

Consistency without Clocks: The Fauna Distributed Transaction Protocol
Transactions are hard. Distributed transactions are harder. Distributed transactions over the WAN are final boss hardness. - Andy Pavlo
Fauna is a distributed database platform that supports strictly serializable, externally consistent transactions. Unlike Google Spanner or similar systems, Fauna does not rely on physical clock synchronization to maintain consistency. Also, unlike Google Percolator, FoundationDB, or similar systems, Fauna places no constraints on replica distance and is practical to deploy at global internet latencies.
This post describes how read-write and read only transactions are implemented in Fauna. We will start with some background and then explain how the core protocol maintains consistency across geographic distances. We then discuss the performance implications of Fauna’s architecture.
Background
Fauna is more specifically a Relational NoSQL database platform. The term "NoSQL" refers only to the interface; Fauna currently supports an execution-transparent, procedural interface instead of declarative SQL.
The term "relational" refers to the data model, but Fauna also supports graph and document models in addition to relational. It also invokes the customary guarantees of the RDBMS:
- ACID transactions with up to serializable isolation
- Linearizable, consistent operations across replicas
Unlike the legacy RDBMS, Fauna maintains these guarantees even when geographically distributed.
Serializable Isolation
Serializable isolation means that the system can process many transactions in parallel, but the final result is equivalent to processing them one after another. For most database systems, the order is not determined in advance. Instead, transactions are run in parallel, and some variant of locking is used to ensure that the final result is equivalent to some serial order.
Pre-Processing in Fauna
Fauna’s protocol, which was inspired by Calvin, decides on this serial order prior to performing any writes to the database. For each batch of parallel read-write transactions, they are inserted into a distributed, write-ahead transaction log and the Fauna execution engine ensures that the final result of processing this batch of transactions is equivalent to as if they were processed one-by-one in the order they appeared in this pre-generated log.
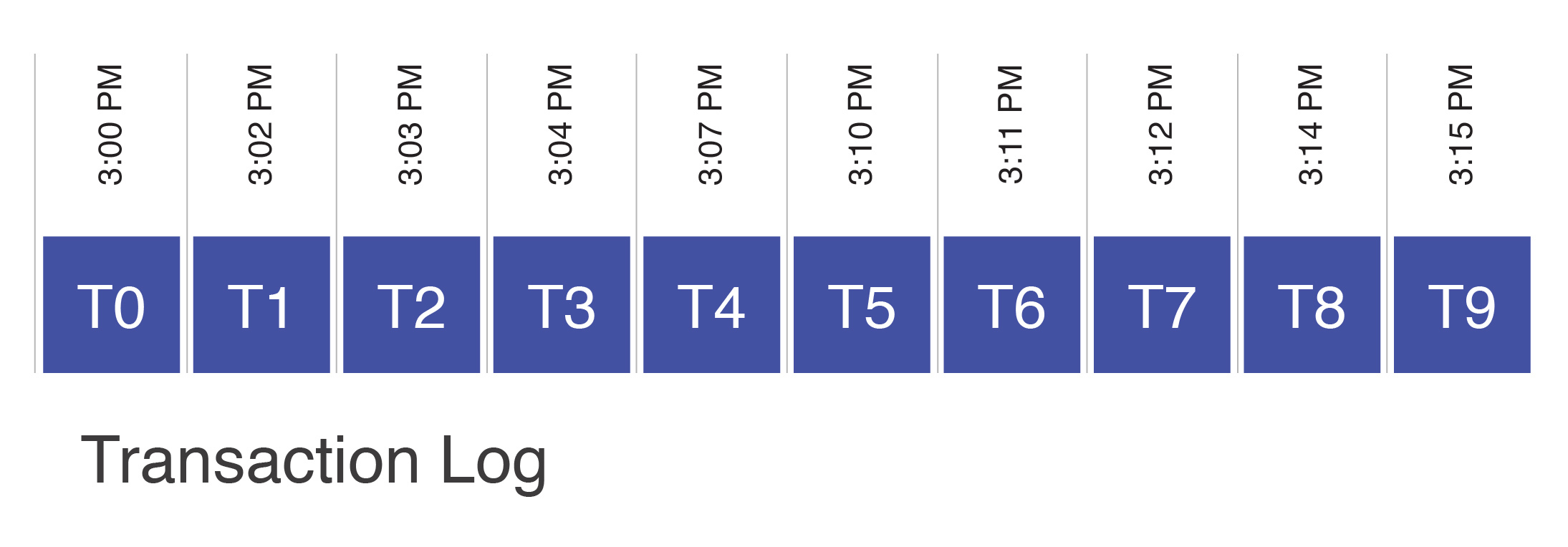
Each transaction in the log is associated with a real time. However, unlike other distributed databases, real time is not a central component of Fauna’s protocol, and Fauna does not rely on global synchronization of clocks across servers. Rough correspondence between "Fauna time" and real time is merely an affordance for the developer and not an operational constraint. Instead, the notion of "before" and "after" is entirely dependent on the order in which transactions appear in the distributed log.
Fauna can take a "snapshot" as of any point in the distributed log which includes the writes of all transactions that appear in the log before that point, and none after it. For example, a snapshot at T4 would contain transactions T0-T4, but none afterwards.
