

Building Fauna’s GDPR-compliant distributed and scalable database infrastructure with Pulumi
Introduction
Data residency has become a requirement for our customers due to regulations such as General Data Protection Regulation (GDPR) and Federal Information Processing Standards (FIPS). To enable our customers to more easily meet those requirements and lay a foundation that would allow Fauna to rapidly expand our presence across the globe, we introduced Region Groups. Region Groups allow our customers to keep their data resident to a specific geography, without sacrificing the benefits of distributed data. This capability ensures that customers can meet compliance policies, reduce latencies to their core customers, and maintain data residency with high availability.
We made this capability extremely simple for our customers— just select the Region Group to create a database in and start accessing via the associated URL. And like everything with Fauna, zero database operations required!
Behind the scenes, Fauna is responsible for managing the data distribution and scaling the resources required within that Region Group. As is often the case, providing this simplicity to customers required us to overcome significant engineering challenges. This article outlines those challenges, the tools we used to overcome them, and ways in which we took advantage of those tools to bring Region Groups to our customers.
Business requirements
Each Fauna database is backed by a cluster of nodes across multiple regions and cloud providers (AWS, GCP, Azure, etc.). Region Groups are multiple database clusters located in specific geographic locations.
The system is naturally stateful and does not lend itself well to auto-scaling. Scaling a cluster still needs to be simple, efficient, and repeatable. Similarly, we need to spin up new clusters in a Region Group based on customer demands in a matter of hours.
Technical challenges
Repeatable, scalable, efficient, and maintainable infrastructure management is a challenge that many organizations face. And one of our core customer value propositions at Fauna is to remove all of these burdens for our customers so they don’t have to manage and scale their database infrastructure. Thankfully, several tools have emerged from the industry to help us tackle these challenges. These tools typically center around the idea that infrastructure should be encoded, tracked, and versioned: that infrastructure is treated as code.
Tools like Pulumi, Terraform, and CloudFormation reduce the number of steps a human operator needs to take when modifying infrastructure.They enable operators to define their infrastructure in code that can be reviewed and audited. They provide opportunities to create templates that can be used to stamp out multiple copies of large sets of infrastructure.
Automation tooling requirements
For our use case, we needed a tool that's easy to adopt, flexible, and works across providers. CloudFormation was a no-go as it works with AWS only. We took a look at Terraform, but couldn't quite fit it to what we were trying to achieve. We knew we'd be building out several nearly identical clusters and wanted to ensure the process for building them would be quick, simple, and robust. We didn't see a way to do that in Terraform without purchasing or building a tool that would let us create reusable templates. Terraform's provider management also got in our way when we needed to be able to spin up infrastructure across AWS regions and we couldn’t make it easy to use temporary credentials generated on-demand.
Pulumi ticked all of our boxes and then some. We can use a language we're already familiar with. It enables us to model infrastructure using standard object-oriented programming paradigms, review infrastructure changes via our existing code review processes, and run unit tests against those objects. Pulumi projects and stacks allow us to split our code into smaller pieces to simplify changes and reduce the number of resources potentially affected by any change, thus limiting the potential blast radius of bugs.
Modeling our infrastructure
Every new Region Group consists of one or more clusters. As mentioned above, each cluster resides within its own AWS account and/or GCP project. Within that account, the cluster needs a VPC, subnets, VMs, and load balancers in each designated region of the Region Group.
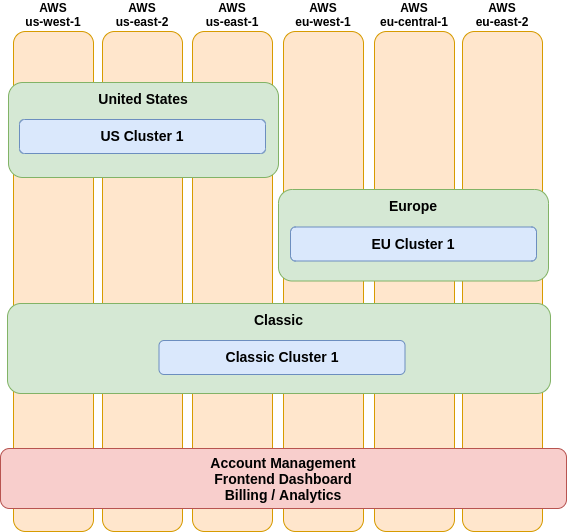
In the early days of the Region Groups project, we started by thinking about how we wanted to define our topology. We decided that a Region Group needed to contain multiple clusters, a cluster would have various replicas, and replicas would contain multiple nodes. A replica is deployed to a designated cloud provider's region and the nodes within a replica all run on identical machine profiles, one node per machine. We can lay this out very succinctly in YAML.
region_groups:
us:
cluster-1:
replica-1:
provider: aws
zone: us-east-2a
cidr: 10.1.0.0/16
machine: m5d.large
nodes: [0, 1, 2]
replica-2:
provider: aws
zone: us-west-2a
cidr: 10.2.0.0/16
machine: m5d.large
nodes: [0, 1, 2]
replica-3:
...
eu:
cluster-1:
replica-1:
...Pulumi makes it easy to derive all infrastructure changes from this configuration file because we can use standard Python libraries and control flows. We defined the schema of the configuration and ensured its correctness using a validator that we wrote. We translated the configuration to infrastructure by mapping it to Pulumi resources. All of that is straightforward because we layer our Python libraries on top of Pulumi's libraries.
