

How Hannon Hill’s personalization application supports up to 4.6M daily transactions with Fauna and AWS
Case study
Fauna + AWS + Hannon Hill
Read on to learn how Hannon Hill future proofed its fast growing SaaS personalization tool, Clive, with Fauna and AWS.
➡️ About Hannon Hill and Clive
➡️ Project background: Building a greenfield app with significant scale
➡️ Clive application requirements
➡️ Clive architecture overview
About Hannon Hill and Clive
Hannon Hill is a leading software provider that offers user-friendly, powerful, and flexible web content management solutions for businesses, universities, and government agencies worldwide. Their flagship product, Cascade CMS, is the most used CMS solution for universities and colleges. Across their suite of products, Hannon Hill’s digital solutions are designed to simplify the content creation and publishing process, while also providing advanced features like personalization and analytics as add-ons for Cascade CMS as well as third-party CMSes.
Modern consumers expect websites to serve data quickly, accurately, and contextually — and this is certainly true for visitors to websites hosted by CMS solutions like Cascade CMS. Web personalization technology allows companies to serve information that’s tailored for a particular customer based on their unique set of attributes. To address these expectations, Hannon Hill built Clive — a real-time web personalization tool that integrates natively with Cascade CMS, and also can be plugged into any CMS solution. Clive delivers a better visitor experience by offering more targeted content based on form submissions, location, and digital activity (like page views and search terms), which in turn helps drive deeper engagement. Clive offers their CMS customers full visibility to visitors, leads, and conversions at each interaction, ultimately generating increased revenue and customer satisfaction.
The challenge: Building a greenfield app with significant scale
The broader Cascade CMS architecture was built on a legacy stack delivered in a hybrid on-premises/hosted environment that largely served its purposes well from a performance perspective. Artur Tomusiak, Senior Software Engineer at Hannon Hill, explained, “Cascade CMS comes in the form of an instance installed on a machine. This works well because Cascade CMS is a push CMS, meaning only a handful of content managers log in to the system.”
Before implementing Clive, the Hannon Hill team prototyped a content personalization system with Grails and MySQL, but encountered many performance issues related to fetching, filtering, queue processing, and paginating data from millions or billions of rows in the database. While this architecture was performant for the Cascade CMS use case, as Tomusiak and his team began to scope out the requirements for Clive, they realized that the underlying architecture would have to be built with scale in mind.
Hannon Hill anticipated significant variability in visitor traffic depending on the time of day and so needed to accommodate the novel demands of a personalization tool that served live content to a distributed audience with frequent spikes in web traffic. The Clive development team anticipated significant variability in visitor traffic depending on the time of day.
Tomusiak explained that “with Clive, we need to serve live content directly to the visitors, which means that with a popular enough website, a single machine would not be able to handle all the demand and we needed a more scalable solution. The duty of serving live data to potentially millions of website visitors is decoupled and delegated to web servers.”
Clive application requirements
It was clear that the Hannon Hill team would need to build Clive with a more modern architecture, but there was a broader set of requirements to consider in order to select the right set of technologies.
No ops and API-first
Hannon Hill not only needed an architecture that could scale, but also one that could do so without performance concessions or having to manually configure the underlying technology to accommodate scale. Tomusiak’s team previously spent significant time each month on undifferentiated maintenance activities with their legacy stack, so they also wanted to reduce the amount of code to write and maintain, both in the independent pieces of the architecture and their respective integrations. The Hannon Hill team needed scalable, distributed solutions that also offered light-weight integrations via API. Automatic distribution was important to avoid having to reconfigure the application’s architecture as the number of 3rd party CMS’ using Clive increased in time (and the respective geographic distribution of their end users increased concurrently). This would also improve end-user performance as data would be served from the nearest possible node. While many serverless solutions are now available up and down the stack, most are only configured for single-region, have throughput or data size limits, or suffer from eventual consistency.
Elastic scaling
“Besides improved performance, our goal was also to move to more of a true managed service, where we do not need to maintain instances or scale them ourselves,” shared Tomusiak. The aforementioned frequent traffic spikes characteristic of Clive mandated true serverless solutions that could scale down to zero to accommodate quiet periods without having to pay a tax on provisioned capacity based on peak demand.
Dynamic data modeling
The Clive team knew they would need to adjust the application’s data model and functionality over time as the Clive user base grew. They were anticipating large document sizes and consistent changes, so the architecture would need to accommodate both frequent traffic spikes and large, heterogeneous data loads.