In order to quickly generate a snapshot at an arbitrary point in the log, Fauna keeps around multiple versions of each record. Each version is annotated with the timestamp—the transaction identifier in the transaction log—that wrote that version:
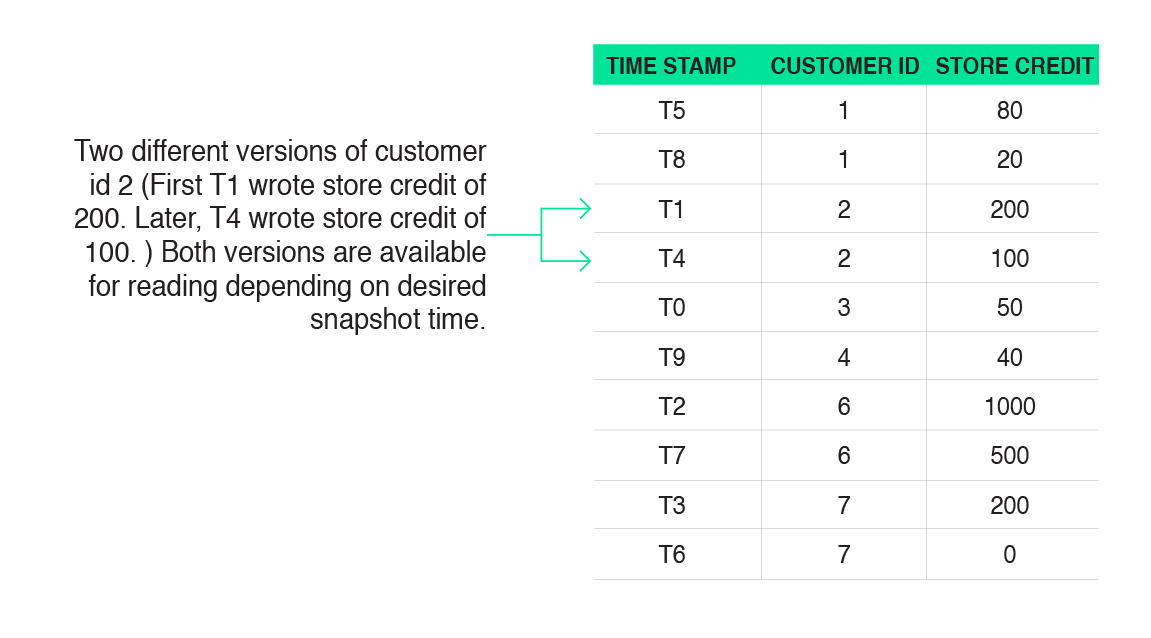
To read a snapshot as of a particular transaction in the log, say for example T3, the latest version of each record earlier than or equal to T3 is read. In the example of the record associated with customer 2 above, there are two potential versions to read: one written at T1 and the other at T4. Since T1 is the latest of these two options less than or equal to T3, that record is the one that is read in this example.
Fauna is a scalable system and it partitions large tables over multiple nodes. For example, let’s say we are deploying a retail application with two relational tables: the "customer" table (which was shown above) that indicates the customer id and store credit of all customers, and a "widget" table that shows the price of each widget for sale by that application and how many are left in stock. These two tables can be horizontally partitioned over an arbitrary number of nodes, as shown below:
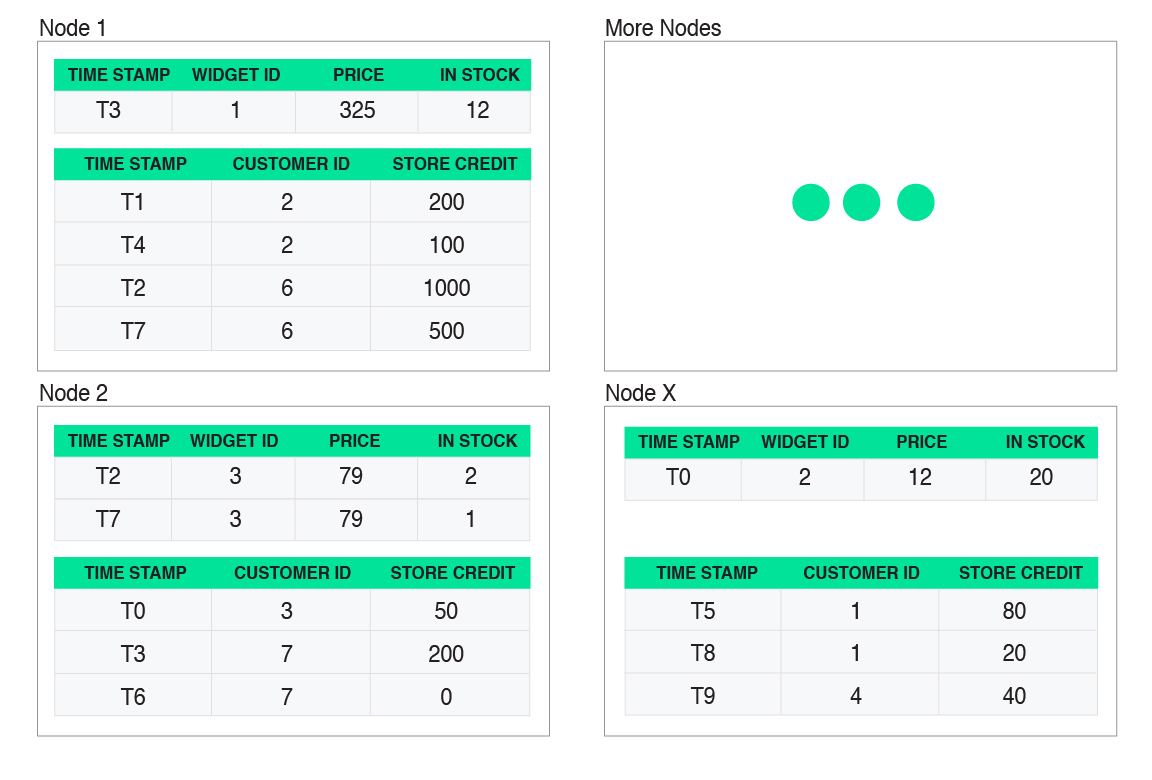
Fauna also replicates data, potentially over large geographic distances:
Clients can send transactions to any replica — both read-only transactions and transactions that update data in the database. However, there is only one transaction log for the entire Fauna deployment. Replicas must achieve consensus for how to insert new transactions into the log. Fauna uses an optimized Raft implementation to achieve consensus.
Summary
In Fauna, data is both partitioned and replicated across machines. Each partition contains multiple records (rows), and each record may have many versions associated with it. Each version is stored separately and is annotated with the transaction identifier that wrote that version. When a Fauna transaction needs to read data, it chooses a snapshot and reads the correct version based on which snapshot was chosen.
The Fauna Distributed Transaction Protocol
We will now describe the core Fauna transaction protocol. We will explain it through an example, by tracing the lifetime of a couple of example transactions that are submitted to the system. Let’s continue with the same example application that we discussed above: a retail application with two tables — one table providing information about the widgets being sold, and one table providing information about customers and how much store credit they have.
