
Build a Serverless multi-tenant SaaS app with AWS and Fauna
Kirk Kirkconnell , Zee Khoo & Sathya Balakrishnan |Nov 6th, 2023|
Introduction
Building a multi-tenant Software as a Service (SaaS) application poses unique challenges in architecture, particularly when it comes to balancing isolation with operational efficiency. This blog introduces an architecture pattern that addresses these complexities by integrating AWS serverless services with Fauna, a distributed document-relational database delivered as a cloud API. A serverless architecture allows development teams to focus on solution-specific logic, eliminating the need for instance management or capacity planning. With its built-in data isolation features and distributed ACID compliance, Fauna complements this by simplifying the database operations involved in a multi-tenant environment. Further, Fauna's Distributed Transaction Engine makes scaling to multiple-regions a breeze; Fauna automatically replicates data across various regions and directs queries to the nearest node to optimize for efficiency and low latency. Together, AWS and Fauna offer a pathway to building multi-tenant applications that are scalable, efficient, and secure.
If you’d like to dive deeper into this topic with a guided walk-through to develop and deploy a SaaS service with Fauna and AWS, check out the AWS workshop, AWS modernization workshop – Serverless SaaS + Fauna or the webinar recording that walks through the lab step-by-step.
Why Serverless?
AWS Serverless Services lets you focus on your solution without managing instances. You accelerate your time to market since serverless eliminates operational overhead. You only pay for what you use, allowing you to start from the initial onboarding of tenants to growing to a global scale. The elasticity of the underlying resources is significant in SaaS, as you may be unable to predict how much load initial tenants will put on your system. Most importantly, SaaS providers can focus on their IP instead of wasting resources on undifferentiated engineering concerns such as scaling and managing infrastructure.
Which data isolation model?
Organizations building a multi-tenant SaaS must address tenant and data isolation. The reference architecture below combines elements of the “siloed” and “pooled” deployment models. A “hybrid” model combines these two models, which provides the best balance between meeting isolation requirements and achieving operational efficiency. Opting for Fauna as your database in a SaaS architecture comes with the inherent advantage of a built-in solution to the data isolation dilemma.
Silo isolation vs. shared resources
A key challenge of the multi-tenant SaaS architecture is the isolation of tenant resources, complicated by the fact that there are multiple definitions of the term “isolation.” For some, isolation is a business construct driven by customer requirements necessitating separate infrastructure. Typically, isolation is an architectural construct overlaying the services and constructs of a multi-tenant environment. Regardless, isolation of tenant data is not optional. Every architecture must deliver a solution in a multi-tenant model at the data layer.
At the data-storage level, a silo model provides the best isolation but is operationally expensive to scale, with dedicated infrastructure. In contrast, the shared/pooled model scales better but has a few downsides, including noisy neighbor concerns and compliance pushback. One way to tackle these challenges is to leverage a serverless database service like Fauna, which natively handles data isolation in a multi-tenant environment. We discuss this in more detail in the architecture section below.
To read more about the guiding principles of isolation, follow this link to the SaaS Tenant Isolation Strategies whitepaper.
Reference architecture for SaaS at scale
For this section, we assume that you’re familiar with the concept of microservices as described in the following diagram:
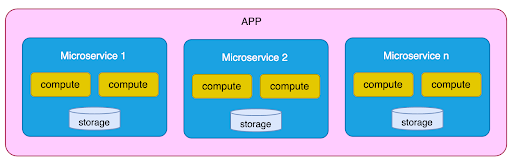 It is an approach to building a single application consisting of multiple services that operate independently, with each running in its own process and communicating via lightweight mechanisms like HTTP APIs. These services are organized around business capabilities, are loosely coupled, and are independently deployable. Essentially, each service’s ongoing development and maintenance is by its own small team, with minimal centralized management, potentially including which programming language to use and choice of data storage technologies. All this leads to enabling rapid, frequent, and reliable software delivery.
It is an approach to building a single application consisting of multiple services that operate independently, with each running in its own process and communicating via lightweight mechanisms like HTTP APIs. These services are organized around business capabilities, are loosely coupled, and are independently deployable. Essentially, each service’s ongoing development and maintenance is by its own small team, with minimal centralized management, potentially including which programming language to use and choice of data storage technologies. All this leads to enabling rapid, frequent, and reliable software delivery.

