
Demystifying Database Systems, Part 2: Correctness Anomalies Under Serializable Isolation
Most database systems support multiple isolation levels that enable their users to trade off exposure to various types of application anomalies and bugs for (potentially small) increases in potential transaction concurrency. For decades, the highest level of “bug-free correctness” offered by commercial database systems was “SERIALIZABLE” isolation in which the database system runs transactions in parallel, but in a way that is equivalent to as if they were running one after the other. This isolation level was considered “perfect” because it enabled users that write code on top of a database system to avoid having to reason about bugs that could arise due to concurrency. As long as particular transaction code is correct in the sense that if nothing else is running at the same time, the transaction will take the current database state from one correct state to another correct state (where “correct” is defined as not violating any semantics of an application), then serializable isolation will guarantee that the presence of concurrently running transactions will not cause any kind of race conditions that could allow the database to get to an incorrect state.
In other words, serializable isolation generally allows an application developer to avoid having to reason about concurrency, and only focus on making single-threaded code correct.
In the good old days of having a “database server” which is running on a single physical machine, serializable isolation was indeed sufficient, and database vendors never attempted to sell database software with stronger correctness guarantees than SERIALIZABLE. However, as distributed and replicated database systems have started to proliferate in the last few decades, anomalies and bugs have started to appear in applications even when running over a database system that guarantees serializable isolation. As a consequence, database system vendors started to release systems with stronger correctness guarantees than serializable isolation, which promise a lack of vulnerability to these newer anomalies. In this post, we will discuss several well known bugs and anomalies in serializable distributed database systems, and modern correctness guarantees that ensure avoidance of these anomalies.
What Does “Serializable” Mean in a Distributed/Replicated System?
We defined “serializable isolation” above as a guarantee that even though a database system is allowed to run transactions in parallel, the final result is equivalent to as if they were running one after the other. In a replicated system, this guarantee must be strengthened in order to avoid the anomalies that would only occur at lower levels of isolation in non-replicated systems. For example, let’s say that the balance of Alice’s checking account ($50) is replicated so that the same value is stored in data centers in Europe and the United States. Many systems do not replicate data synchronously over such large distances. Rather, a transaction will complete at one region first, and its update to the database system may be replicated afterwards. If a withdrawal of $20 is made concurrently in the United States and Europe, the old balance is read ($50) in both places, $20 is removed from it, and the new balance ($30) is written back in both places and replicated to the other data center. This final balance is clearly incorrect ---- it should be $10 --- and was caused by concurrently executing transactions. But the truth is, the same outcome could happen if the transactions were serial (one after the other) as long as the replication is not included as part of the transaction (but rather happens afterwards).
Therefore, a concurrency bug results despite equivalence to a serial order.
Rony Attar, Phil Bernstein, and Nathan Goodman expanded the concept of serializability in 1984 to define correctness in the context of replicated systems. The basic idea is that all the replicas of a data item behave like a single logical data item. When we say that a concurrent execution of transactions is “equivalent to processing them in a particular serial order”, this implies that whenever a data item is read, the value returned will be the most recent write to that data item by a previous transaction in the (equivalent) serial order --- no matter which copy was written by that write. In this context “most recent write” means the write by the closest (previous) transaction in that serial order. In our example above, either the withdrawal in Europe or the withdrawal in the US will be ordered first in the equivalent serial order. Whichever transaction is second --- when it reads the balance --- it must read the value written by the first transaction. Attar et. al. named this guarantee “one copy serializability” or “1SR”, because the isolation guarantee is equivalent to serializability in an unreplicated system with “one copy” of every data item.
Anomalies are Possible Under Serializability; Anomalies are Possible Under One-copy Serializability
We just stated that one-copy serializability in replicated systems is the identical isolation guarantee as serializability in unreplicated systems. There are many, many database systems that offer an isolation level called “serializability”, but very few (if any) replicated database systems that offer an isolation level called “one-copy serializability”. To understand why this is the case, we need to explain some challenges in writing bug-free programs on top of systems that “only” guarantee serializability.