Parallel data processing
Tomusiak described how “thousands or millions of visitors can be accessing client websites at the same time,” so an architecture that was optimized to avoid lock waits and timeouts due to transaction contention was critical to deliver a superior user experience.
Application architecture
Tomusiak and the Clive team ultimately adopted a full serverless architecture to deliver a world-class customer and developer experience that would not only decrease costs, but also increase productivity and accommodate variable demand. “Instead of taking care of load balancing and manually scaling servers and a database with a classic three-tiered architecture, we decided to go the serverless route, and a stack with AWS, Fauna, and the Serverless Framework turned out to be the best option.”
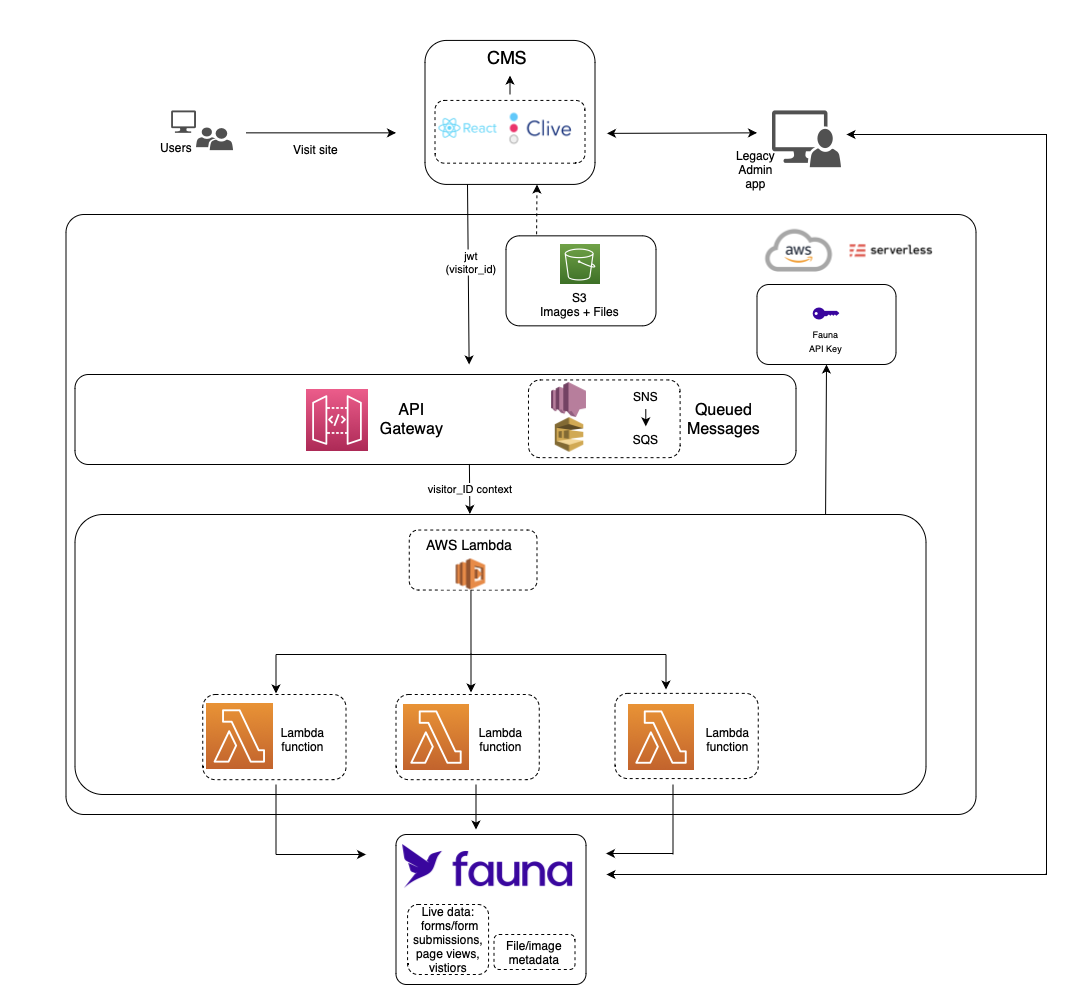
Fauna stores and serves the live data for visitors hitting web properties using Clive, such as forms, form submissions, visitors, and page views. AWS S3 is used to store files and images, Amazon API Gateway directs traffic, AWS Lambda, SQS and SNS are used for queued and asynchronous jobs, and SES for sending emails.