Let’s take the specific example where there is a widget being sold of which there is only one remaining (widget 3). Let’s assume that two customers attempt to buy it at approximately the same time. Further, let’s assume that these two customers are interacting with different replicas of the data — one customer with the replica in San Francisco, and the other with the replica in Washington, DC.
In other words, the following transaction is submitted to the replica in San Francisco:

And a very similar transaction is submitted to the replica in Washington, DC (the only difference is that a different customer is trying to purchase the same widget):

The server within a replica that receives the transaction request becomes the "coordinator" of that request. In the figure below, we see that the two transactions (for which we gave the pseudocode above) arrived at particular machines in San Francisco and Washington, DC respectively. Those machines become the coordinators of those two transactions.
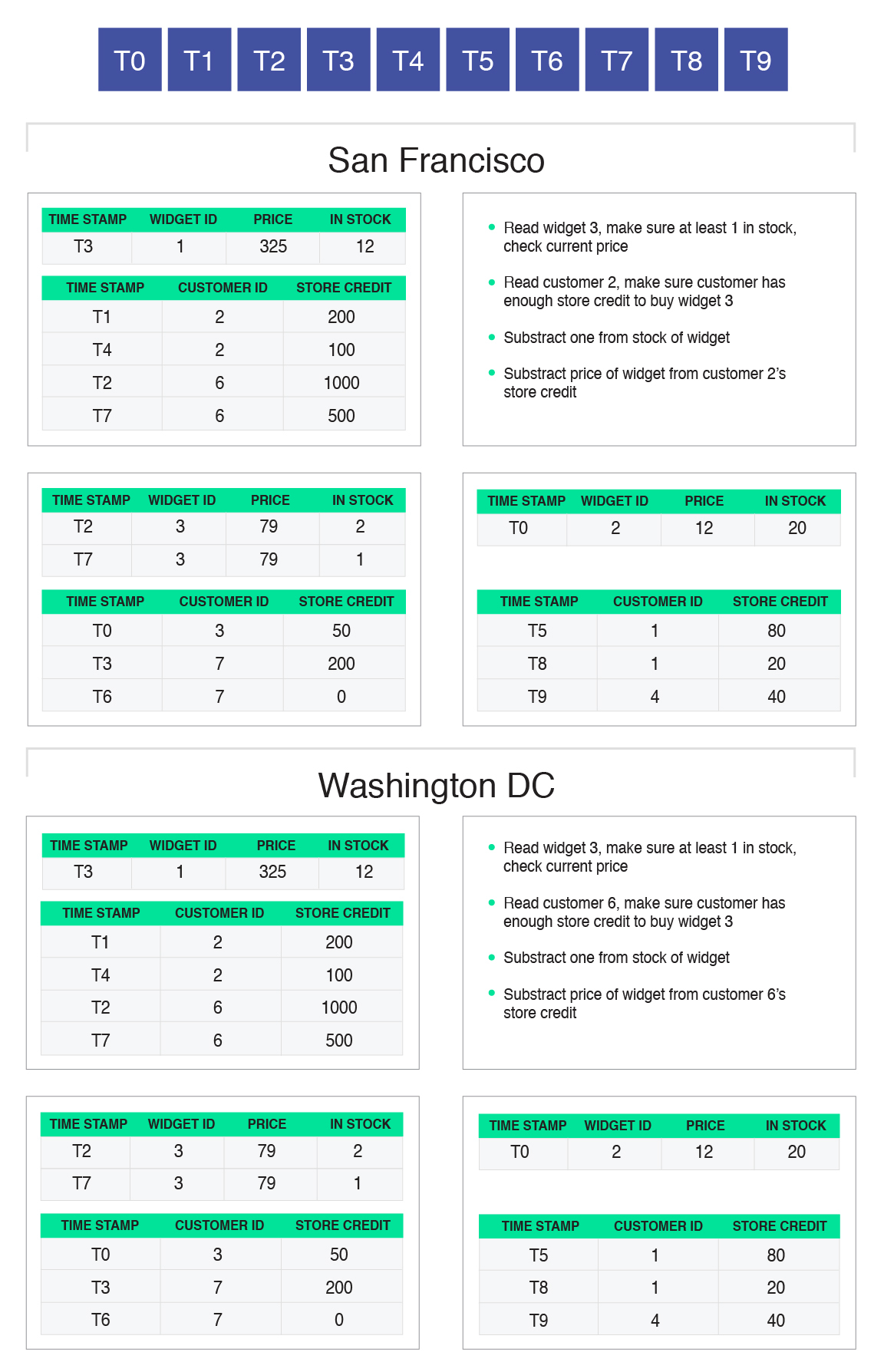
The coordinator executes the transaction code. In most cases, it will not have all of the relevant data locally, and thus will have to read data from nearby servers within the same replica that have the required partitions of data that are involved in the transaction request. It chooses a recent snapshot time (this choice can be arbitrary) and