A serializable system only guarantees that transactions will be processed in an equivalent way to some serial order. The serializability guarantee by itself doesn’t place any constraints on what this serial order is. In theory, one transaction can run and commit. Another transaction can come along --- a long period of time after the first one commits --- and be processed in such a way that the resulting equivalent serial order places the later transaction before the earlier one. In a sense, the later transaction “time travels” back in time, and is processed such that the final state of the database is equivalent to that transaction running prior to transactions that completed prior to when it began. A serializable system doesn’t prevent this. Nor does a one-copy serializable system. Nonetheless, in single-server systems, it is easy and convenient to prevent time-travel. Therefore, the vast majority of single-server systems that guarantee “serializability” also prevent time-travel. Indeed, it was so trivial to prevent time travel that most commercial serializable systems did not consider it notable enough to document their prevention of this behavior.
In contrast, in distributed and replicated systems, it is far less trivial to guarantee a lack of time travel, and many systems allow some forms of time travel in their transaction processing behavior.
The next few sections describe some forms of time-travel anomalies that occur in distributed and/or replicated systems, and the types of application bugs that they may cause. All of these anomalies are possible under a system that only guarantees one-copy serializability. Therefore, vendors typically document which of these anomalies they do and do not allow, thereby potentially guaranteeing a level of correctness higher than one-copy serializability. At the end of this post, we will classify different correctness guarantees and which time-travel anomalies they allow.
The Immortal Write
Let’s say the user of an application currently has a display name of “Daniel”, and decides to change it to “Danny”. He goes to the application interface, and changes his display name accordingly. He then reads his profile to ensure the change took effect, and confirms that it has. Two weeks later, he changes his mind again, and decides he wants to change his display name to “Danger”. He goes to the interface and changes his display name accordingly and was told that that change was successful. But when he performs a read on his profile, it still lists his name as “Danny”. He can go back and change his name a million times. Every time, he is told the change was successful, but the value of his display name in the system remains “Danny”.
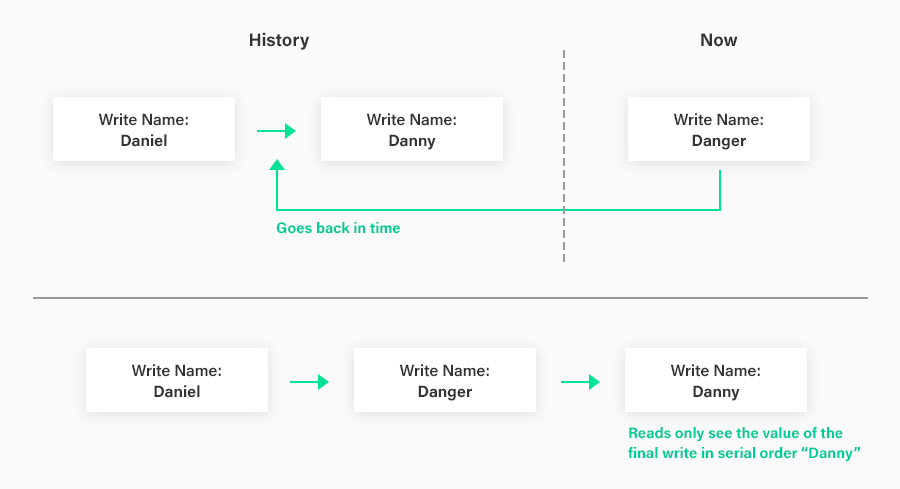
What happened? All of the future writes of his name travelled back in time to a point in the serial order directly before the transaction that changed his name to “Danny”. The “Danny” transaction therefore overwrote the value written by all of these other transactions, even though it happened much earlier than these other transactions in real time. The system decided that the serial order that it was guaranteeing equivalence to has the “Danny” transaction after all of the other name-change transactions --- it has full power to decide this without violating its serializability guarantee. Side note: when the “Danny” transaction and/or the other name-change transactions also perform a read to the database as part of the same transaction as the write to the name, the ability to time-travel without violating serializability becomes much more difficult. But for “blind write” transactions such as these examples, time-travel is easy to accomplish.
In multi-master asynchronously replicated database systems, where writes are allowed to occur at either replica, it is possible for conflicting writes to occur across the replicas. In such a scenario, it is tempting to leverage time travel to create an immortal blind write, which enables straightforward conflict resolution without violating the serializability guarantee.
The Stale Read
The most common type of anomaly that appears in replicated systems but not in serializable single-server systems is the “stale read anomaly”. For example, Charlie has a bank account with $50 left in the account. He goes to an ATM and withdraws $50. Afterwards, he asks for a receipt with his current bank balance. The receipt (incorrectly) states that he has $50 left in his account (when, in actuality, he now has no money left). As a result, Charlie is left with an incorrect impression of how much money he has, and may make real life behavioral mistakes (for example, splurging on a new gadget) that he wouldn’t have done if he had the correct impression of the balance of his account. This anomaly happened as a result of a stale read: his account certainly used to have $50 in it. But when the ATM did a read request on the bank database to get his current balance, this read request did not reflect the write to his balance that happened a few seconds earlier when he withdrew money from his account.