The Clive frontend is built in React, while the Serverless Framework is used to deploy and manage the stack.
Tomusiak shared that, “the serverless architecture of Clive allows quick automatic scaling, so that most jobs are processed live without any need of queues, and even at times when queues are used, these queues do not get backed up.”
Why a Fauna + AWS serverless architecture
Data model flexibility
“At times model and schema changes are necessary. With hundreds of millions of rows, schema updates tend to take a very long time to get applied. To maximize uptime, such updates are typically executed in the background row by row while the app is running. This can be a challenge to implement, since the app needs to be able to handle the data in both schema formats.” Tomusiak continued, “Thanks to the fact that Fauna documents do not have to follow a specific schema, we are able to avoid many such updates altogether, saving us a lot of time, effort and saving our users from running into potential bugs.”
Fauna’s support for semi-structured data and schemaless architectures addresses Clive’s flexibility requirement. Fauna’s document-relational data model delivers the querying capability of a relational database with the flexibility of documents, while its distributed transaction engine built on the Calvin consensus protocol guarantees strictly serializable writes over disparate globally deployed replicas. As a result, it delivers predictable low latency read/write access no matter where visitors are accessing Clive from, as well as offers protection against data loss from infrastructure failures.
API delivery model & serverless architecture
AWS Lambda compute functions are ephemeral in nature; the HTTP interface provided by Fauna allows AWS Lambda to communicate with the database in a lightweight and efficient manner, minimizing latency and maximizing throughput. Fauna offers a truly serverless model with instant provisioning, auto-scaling & replication, and zero configuration or tuning. This allows Hannon Hill’s developers to build scalable and flexible applications that can handle large volumes of data without having to manage the infrastructure. Fauna and AWS’ serverless and connectionless technologies don’t require maintaining burdensome TCP/IP connections.
Auto-scaling and support for parallel transactions
Based both on the nature of Clive as a product and its growth potential, Hannon Hill needed database and compute solutions that could scale up and down both in terms of being able to handle a large number of requests in parallel and in terms of max database size. Hannon Hill currently handles traffic from as low as 5k requests per hour up to ~200k requests per hour depending on the time of the day. These transactions hit both the the client side and the database.
“Some of our client accounts have accumulated many millions of visitors, visits, and page views. Fauna allows administrators to browse that data quickly using cursor-based pagination, no matter what page the user is currently viewing and no matter how big the dataset is. This is a clear improvement over our legacy tooling where loading large data tables with hundreds of pages was resulting in sluggish performance.”
“Fauna handles parallel transactions very nicely as well,” Tomusiak explained. “Thousands or millions of visitors can be accessing client websites at the same time, yet no transactional blocking errors occur — preventing creation of duplicate documents, double counts etc., without much of an effort. This is a much better developer experience compared to MySQL, where we were running into issues with transactional blocking and we had to spend a good amount of time tweaking locking levels to get things to work right. We didn’t want to cause too much contention, and also not create duplicates.”
Business outcomes and conclusion
Ultimately, technology is all about offering increasingly more value with increasingly less effort. Clive’s serverless stack built on Fauna and AWS delivers on this objective.
Business optimization
Due to the variability of Clive’s workloads, Hannon Hill didn’t want to pay for provisioned/pre-defined throughput that would lead to paying for peak capacity regardless of actual usage. “The usage-based billing model of the AWS tooling and Fauna delivers zero cost when there is zero or near-zero usage; there’s no need to pay for minimum or pre-defined throughput.”
Time savings
“We average out about 15 hours a month spent on maintaining servers of the legacy non-serverless product while maintenance related tasks for Fauna and Lambda were negligible.”
The combination of Fauna and AWS serverless tools offered a superior architecture for building and deploying Hannon Hill’s modern SaaS product. With Fauna's flexible and scalable database architecture and AWS serverless tools, Hannon Hill developers can focus on building the best application for their customers without worrying about managing the underlying infrastructure and servers. Together, these two technologies empower Clive developers to build a world-class product quickly and easily.
Fauna is available on AWS Marketplace and startups working with
AWS Activate can access a special offer through the AWS Activate console.
If you’re interested in learning how Fauna’s serverless database can help you support your SaaS application, get in touch with one of our experts.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.