980s.
The 1980s saw an explosion of desktop computing and broader adoption of the RDBMS along with standardization of technologies in the ecosystem. The Structured Query Language (SQL), born from System R’s SEQUEL language, was selected by the American National Standards Institute (ANSI) in 1986 and the International Organization for Standardization (ISO) in 1987 as the way to interact with normalized data in a relational database. SQL allowed developers to store, manipulate, and retrieve data in a database in a standard way without worrying about the database implementation, except where non-standard SQL functionality differed between vendors. SQL included the ability to join tables using foreign keys to support the relational model and allowed developers to denormalize data when it was accessed.
Relational database usage continued to grow in the 1990s and commercially available database offerings consolidated, resulting in a small number of commercial systems that were expensive and ran on single machines that could only be vertically scaled by increasing hardware.
In more recent years, advances in relational databases have primarily focused on increasing performance and on reducing management costs. In 2009 Amazon Web Services (AWS) launched its Relational Database Service (RDS) offering out-of-the-box management for MySQL, later following with support for Oracle, PostgreSQL, and other relational database flavors. The subsequent launch of AWS Aurora in 2014 provided developers with more scalable storage backing a single-instance relational database.
The definition of a relational database
When subdividing databases into categories, we can think of each category in terms of the literal attribute described by the name and other implicit attributes that have become associated with the category over time. At face value, a database is relational if it stores data as a set of tuples grouped into relations – an arrangement that we now think of as simply storing data in tables with defined schema. Relational databases also typically support defining relationships between normalized data in different tables using foreign keys, and allow queries to perform joins across tables. They force all columns in tables to be typed and provide a robust type-checking system to ensure that data conforms to the desired shape and remove the likelihood of run-time errors due to data mismatches.
Other properties have come to be associated with relational databases because of how the database landscape evolved. For example, relational databases execute queries transactionally and provide strong atomicity, consistency, isolation, and durability (ACID) guarantees, a benefit historically conferred by running all transactions on a single host. They often provide strong tools for access control including a mix of both role-based access control (RBAC) and attribute-based access control (ABAC), allowing organizations to define granular access policies that are much more granular and require far fewer policy changes than RBAC alone.
Problems with the traditional relational database model
From the late-1990s to mid-2000s, massive shifts in computing paradigms began to expose problems with the traditional RDBMS model. First, the rise of object oriented programming (OOP) created an object-relational impedance mismatch between the way that developers wanted to work with data and the way that data was being stored by the database. Early Object-Relational Mapping (ORM) implementations such as TopLink and more mature frameworks like Hibernate were created to handle denormalization and pave over the impedance mismatch, exposing a more convenient abstraction to developers. But reliance on ORMs often led to inefficient queries that performed poorly and didn’t scale, and it forced a split between application developers who spoke in terms of objects and database administrators who spoke in terms of tables.
The next issue was exposed when Amazon launched its Elastic Cloud Compute (EC2) service in 2006, fueling a multi-decade migration to the cloud and the shift towards compute loads that scale horizontally by adding commodity hardware. EC2 allowed infinite scalability of compute, which was attractive for developers building web services that needed to scale up and down dynamically. But this new cloud paradigm of scaling horizontally without limits by adding commodity hardware wasn’t compatible with single instance relational databases that could only be vertically scaled by adding more powerful hardware.
An additional problem appeared more recently with the advent of client-serverless architectures, where applications run on end devices and access all data and services through APIs. These applications require data to be not only horizontally scalable but replicated to the edge so that reads are extremely fast. Further, reads and writes are handled directly in application code written by frontend developers who often don’t care for the ergonomics of SQL and want to use a more modern language.
Addressing scalability in the relational world
Some vendors attempted to address the scalability and performance issues of a RDBMS by maintaining the core relational properties of table-based storage with strict schema, a SQL interface, and ACID compliance, while moving towards clustered topologies that can parallelize compute and storage, scale horizontally, and move data to the edge. These databases have been called NewSQL databases, a term coined by Matthew Aslett in a 2011 post entitled What We Talk About When We Talk About NewSQL.