makes requests to the nearby servers to read data as of that snapshot. In our example, let’s assume that the coordinator for each of our two competing transactions chooses to read as of T9 (the most recent transaction in the distributed transaction log):
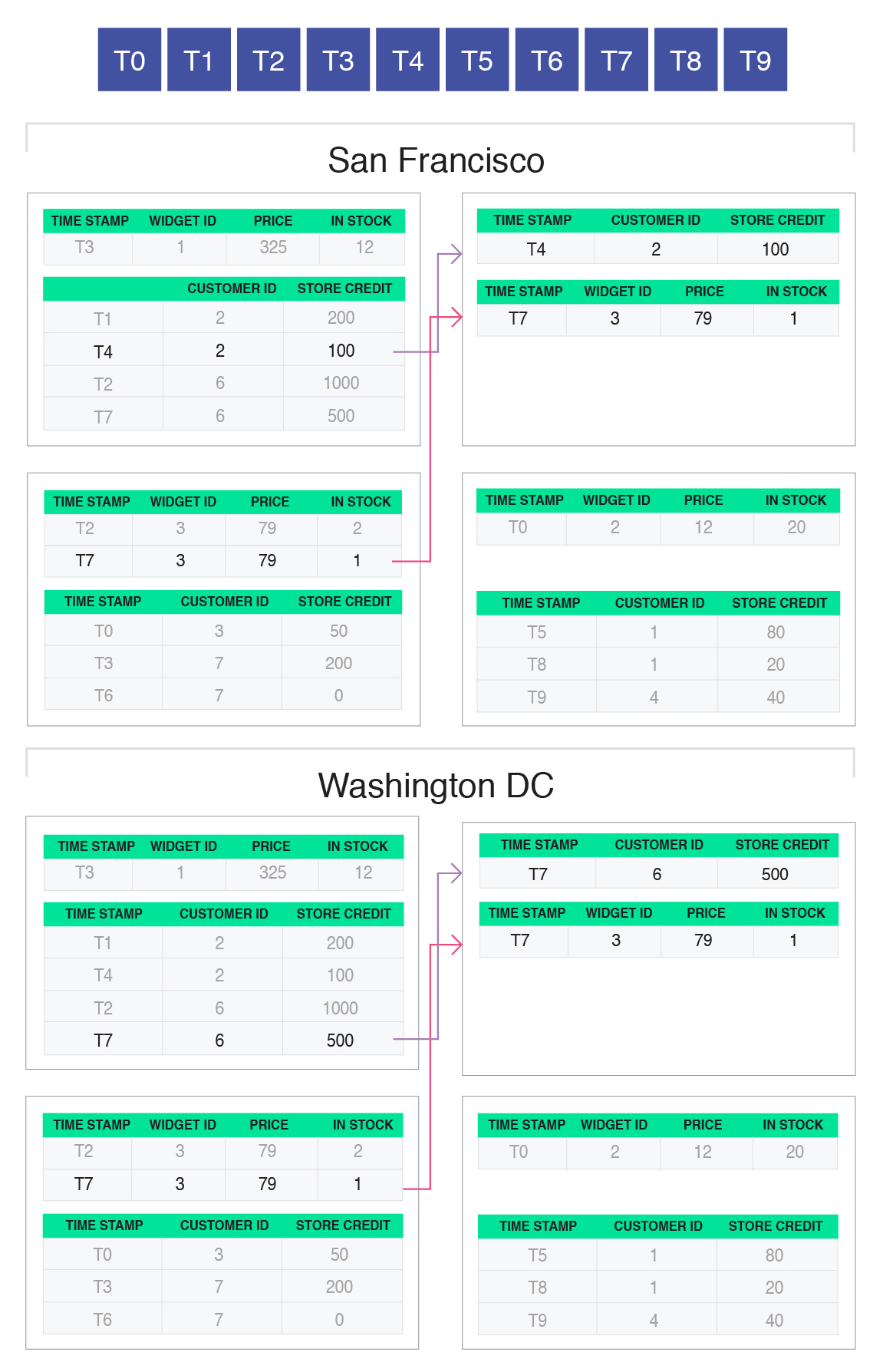
The transaction running in San Francisco is for customer 2 trying to buy widget 3. Therefore, the coordinator reads the two relevant records (for customer 2 and widget 3) as of snapshot T9. The transaction running in Washington, DC is for customer 6 trying to buy widget 3. Therefore, the coordinator reads the two relevant records (for customer 6 and widget 3) as of snapshot T9. The figure above shows the correct version of the records being sent from the machines where they are stored to the coordinator.
Recall that our example transaction performs some checks, and if they succeed, the transaction proceeds with updating the data (in particular, reducing the inventory of the widget and the store credit of the customer that bought the widget). The coordinator does not yet perform these writes. Instead, it just buffers them locally, keeping a record of which records it wants to write and what the new values should be:
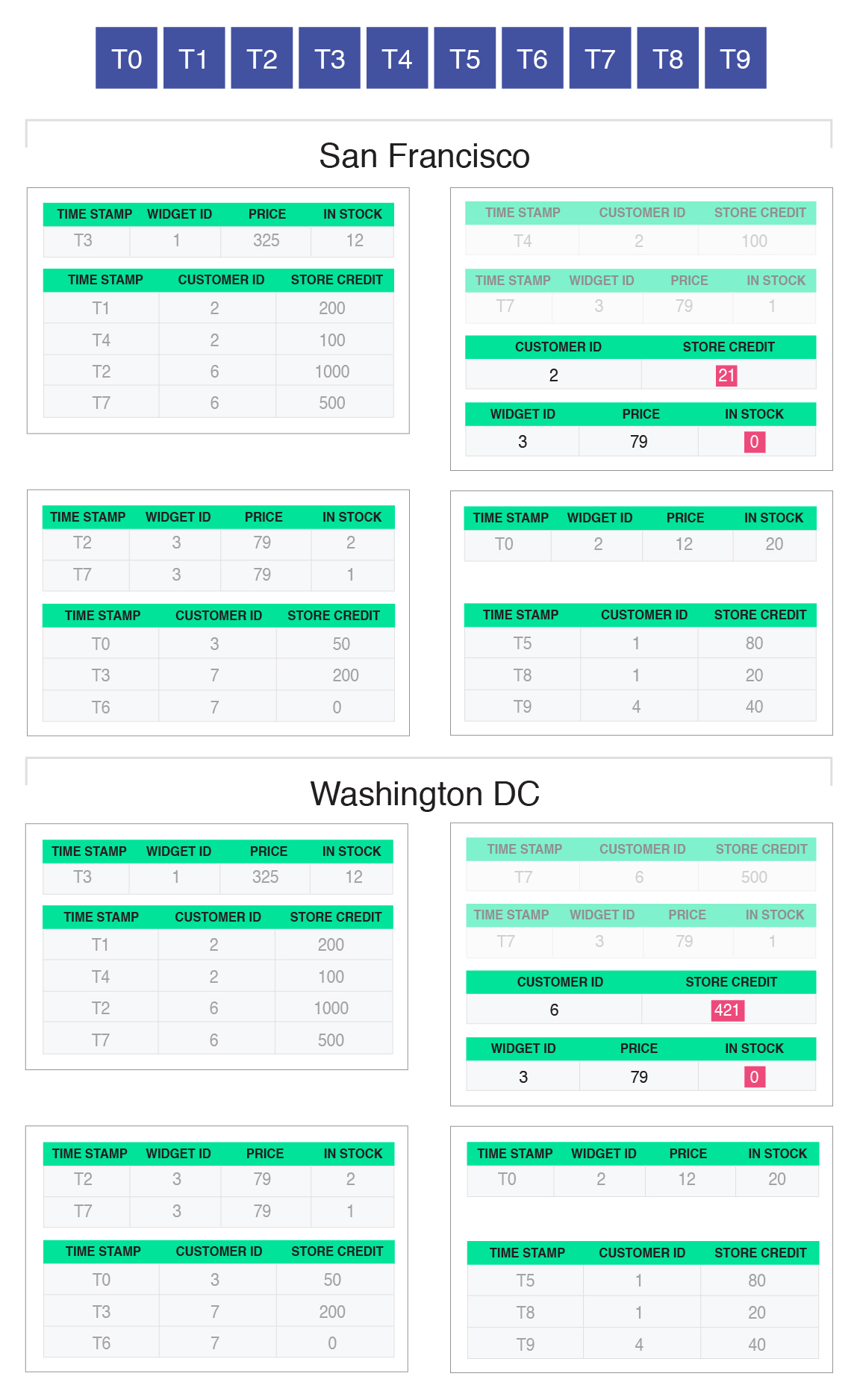
