

Fauna Serverless Scheduling: Cooperative Scheduling with QoS
While working on database infrastructure at Twitter some of the core features we developed early on were related to scaling the servers to keep up with the user growth as well as handling unexpected load increase due to runaway queries and malicious actors. We implemented scale-out NoSQL models, server timeouts and rate limits and optimized the system such that each cluster could handle millions of queries of a given type. However, despite being highly efficient in single workload settings, the clusters did not perform well in a shared workload environment as they lacked support for resource pools and co-operative scheduling.
When we set out to build FaunaD we observed this pattern across industries and use-cases as existing systems were attempting to solve this either through the system administrator manually assigning a number of servers for a specific workload (static isolation boundaries) or the system attempting to elastically scale its resources based on step functions of demand (auto-scaling groups). Both of these approaches have inherent flaws and neither of them generalizes very well across a wide variety of workloads.
We found that the optimal way to achieve multi-tenancy in a shared data infrastructure was not through external container orchestration, but through building cooperative scheduling and QoS into the core itself. This resource management model is a good fit for serverless use cases because runtime requirement spikes can be absorbed by the database provider, while at the same time the provider can benefit from economies of scale. This reduces risk and cost for both the serverless user and the database provider.

As a result, we built a database system that supports efficient and fair resource sharing, security through process isolation and allows teams to create suites of products and workloads under one organizational database hierarchy and seamlessly scale workloads without having to implement scaling logic in the orchestration layer or having to estimate resource utilization beforehand.
Current industry standards for multi-tenant system design
Achieving multi-tenancy through infrastructure sharing is an important optimization for applications and provides enterprises with several advantages such as reducing costs and more efficient resource utilization as well as long-term benefits such as ease of upgrades, better scalability and service support. As such most enterprise-level offerings have some support for distributed multi-tenancy. Multi-tenancy in most such systems takes one of the following approaches.
Competing access to shared containers
Manual provisioning or predictive provisioning does not account for unpredictable spikes which will often cause an outage of one or all the processes if enough buffer resource is not allocated. In cases where the shared system is tenant unaware, the workloads compete for resources with a goal of acquiring the maximum amount of resources in order to stay ahead of the competition and consequently if enough idle capacity is not present, all workloads will suffer including critical ones.
Cloud-native solutions, seemingly solve these problems with a theoretical ability to provision and deallocate resources on the fly, however these solutions cannot scale stateful services fast enough as attempting to provision more resources further strains the existing nodes which are already running at capacity and in case of unpredictable spikes this can lead to cascading effects and subsequent downtime. In short, the worst time to undertake operational movement, such as expanding a cluster, is when you are over capacity.
Per-tenant dedicated containers
Some other database systems apply static isolation boundaries to workloads which require the application developer to preemptively predict how many resources each workload will consume and allocate containers for each tenant. In such systems however pools must pre-allocate idle capacity for expansion and containers must have the idle capacity to handle spikes as well. This approach does not work for the shared state as a state must be replicated leading to increase in storage costs while data consistency is not guaranteed.
Furthermore, in such systems, spikes get exaggerated as workloads can only soak up their own idle capacity and not that of others and as such these systems are highly inelastic.
The Fauna approach- Cooperative scheduling with QoS
Fauna uses cooperative scheduling to avoid these pitfalls by allowing low priority workloads to use the available hardware at a steady-state consumption without interfering with higher priority workloads which can burst to higher consumption during periods of heavy usage. This architecture allows for greater efficiency of hardware utilization in the presence of diverse workloads in contrast to single-tenant systems which optimize for performance during single workload operations.
Operational challenges in providing QoS over shared data-sets
Ensuring quality of service for shared workloads at a scale comes with operational complexity and tradeoffs relating to resource utilization and security of the workloads. Listed below are the most significant challenges that a multi-tenant service provider must mitigate in order to provide QoS guarantees -
- Ensuring a fair resource distribution among workloads
When multiple workloads share the same physical infrastructure, a strategy of distribution of resources is needed which takes into account priority and fairness of distribution. First-come first-serve scheduling can lead to processes in the back of the queue getting resource-starved and particularly so during periods of high utilization. - Ensuring efficient context switching and predictable outcomes of batch operations.
The frequent context switching which comes from evicting workload processes and saving state at each such interval introduces several bottlenecks and can cause significant overhead and leave one or all of the workload in an inconsistent state. - Ensuring security and isolation of the workloads sharing the infrastructure
Multi-tenant application security remains a primary concern amongst policy-makers, as the past years have seen several breaches and data leakage in production and research settings causing data-loss to the enterprise and exposure of sensitive customer data.
Providing resource guarantees and prioritization
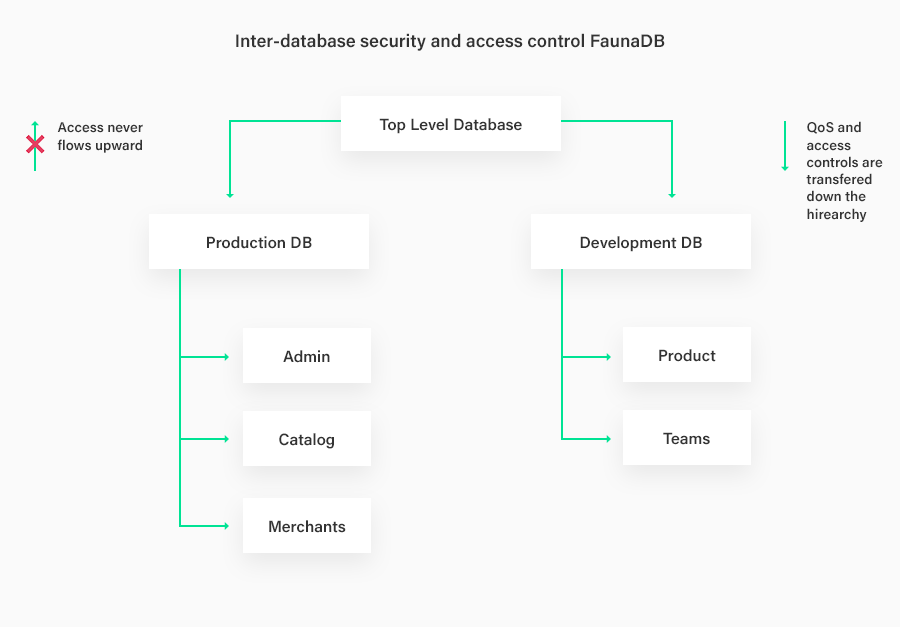
Ensuring fairness in resource sharing is one of the most important aspects of designing data infrastructure for resource-sharing patterns. For instance, let us consider a case where a production database, an analytics database, and a development database are running on the same cluster and the system needs to ensure that higher priority operations get more resources while not starving low priority resources during periods of high usage. Fauna provides simple configuration level constructs for setting priorities on the client or at the data layer while also allowing for databases to be arranged in a hierarchical order and as a result, a database may contain other databases and QoS and security rules are inherited down the tree. This allows for easy to implement, efficient resource sharing down the database hierarchy.
Resource scheduling in Fauna is based on deficit round-robin algorithm which provides a means of fair resource scheduling for weighted queues while requiring only a constant unit of work. Unlike most multi-tenant databases which have only a skin-deep implementation of query prioritization and drop priority context once a query is chosen for execution, query priority is a first-class citizen in Fauna and is propagated through the system throughout its query life-cycle.
Each query propagates its priority to the node in which it executes and the node applies QoS limits based entirely on its local state i.e. if a query hits a node and the node has resources available for servicing that operation it is serviced immediately else prioritization applies based on local node QoS state. This approach prevents unnecessary round trips and the need for a global QoS policy and works really well in practice as long as the work units are small enough and there is eventual preemption for unresponsive queries.
Systems often focus on absolute benchmarks while ignoring overheads caused due to cumbersome multithreading models and context switch overheads. Through optimized eviction points such as I/O, compute and termination of loops, Fauna query-executor evaluates transactions from independent workloads as a series of parallelizable and interleaved subqueries. This also ensures that process eviction happens at granular and predictable barriers and that the overhead during context switching can be minimized.
Fauna query processor can simultaneously run thousands of concurrent queries in a mixed workload setting and concurrency is implemented through cooperative threading with async coroutine execution which provides easy support for high-level concurrency without the need for frequent context-switching.
Security through isolation and access control
Fauna allows for fine-grained identity management and access control to be applied to workloads that share the same cluster. Through its high-level constructs of instance-object, class, and database, it allows for customizable role/access combinations to be created and provides different levels of granularity and visibility to any single tenant in a multi-tenant application group.
Attribute-based security in Fauna is achieved through secrets that correspond to access keys which authenticate the user as having particular permissions. Upon creation, only the hash of the key is stored in the disk and the responsibility of storing the key is delegated to the user.