H-Store was an early NewSQL database written by a team of researchers in 2007, and VoltDB followed in 2009 as a commercial implementation. More recent NewSQL offerings such as CockroachDB and YugabyteDB have continued to expand the limits of what is possible in a relational database, providing further scalability and the ability to selectively replicate data across regions in large, distributed clusters.
NewSQL offerings are particularly compelling for operators that want to lift and shift existing applications built on SQL to a new, more scalable database. But they still suffer from fundamental relational limitations such as the object-relational impedance mismatch and the inability to handle data that doesn’t conform to a rigid schema, which makes them less attractive for developers building modern applications.
The rise of document databases
Another response to the shortcomings of traditional relational databases was to build an entirely new type of database. In 1998 Carlo Strozzi created his own database which he called NoSQL, a moniker that was resuscitated by Johan Oskarsson in 2009 as a term of art to describe a different set of properties than a SQL-based RDBMS. Early versions of more general database management systems came in many flavors including key-value stores, document databases, and graph databases, each tailored to specific access patterns and use cases. Most popular NoSQL databases were built as large-scale distributed systems that provided a more attractive scaling profile but typically meant settling for consistency or performance tradeoffs.
The mid-2000s were a seminal moment in the development of NoSQL databases, and document databases in particular, as several important whitepapers were published and systems were implemented. In 2007 engineers from Amazon published Dynamo: Amazon’s Highly Available Key-value Store which described the first version of a highly scalable and performant distributed database that could store small, arbitrary values for fast access by key. A few years later in 2009 Facebook engineers published Cassandra - A Decentralized Structured Storage System describing another implementation of a distributed key-value store that was released as open source software (OSS).
2009 also saw the launch of MongoDB, a database that built on the key-value paradigm and allowed developers to store arbitrary JavaScript Object Notation (JSON) documents by key. Because MongoDB documents were JSON, developers could use the database to store unstructured data, which is desirable in the early phases of most projects. Documents also supported arbitrary levels of nesting, which can be useful for use cases such as simple “has a” relationships with a 1:1 mapping.
Query languages for document databases varied wildly over time, with some vendors providing their own data query and manipulation languages such as the MongoDB Query Language (MQL), and others trying to superimpose SQL over the document model. Access and storage patterns also changed as storage became less expensive over time and compute power to access and process data became the performance and cost bottleneck. This caused some developers to duplicate data across documents to avoid the need to use joins, but also resulted in consistency issues that needed to be handled at the application layer.
The definition of a document database
Like relational databases, we can think of the document database category in terms of the attribute describing the name as well as other attributes ascribed to the category. Fundamentally, a document database is a database that stores data in unstructured documents (usually in JSON format) that are accessed by key or through indexes that cover document properties. Documents store objects in their native form which removes the need for an ORM, which typically leads to increased developer productivity and better query performance due to the lack of translation from one format to another.
Another more general property of document databases is that they are usually distributed systems that can scale horizontally but are architected to trade consistency for scalability, which means that they fall back to eventual consistency and aren’t able to make ACID guarantees.
Problems with the document database model
The document database model comes with its own set of problems. For example, the lack of schema support in most document databases is often seen as a benefit in early application development, but a liability after an application is running in production. The inability to verify that all data in the database conforms to a specified shape results in the need for complex checks in application code and frequent runtime exceptions.
Most document databases do not support querying across documents or joining different types of data together in complex queries, which means that join logic needs to live in custom application code on the client. This introduces application complexity, and it also results in the need to make several queries for individual documents before making the join, with each query paying the performance price of a round trip to a server.
Many popular document databases were initially built by large technology companies for internal use, so they employed legacy security models focused on perimeter defense and lacked capabilities like ABAC that have become more essential as databases have become exposed to the public internet and compliance requirements have become even more stringent. Instead, limited RBAC capabilities support only fixed and coarse-grained access control instead of the type of dynamic and fine-grained access control that is required in environments where applications, data, and consumers are constantly evolving.
Finally, because most document databases offer only various forms of eventual consistency, application developers need to handle complex edge cases in application code.