After determining how we wanted to define Region Group configuration, we needed to choose how to model the infrastructure in Pulumi. We needed to ensure bad changes would impact the fewest customers possible, always aiming for zero customer impact. We split our infrastructure code into multiple projects and tied them together with a structured naming scheme to achieve that goal.
Infrastructure is split into projects based on how likely they are to be modified. We thought about how infrastructure can be layered together: load balancers depend on instances which depend on networks and all of it exists within an account along with access roles and policies. Accounts and the roles and policies governing access to resources within the account are rarely modified. Networks are more likely to be modified, but only if we add or remove replicas. The number of nodes in a replica, however, will expand and contract with customer demand. Finally, load balancers may need to be updated to add or remove nodes from the load balance.
Given these layers we ended up with four projects:
- Account
- Network
- Replica
- Proxy
Within these projects, stacks are split up based on failure domains. Fauna is capable of losing a full replica while maintaining availability and consistency, so we've modelled our infrastructure such that making a change will only affect one replica at a time during rollout.
The account project is an exception in that it creates an AWS account and/or GCP project per cluster. Within the project, each stack represents a cluster and is named based on its environment, Region Group, and cluster using the naming scheme defined above. We also create IAM roles and service accounts during account creation, integrate monitoring services, and register the account with our infrastructure tracking tools. The new account ID and/or project name is then exported for consumption by downstream projects.
After accounts, networks are the next most stable resource. Once network resources have been created, there are very few reasons to change them. Each network stack manages the network configuration for a given replica. Pulumi's StackReference is used to pull in the exported account ID from the associated account stack. The CIDR is pulled from the main configuration file, also based on the stack's name. After the network resources have been created, the stack will export the subnet ID so the replica project can reference it when building VMs.
Finally, we have the replica project responsible for managing VMs and their associated security groups, instance profiles, and keys. Like the network project, each replica stack is responsible for a single replica. Each stack will create StackReferences to the account and network stacks based on their names.
The name indicates the environment, Region Group, cluster, and replica the stack is responsible for. For example, the name for replica 1 in cluster 1 in the US region group in the production environment is prod.us.cluster-1.replica-1. When a stack pulls configuration from the main config file, it splits its name on the dot and uses the tokens as keys. Given the example configuration above, this name enables the stack to reference the replica in us-east-2a:
provider: aws
zone: us-east-2a
cidr: 10.1.0.0/16
machine: m5d.large
nodes: [0, 1, 2]Access control
Keeping infrastructure secure requires overlapping layers of access controls. If one layer is breached or misconfigured, there's another layer of protection backing it. We need to control who has access to our Pulumi account, who has access to particular stacks within that account, and who has access to the resources managed by those stacks. Managing access to Pulumi is done via SSO integration with our identity provider service. We use Pulumi's team management to control access to stacks and we've taken a novel approach to controlling access to those stacks' resources.
One way to provide access to resource credentials is through Pulumi's encrypted secrets management. However, that approach requires the use of long lived credentials that end up stored on any machine with access to the stack. Shared, long-lived credentials are the antithesis of good security practices. We wanted access to resources to be granted on-demand and for as short a period as possible. Pulumi's integration with HashiCorp's Vault provided an elegant solution.
Vault provides yet another layer of protection. The tools that require access to resources managed by Pulumi need to authenticate with Vault and be granted access through Vault policies. When a stack is updated, it will pull temporary credentials from Vault and use them to create providers.
Future improvements
Updating infrastructure continues to be semi-manual, in that an engineer still needs to run "pulumi up" to roll out changes. In the future, we plan to take advantage of Pulumi's new Automation API to further simplify and automate our infrastructure release process by running these changes through a CI/CD pipeline.
Concluding thoughts
We had a tight development window, a small team, and a major infrastructure platform to build. Pulumi allowed us to leverage concepts and tools we already knew, which reduced cognitive load and overall ramp up time. It gave us access to libraries that enabled us to build tooling that fit into our existing code. The team was, and continues to be, responsive and helpful when we need their help on tricky problems. We're looking forward to continuing our journey with Pulumi and leveraging the great work they've put into their product.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.