After completing all the transaction logic and buffering all writes, the coordinator is now ready to initiate the commit process. To do this, the coordinator attempts to insert this transaction into the distributed log (for scalability, this insertion process happens in batches, and the log itself is replicated and partitioned). The Raft protocol ensures that all replicas achieve consensus on the order in which batches of transactions (from any replica) are inserted into the distributed log. After being inserted into the log, the relative position of that transaction in the distributed log becomes the transaction identifier. The actual log entry contains the newly determined identifier, along with a record of all the reads and buffered writes that were performed by that transaction’s coordinator:
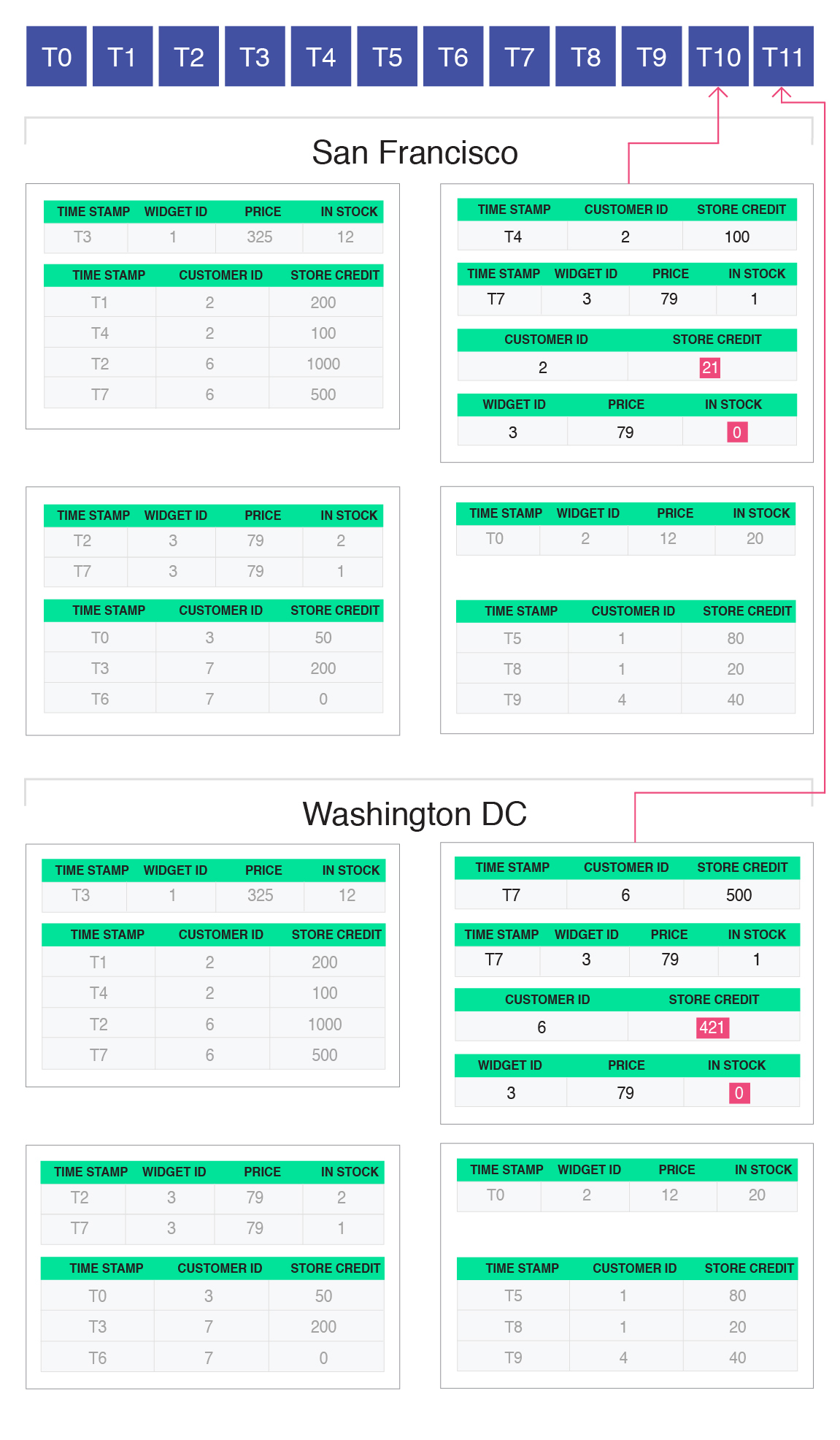
In our example, the transaction that was submitted to San Francisco got inserted into the log first (with an identifier of T10, and the one submitted to Washington, DC second (with an identifier of T11). The reads and writes of each of those two transactions (shown within the red rectangle) were included in the log entry when those two transactions were appended into the distributed log.
Inserting a transaction into the distributed transaction log is the only part of the Fauna protocol that requires consensus across replicas. This is a distinctive feature of Fauna—other geo-replicated systems require at least two rounds of global consensus.