The answer is document-relational
Fauna is the first document-relational database, offering the benefits of document and relational databases in a package that is attractive to developers. Like other document databases, data in Fauna is stored in JSON documents that are initially schemaless, providing flexibility in early application development as schema evolves. Later in application development, optional schema support allows developers to incrementally start enforcing the shape of data across groups of collections. This support for gradual typing allows development teams to move fast in the early days of an application when the data model isn’t well understood, and then avoid runtime issues for mismatched data later in the application lifecycle after the model has solidified.
Unlike other document databases, documents stored in Fauna can reference each other based on attributes, allowing developers to use arbitrarily complex joins in the database layer and eliminating the need for multiple round trips and custom join logic in application code. All requests execute in the context of a transaction, which means that the result is guaranteed to be consistent and up to date at the snapshot time of the request. Fauna’s novel architecture allows the database to be scalable and correct, offering strict serializability — the highest level of consistency guarantee — without compromising on performance. Finally, Fauna comes out of the box with rich security features that are designed for the internet, including a powerful combination of RBAC and ABAC that includes the ability to define arbitrary predicates that allow access decisions to adapt based on transaction-specific data or user attribute changes, enhancing responsiveness and compliance.
All of this functionality is delivered via an API, which removes the burden of operating, upgrading, and scaling a database from developers. The API supports queries that are implemented in the Fauna Query Language (FQL), which is Turing Complete, so transactions can include effectively arbitrarily complex logic. To learn more about the design of Fauna’s Query Language, visit our blog.
Definition
What is a document-relational database?
A document-relational database combines the flexibility and familiarity of JSON documents with the relationships and querying power of a traditional relational database.
Fauna accelerates modern application development by integrating semi-structured document data with ACID guarantees and a robust query language, the Fauna Query Language (FQL). Fauna also provides foreign keys, views, and joins, so that you can structure your data the way you think about it without complicated workarounds like single-table design.
A real-world example
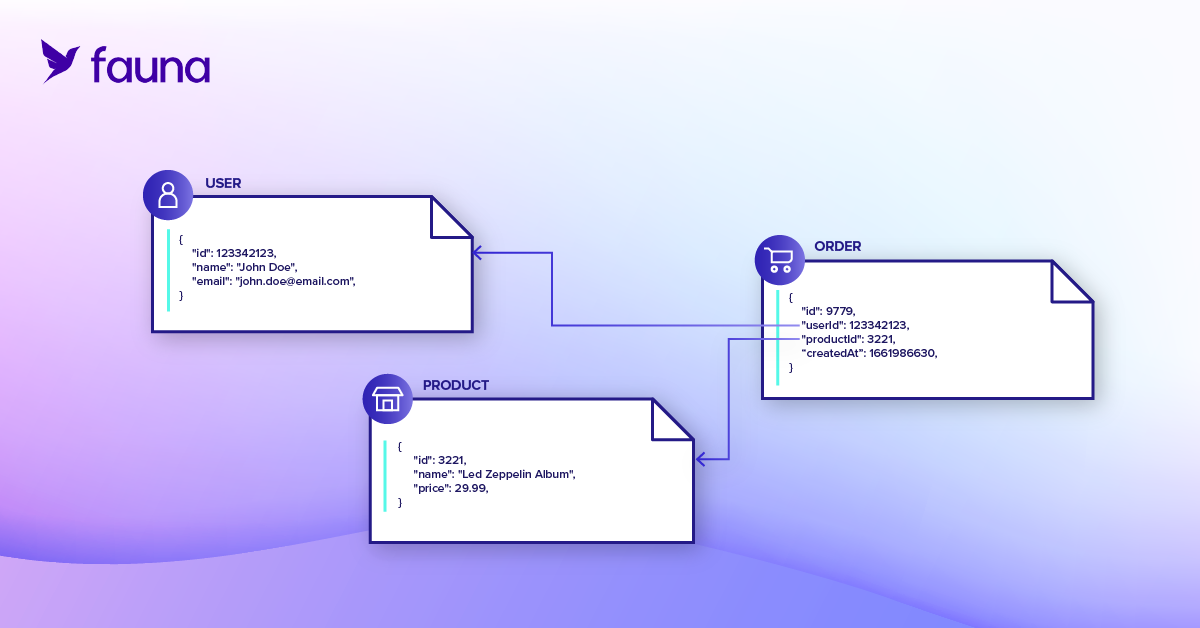
Let’s take these concepts out of the abstract and into the real world with an example to make the differences more concrete. Consider a situation where a developer has built an e-commerce website with an underlying data model that includes users, products, and orders. For the sake of simplicity, let’s assume that each order has only one product. Now suppose that the developer wants to add an admin page that shows all historical orders made by a given user and the total amount of money that they have spent over the lifetime of the website.