Fauna’s identity management and row-level access control prevent data leakage and unauthorized access while the hierarchical database grouping structure also allows for access policy and QoS schemes to be easily passed down the databases tree allowing for authorized access for co-operative use-case patterns in a manner that is easy to understand and implement.
Conclusion
In this article, we saw some of the challenges faced by teams implementing multi-tenant data architectures and how Fauna solves those challenges through its QoS based infrastructure abstraction. To learn more about how resource-sharing works in Fauna as well as view shared-resource QoS benchmarks you can read more here.
Most virtualized data infrastructure exposed through IaaS and PaaS abstractions rely heavily on sharing underlying resources. Even in applications running on dedicated node abstraction of the public cloud, the infrastructure behind the abstraction is usually still sharing physical resources with other colocated applications. Teams often want to take advantage of multi-tenancy on shared infrastructure without having to deal with the complexity that comes with managing workloads on shared infrastructure.
Fauna empowers its partners to create their own private serverless database clouds where they can enforce custom quality of service rules through the policy-based resource manager and run metered workloads with fair access to contentious resources. By making it easy for cooperative applications and databases to share infrastructure, Fauna allows many applications to coexist and share hardware through asynchronous coroutine execution and granular access control while also allowing enforcement of strict isolation rules to non-cooperative processes.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.