Each replica independently reads from the distributed transaction log and attempts to commit each transaction in the log. Remember that each log entry contains all of the reads and writes performed by the coordinator of that transaction when it was originally processed. Furthermore, remember that the coordinator chose a snapshot at which to perform the reads prior to the transaction being inserted into the distributed log and receiving a distributed transaction identifier.
In order to properly guarantee global serializability, the correct snapshot at which to perform the reads for that transaction is the location of that transaction in the distributed log. Therefore, the snapshot at which the coordinator had performed the reads was earlier than the correct snapshot that would guarantee global serializability. To prevent serializability violations, each replica must perform the reads again, to see if the values changed between the snapshot at which they were originally read and the correct snapshot as of the transaction’s identifier in the distributed log:
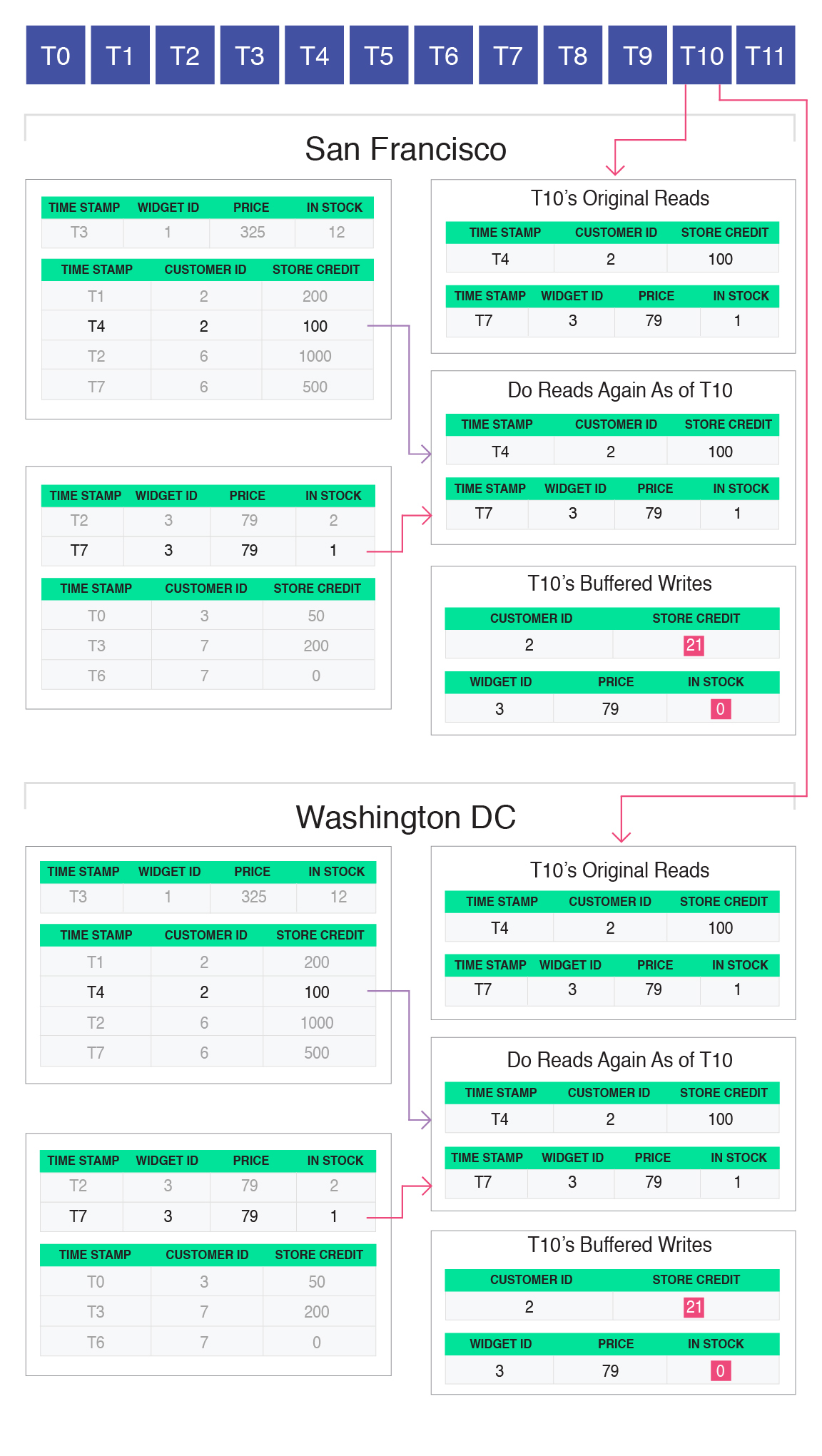
In the case of T10, the original reads were the same as the reads as of the correct snapshot. Therefore, the transaction can commit:
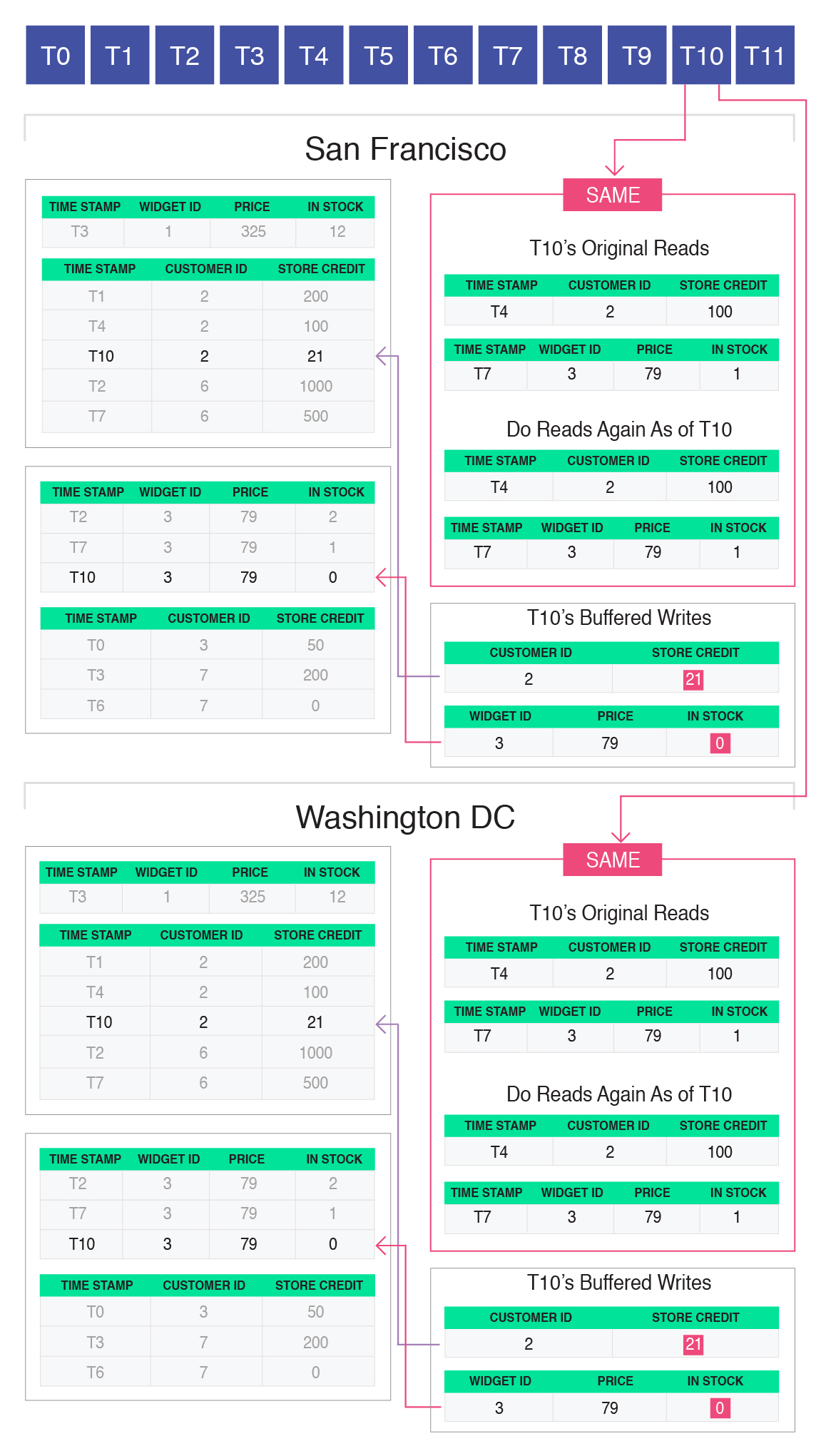