The stale read anomaly is extremely common in asynchronously replicated database systems (such as read replicas in MySQL or Amazon Aurora). The write (the update to Charlie’s balance) gets directed to one copy, which is not immediately replicated to the other copy. If the read gets directed to the other copy before the new write has been replicated to it, it will see a stale value.
Stale reads do not violate serializability. The system is simply time travelling the read transaction to a point in time in the equivalent serial order of transactions before the new writes to this data item occur. Therefore, asynchronously replicated database systems can allow stale reads without giving up its serializability (or even one-copy serializability) guarantee.
In a single-server system, there’s little motivation to read anything aside from the most recent value of a data item. In contrast, in a replicated system, network delays from synchronous replication are time-consuming and expensive. It is therefore tempting to do replication asynchronously, since reads can occur from asynchronous read-only replicas without violating serializability (as long as the replicated data becomes visible in the same order as the original).
The Causal Reverse
In contrast to the stale read anomaly, the causal reverse anomaly can happen in any distributed database system and is independent of how replication is performed (synchronous or asynchronous). In the causal reverse anomaly, a later write which was caused by an earlier write, time-travels to a point in the serial order prior to the earlier write. In general, these two writes can be to totally different data items. Reads that occur in the serial order between these two writes may observe the “effect” without the “cause”, which can lead to application bugs.
For example, most banks do not exchange money between accounts in a single database transaction. Instead, money is removed from one account into bank-owned account in one transaction. A second transaction moves the money from the bank-owned account to the account intended as the destination for this transfer. The second transaction is caused by the first. If the first transaction didn’t succeed for any reason, the second transaction would never be issued.
Let’s say that $1,000,000 is being transferred from account A (which currently has $1,000,000 and will have $0 left after this transfer) to account B (which currently has $0, and will have $1,000,000 after the transfer). Let’s say that account A and account B are owned by the same entity, and this entity wishes to get a sizable loan that requires $2,000,000 as a down payment. In order to see if this customer is eligible for the loan, the lender issues a read transaction that reads the values of accounts A and B and takes the sum of the balance of those two accounts. If this read transaction occurs in the serial order before the transfer of $1,000,000 from A to B, a total of $1,000,000 will be observed across accounts. If this read transaction occurs after the transfer of $1,000,000 from A to B, a total of $1,000,000 will still be observed across accounts. If this read transaction occurs between the two transactions involved in transfer of $1,000,000 from A to B that we described above, a total of $0 will be observed across accounts. In all three possible cases, the entity will be (correctly) denied the loan due to lack of funds necessary for the down payment.
However, if a second transaction involved in the transfer (the one that adds $1,000,000 to account B) time-travels before the transaction that caused it to exist in the first place (the one that subtracts $1,000,000 from account A), it is possible for a read transaction that occurs between these two writes to (incorrectly) observe a balance across accounts of $2,000,000 and thereby allow the entity to secure the loan. Since the transfer was performed in two separate transactions, this example does not violate serializability. The equivalent serial order is: (1) the transaction that does the second part of the transfer (2) the read transaction and (3) the transaction that does the first part of the transfer. However, this example shows the potential for devastating bugs in application code if causative transactions are allowed to time-travel to a point in time before their cause.
Causal reverse anomalies such as this are known to occur in partitioned database systems where transactions run on a particular partition receive a timestamp based on the local time at that partition. If such systems do not wait for the maximum clock skew bound (the maximum possible difference in local times across different partitions in the system) before committing a transaction, it is possible for a transaction to commit, and a later transaction to come along, that was caused by the earlier one (that started after the earlier one finished), and still receive an earlier timestamp than the earlier transaction. This enables a read to potentially see the write of the later transaction, but not the earlier one.
In other words, if the bank example we’ve been discussing was implemented over a system that allows a causal reverse, the entity wishing to secure the loan could simply repeatedly make the loan request and then transfer money between accounts A and B until the causal reverse anomaly shows up, and the loan is approved. Obviously, a well-written application should be able to detect the repeated loan requests and prevent this hack from occurring. But in general, it is hard to predict all possible hacks and write defensive application code to prevent them. Furthermore, banks are not usually able to recruit elite application programmers, which leads to some mind-boggling vulnerabilities in real-world applications.