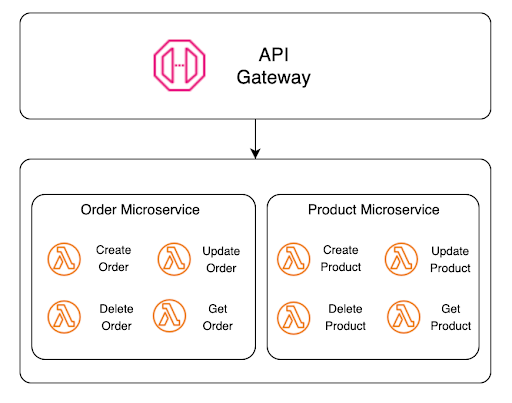
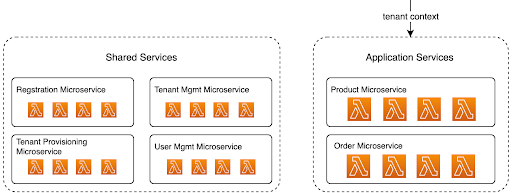
Serverless microservices
We can add the serverless delivery model further to enhance the agility and reliability of microservices architecture. There are only a few mental adjustments from a more traditional architecture. The primary one is that a microservice is different in a serverless environment. While each Lambda function could be a microservice, grouping a collection of functions to represent a logical microservice is more common. The diagram below details how we’ve done this grouping in our reference sample. Here, we have two microservices, Order and Product. Each service comprises four functions responsible for CRUD (Create, Read, Update, and Delete).
 Our reference architecture exemplifies a multi-tenant SaaS e-commerce platform. We describe the complete solution in the diagram below:
Our reference architecture exemplifies a multi-tenant SaaS e-commerce platform. We describe the complete solution in the diagram below:
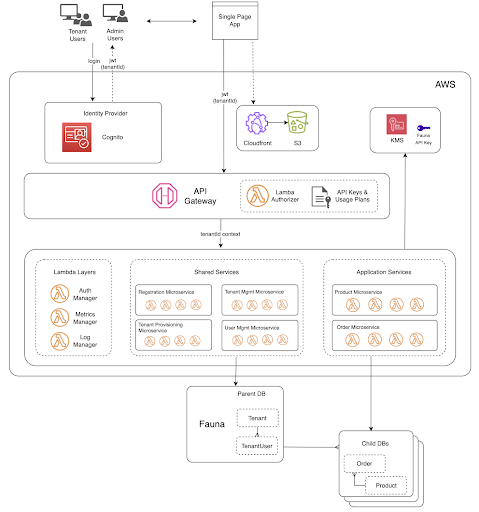


Single page application
On the front end, we have a Single Page Application (SPA) served by an Amazon S3 bucket behind an Amazon CloudFront distribution. SPAs are an implementation of front-end web applications, and most notably, since we are serverless, it does not rely on servers or instances. Instead, a single document is served to the browser once. Pages dynamically render using JavaScript in the browser, and the app fetches data using APIs.
HTTP everything
The SPA accesses the microservices by making REST API calls through Amazon API Gateway, which routes the traffic to the appropriate function within each of our microservices. The Lambda functions interact with Fauna by issuing queries through a lightweight client and authenticating via an API Key. The communication protocol between the AWS Lambda functions and Fauna is HTTP, keeping things lightweight, stateless, and unconcerned about the ephemeral nature of AWS Lambda functions. Because of the simplicity this solution affords you, there is no need for additional middleware to maintain connection pools, adding cost, complexity, latency, and points of failure to the mix.
Identity provider
Amazon Cognito is an AWS service that provides an identity platform for web and mobile apps. It’s a user directory, an authentication server, and an authorization service for OAuth 2.0 access tokens. In a multi-tenant environment, the “Identity Provider” plays a crucial role in the architecture and is a shared service amongst all the tenants. When a user accesses the app, the first component they touch is the Identity Provider – by logging in. As a user directory, it stores user credentials and other profile information, such as their name and role and, more importantly, what tenant they belong to.
Upon successful authentication, Amazon Cognito provides the user context to the application via the OAuth 2.0 JSON Web Token (JWT), which gets redirected to the single-page application we referenced earlier. This JWT contains the “tenant ID” as a custom claim, which passes along with the JWT to Amazon API Gateway. Amazon API Gateway then uses an AWS Lambda Authorizer to validate the token and extract the tenant context. The Lambda authorizer also works with the API Gateway to allow specific methods/routes based upon the user’s role (As an example, only system admins and tenant admins can create tenants). This tenant context also passes to the Lambda functions. It becomes the basis for driving multi-tenant observability and tenant data segregation we talk about below.
Fauna’s document-relational database
Fauna's document-relational model combines the scale, performance, and flexibility of a document database with the consistency, querying power, and relationships of a relational database. What differentiates Fauna from traditional databases in two key ways relevant to this architecture:
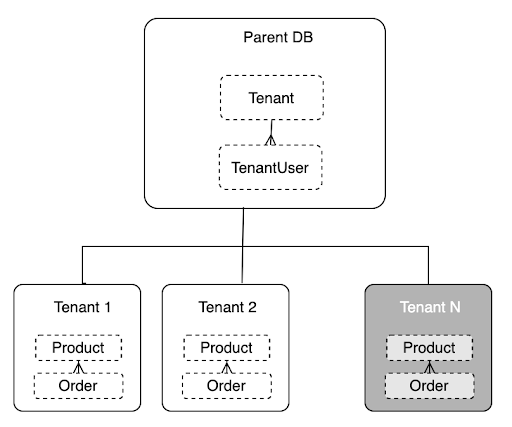
- Parent-child databases - Fauna’s ability to support a hierarchical parent-child database structure is extremely useful for implementing data isolation in multi-tenant environments. In this reference architecture, every tenant uses their own database, each logically isolated from one another. We get data isolation, but you design your application code and data model as if operating with a single-tenant system. These benefits significantly reduce cognitive overhead, minimize errors in your code, and accelerate feature development. As you can imagine, this advantage is significant for the development, testing, and deployment of new features to your SaaS.
- Multi-region replication - With Fauna, you get, by default, strongly consistent, globally distributed, ACID transactions with three different region group options available. Region groups in Fauna are how one selects which geographies a Fauna database is replicated to. With this feature, developers write code as if the app is a single region only, but get the advantages of being multi-regional and strongly consistent across those regions.