Note that the replicas perform this check independently from each other, reading from their local copy of the data. They will always come to the same conclusion about whether the reads changed or not. This is because each replica sees the same distributed transaction log, and therefore will always agree on the value of a snapshot as of a particular point in the log.
If the reads did not change from the original snapshot, the transaction can commit. To commit a transaction, the buffered writes are appended to the core tables, annotated with the transaction identifier given to that transaction. In the figure above, the new version of customer 2 and widget 3 are shown as inserted into the correct customer and widget partitions respectively, annotated with T10 — the transaction that wrote this new version.
In the case of T11, the original reads are different from the reads of the correct snapshot:
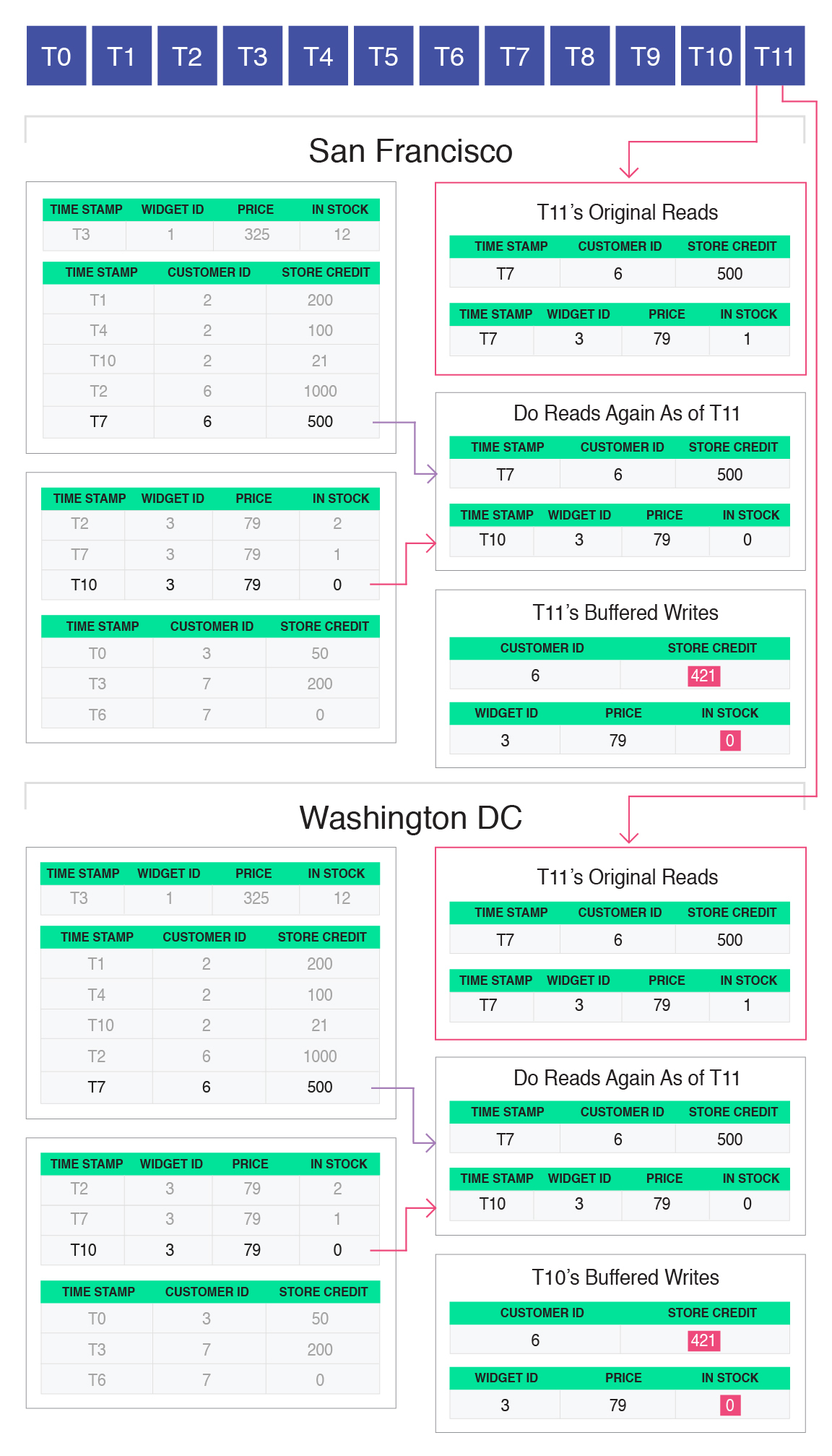
This is because the original reads were performed as of snapshot T9, but T10 appears before T11 in the distributed log, which updated the data (widget 3) that T11 reads. Therefore, the original read of widget 3 performed by the coordinator was incorrect, and the transaction needs to be aborted and restarted:

Each replica will independently figure out that the original read was incorrect, and thus independently decide to abort the transaction, without requiring any further coordination. When T11 gets restarted with the correct read set, it will see the inventory of widget 3 is 0, and thus customer 6 will be correctly notified that the purchase cannot proceed.