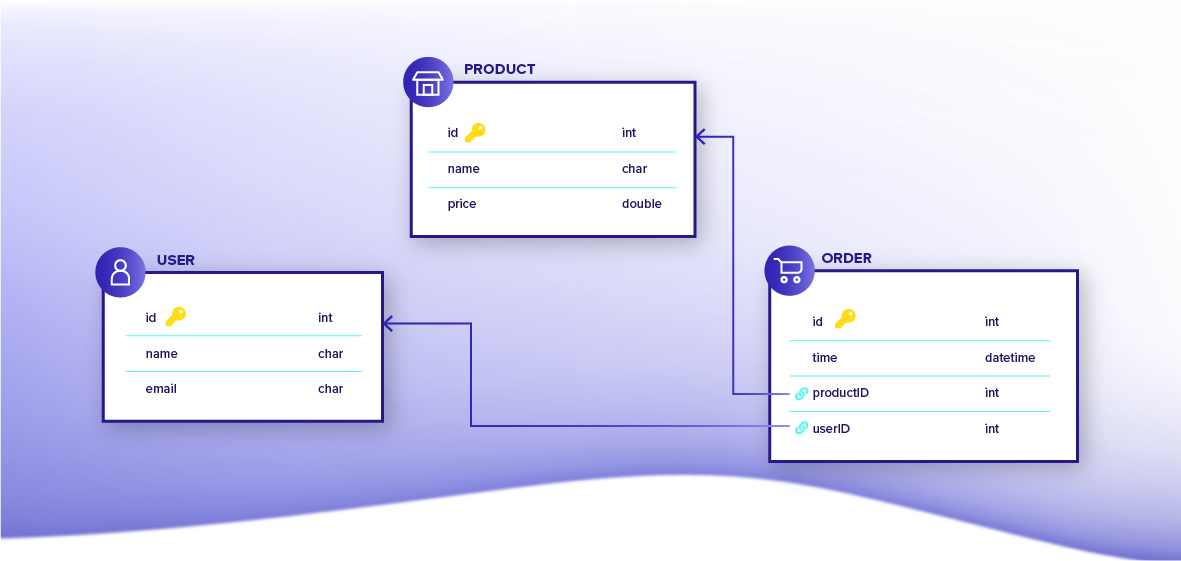
In the relational database world, the developer would start with a set of tables that represent users, products, and orders. All table schema would need to be declared ahead of time and subsequent schema changes would require a data migration. Relationships between entities would be modeled using foreign keys on the orders table that map to primary keys on the users and products tables.
To optimally retrieve the data for the new recent orders page, the developer could construct a SQL query with multiple inner joins to get the list of orders and products for the user, along with a grouped sum aggregation to get the total amount that the user has spent. The result would be delivered as a single table that would need to be converted to a set of nested objects in code or by leveraging an ORM, and the resulting table itself would have redundant aggregation data in the rows for each order, which would need to be cleaned up in application logic.
In the document database world, the story would be different. The same developer would start by creating one or more collections (also called tables in some systems) to hold documents, depending on the desired access pattern. Each document has its own key that can be used for key/value access and order documents have fields that have the key for the user that created the order and the ordered product. Because fetching data performance is a concern for page load times, the developer could use a single-table design with a single collection that holds user and order documents where each type of document is partitioned by its user key, allowing for single batch reads to get a user and their orders in one request. Products aren’t related to users, so they would be stored in a separate collection.