Avoiding Time Travel Anomalies
All the anomalies that we’ve discussed so far --- the immortal write, the stale read, and the causal reverse --- all exploit the permissibility of time travel in the serializability guarantee, and thereby introduce bugs in application code. To avoid these bugs, the system needs to guarantee that transactions are not allowed to travel in time, in addition to guaranteeing serializability. As we mentioned above, single-server systems generally make this time-travel guarantee without advertising it, since the implementation of this guarantee is trivial on a single-server. In distributed and replicated database systems, this additional guarantee of “no time travel” on top of the other serializability guarantees is non-trivial, but has nonetheless been accomplished by several systems such as Fauna/Calvin, FoundationDB, and Google Spanner.
This highest level of correctness is called strict serializability.
Strict serializability makes all of the guarantees of one-copy serializability that we discussed above. In addition, it guarantees that if a transaction X completed before transaction Y started (in real time) then X will be placed before Y in the serial order that the system guarantees equivalence to.
Classification of Serializable Systems
Systems that guarantee strict serializability eliminate all types of time travel anomalies. At the other end of the spectrum, systems that guarantee “only” one-copy serializability are vulnerable to all of the anomalies that we’ve discussed in this post (even though they are immune to the isolation anomalies we discussed in a previous post). There also exist systems that guarantee a version of serializability between these two extremes. One example are “strong session serializable” systems that guarantee strict serializability of transactions within the same session, but otherwise only one-copy serializability. Another example are "strong write serializable" systems that guarantee strict serializability for all transactions that insert or update data, but only one-copy serializability for read-only transactions. This isolation level is commonly implemented by read-only replica systems where all update transactions go to the master replica which processes them with strict serializability. These updates are asynchronously replicated to read-only replicas in the order they were processed at the master. Reads from the replicas may be stale, but they are still serializable. A third class of systems are "strong partition serializable" systems that guarantee strict serializability only on a per-partition basis. Data is divided into a number of disjoint partitions. Within each partition, transactions that access data within that partition are guaranteed to be strictly serializable. But otherwise, the system only guarantees one-copy serializability. This isolation level can be implemented by synchronously replicating writes within a partition, but avoiding coordination across partitions for disjoint writes. Now that we have given names to these different levels of serializability, we can summarize the anomalies to which they are vulnerable with a simple chart:
| System Guarantee | Immortal write | Stale read | Causal reverse |
| ONE COPY SERIALIZABLE | Possible | Possible | Possible |
| STRONG SESSION SERIALIZABLE | Possible (but not within same session) | Possible (but not within same session) | Possible (but not within same session) |
| STRONG WRITE SERIALIZABLE | Not Possible | Possible | Not Possible |
| STRONG PARTITIONED SERIALIZABLE | Not Possible | Not Possible | Possible |
| STRICT SERIALIZABLE | Not Possible | Not Possible | Not Possible |
For readers who read my previous post on isolation levels, we can combine the isolation anomalies from that post with the time travel anomalies from this post to get a single table with all the anomalies we’ve discussed across the two posts:
| System Guarantee | Dirty read | Non-repeatable read | Phantom Read | Write Skew | Immortal write | Stale read | Causal reverse |
| READ UNCOMMITTED | Possible | Possible | Possible | Possible | Possible | Possible | Possible |
| READ COMMITTED | Not Possible | Possible | Possible | Possible | Possible | Possible | Possible |
| REPEATABLE READ | Not Possible | Not Possible | Possible | Possible | Possible | Possible | Possible |
| SNAPSHOT ISOLATION | Not Possible | Not Possible | Not Possible | Possible | Possible | Possible | Possible |
| SERIALIZABLE / ONE COPY SERIALIZABLE / STRONG SESSION SERIALIZABLE | Not Possible | Not Possible | Not Possible | Not Possible | Possible | Possible | Possible |
| STRONG WRITE SERIALIZABLE | Not Possible | Not Possible | Not Possible | Not Possible | Not Possible | Possible | Not Possible |
| STRONG PARTITIONED SERIALIZABLE | Not Possible | Not Possible | Not Possible | Not Possible | Not Possible | Not Possible | Possible |
| STRICT SERIALIZABLE | Not Possible | Not Possible | Not Possible | Not Possible | Not Possible | Not Possible | Not Possible |
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.