Multi-Region Consistency
The final result of our example from the previous section is that when two customers try to purchase the last item in the inventory at the same time, Fauna is able to correctly ensure that only one of these purchases succeeds. This is true even though the two customers trying to purchase the same item submit their respective transactions to different replicas of the database, and even though these regions are geographically distant from each other.
This ability to prevent this duplicate purchase stems from Fauna’s consistency guarantee: once a transaction commits, it is guaranteed that any subsequent read-write transaction—no matter which replica is processing it—will read all data that was written by the earlier transaction. Other NoSQL systems, and even most SQL systems, cannot guarantee global replica consistency. They allow replicas to temporarily diverge, and the result of a transaction may vary depending on which replica it is sent to.
For example, in an eventually consistent database system, the transaction that was submitted to the San Francisco replica and the transaction that was submitted to the Washington DC replica may both proceed and commit at their respective data centers, thereby potentially allowing multiple customers to believe that they have purchased the last item in the inventory. It is only at a later point, after the replicas eventually become consistent, that the system finds out that the same item was sold twice.
In such a scenario the application must take measures to repair the potential damage caused by this inconsistency. This dramatically increases the complexity of application development, and in many circumstances, for example, microservice environments where many separate services must interact, adding consistency in the application layer is not realistically possible.
In contrast, Fauna guarantees global consistency through deterministic processing of transactions in the order they appear in the global input log. Every read-write transaction, no matter where it originated from, gets written to the same log of input transactions where the order of transactions in this log is agreed upon through the Raft consensus protocol. The order of transactions in this log implies a linear order of global operations that is enforced by each replica and ensures that replicas remain consistent.
Summary
To summarize the overall Fauna protocol, each read-write transaction proceeds in three phases:
- The first phase is a speculative phase in which reads are performed as of a recent snapshot, and writes are buffered.
- Next, a consensus protocol is used (Raft) to insert the transaction into a distributed log, which results in the transaction receiving a global transaction identifier that specifies its equivalent serial order relative to all other transactions that are being processed by the system. This is the only point at which global consensus is required.
- Finally, a check begins in each replica which verifies the speculative work. If that speculative work did not result in potential violations of serializability guarantees, then the work becomes permanent and the buffered writes written back to the database. Otherwise, the transaction is aborted and restarted.
Performance Implications
In Fauna, only a single round of global consensus is required for even the most complicated of transactions. Furthermore, the consensus protocol is only being used for inserting transactions into a distributed log. For every other part of the protocol, replicas can proceed completely independently from each other. For example, serializable reads can be performed with no consensus whatsoever. This leads to several important performance implications:
- Transactions that update data only go through a single round of global consensus. Most other consistent database systems require at least two rounds of consensus. When data is geographically dispersed, consensus can be the dominant cost in a transaction. In such scenarios, Fauna is approximately half the latency of other database systems that require two rounds of consensus.
- Fauna does not require clock synchronization or bounds on clock skew uncertainty across machines in a deployment. Thus, Fauna’s architecture does not experience the latency cost of delaying transactions by clock skew uncertainty, a cost that is present in many other consistent database systems. Other systems are also subject to desynchronization, where consistency guarantees abandoned (potentially without detection) because the operator was not able to keep clock skew within bounds.
- By having a single distributed log, Fauna has a global notion of "Fauna time" that is agreed upon by every node in the system. A "timestamp" in Fauna is a logical concept and is simply the location in the distributed log. As a result, it is trivial for any node to serve data at a particular snapshot in time. The snapshot is a particular point between transactions in the distributed log, and a node that serves data as of this snapshot simply has to ensure that the snapshot includes all modifications by transactions prior to this location in the log, and not any of the modifications by transactions after this point. Consequently, any replica that has processed a sufficient prefix of the log can serve snapshot reads as of that point in time.
- Finally, by running on a transactionally complete read snapshot, read-only transactions are guaranteed to be serializable in Fauna. Fauna supports serializable snapshot reads with no consensus or locking, so they complete with local datacenter latency.
Conclusion
Fauna is an elegant, software-only solution for achieving global ACID transactions, with complete guarantees of serializability and consistency. Fauna requires no clock synchronization, no specialized hardware, and no atomic clocks.
The beauty of the Fauna transaction protocol is its simplicity. Fauna’s unique design enables a number of performance gains, allowing it to provide the usability advantages of serializable and consistent systems, while approaching the performance of systems that fail to make these strong guarantees. Serializable reads, for example, have the same scalability, throughput, and latency profile of an eventually-consistent system like Apache Cassandra, and can be scaled independently from writes.
There is no other publicly available system in the world like Fauna. We encourage you to give it a try, and to consider the implication of similar techniques in your own engineering work.
If you enjoyed our blog, and want to work on systems and challenges related to globally distributed systems, and serverless databases, Fauna is hiring!
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.