To retrieve the same data for the new admin page, the developer would first send a request to get the user and all of their orders. After that, the developer would need to submit a subsequent request to get the products associated with each order to access their prices. Finally, the developer would need to transform the resulting documents in application code to compute the aggregate amount spent. Requests would not be wrapped in a single transaction, so the resulting data may not be consistent and application code would need to handle edge cases where multiple requests were interleaved with one another.
Now let’s look at the same example using the document-relational model. In Fauna, the developer would create separate collections for users, products, and orders to contain documents of each type. Like in a relational database, relationships between entities would be modeled using reference fields in order documents pointing to users and products.
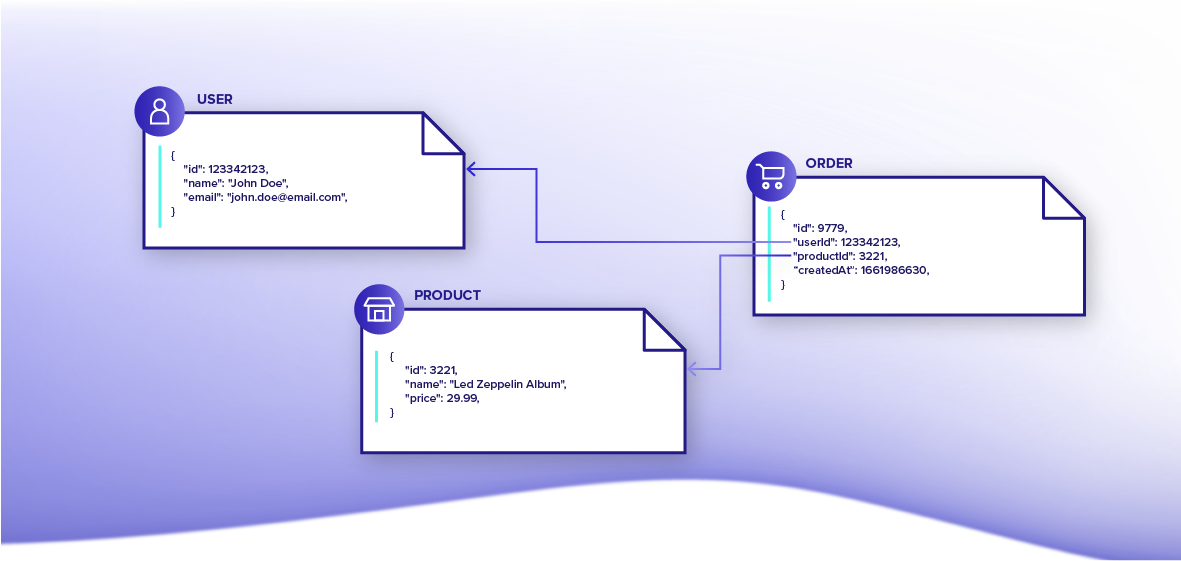
To retrieve needed data, the developer would craft a single FQL query to join documents from different collections, aggregate, and transform the result. The request would run in the context of a transaction, ensuring that the result is consistent at the logical point in time when the transaction is executed. Moreover, because Fauna returns the result of a query as a document, the response could be constructed as an array of JSON objects with the associated data of each recent order: the purchaser, the purchaser's total spend, and purchaser's orders, putting the result into the shape that the application expects and avoiding heavy data manipulation. Perhaps most importantly, the data model could evolve easily as the application changes, avoiding the need to understand all schema or all data access patterns up front.
Conclusion
Application requirements have evolved, and languages that were developed in the 1970s for a data analyst sitting at a workstation are not well suited for today’s environment where the main data consumer is an end user demanding real-time information in the context of an application. Enterprises need to move faster to outpace the competition, which can only happen by leveraging the best tools that are available.
More than 80,000 development teams in over 180 countries use Fauna as their operational database of choice to increase their execution speed and remove the need for undifferentiated heavy lifting. They have embraced the new document-relational paradigm instead of suffering the tax of dealing with legacy databases and interfaces.
Fauna's distributed, document-relational database combines the flexibility of the document model with the consistency and transactional behaviors of a relational database. The best aspects of these two database models are harmonized in Fauna to provide the most expressive, flexible, and powerful database available. Try Fauna today with a free account.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.