Writing apps for a single tenant, but inherently operating with multiple tenants
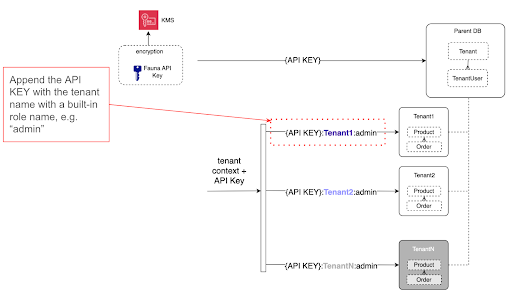
In the identity provider section, you read how JWTs pass with a user context originating from Amazon Cognito. That identity is ultimately passed to Lambda functions and appended to the Fauna API key, creating what Fauna calls a scoped key. What’s distinctive about Fauna’s authentication mechanism is that a database’s API key can grant access to its child databases with that scoped key. Since Lambda functions have and pass on the tenant context in the key, Fauna uses that to determine which child databases the calling function is authorized to query and sends the traffic there. We describe the mechanism in the following diagram:

Multi-region replication by default
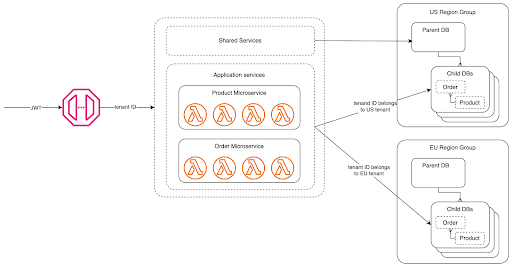
With the ability to run in multiple regions by default, Fauna’s distributed nature lends itself well to applications with global customers. You can read from the region local to your application for decreased latency, but writes are strongly consistent ACID transactions across the region group your database spans. And while your data may be replicated across multiple regions, Fauna deploys those replicas within data jurisdiction lines. For example, the US region group replicas are within US borders, and the EU region group is within the EU borders. This allows customers to easily conform to data residency regulations, such as GDPR. When it comes to your application, you can enhance your database routing logic to partition user data by geography. For example, customer A is in a database in Fauna’s EU region group, but customer B’s database is in the global region group. For more information, read Inside Fauna’s distributed transaction engine.
on Fauna’s distributed transaction engine,

Conclusion
Building a multi-tenant SaaS application involves navigating complex architectural and operational challenges. AWS serverless services and Fauna's database provide a well-matched solution. AWS delivers agility and scalability with the core building blocks for a serverless multi-tenant and multi-region SaaS architecture, while Fauna addresses data isolation and cross-region ACID-compliant writes. This combined approach allows for a flexible and secure framework, with the option to make adaptations based on specific use cases and needs. For example, here are two variations on the reference architecture in the blog that might be of interest:
1. Instead of AWS Lambda and Amazon API Gateway, the microservice code runs in Lambda@Edge (a feature of Amazon CloudFront), which would talk directly to your databases in Fauna using an API key. You can mix and match these solutions on a per-microservice basis.
2. Your JavaScript code runs in a user’s browser and talks directly to Fauna utilizing OAuth2 token providers, like Auth0. No middleware, no websockets.
If you’d like to dive deeper into this topic with a guided walk-through to develop and deploy a SaaS service with Fauna and AWS, check out the AWS workshop, AWS modernization workshop – Serverless SaaS + Fauna. Sign-up for a free Fauna account to get started, check out the Fauna community forums to engage with fellow builders, and get in touch if you have any questions!If you’re currently building on AWS and interested in exploring implementing Fauna, check out Fauna’s listing on AWS Marketplace. Purchasing Fauna on AWS Marketplace allows you to draw down your EDP commitment.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.